使用canal将数据同步到ROCKETMQ
概述
我们需要将数据从MYSQL写入到rocketmq。实现步骤如下:
安装canal.admin
修改配置
server:
port: 8849
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8 spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1 canal:
adminUser: admin
adminPasswd: admin
一般我们修改端口,和数据库的链接用户即可。
初始化数据库
创建数据库
启动admin
输入地址
http://localhost:8849/
输入 admin/123456 登录

看到这个界面说明 canal.admin 部署成功了。
canalserver 配置
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 # 管理控制台配置
canal.admin.manager = 127.0.0.1:8849
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
canal.admin.register.name = canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
# 默认的tcp 修改成 rocketMq
canal.serverMode = rocketMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true ## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60 # network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30 # binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false # binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation
canal.instance.get.ddl.isolation = false # parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256 # table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360 #################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml ##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid= canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8 ##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0 kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf" ##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
# 消息队列服务器配置
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag = ##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
启动canal server.
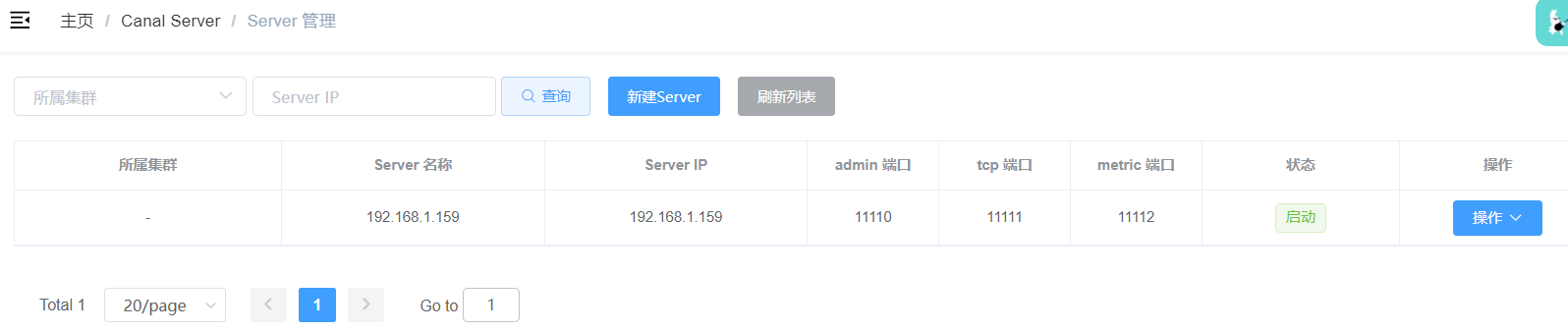
server 注册成功。
配置实例我们将数据同步到MQ
点击新实例按钮
比如我希望将 article 的表数据同步到 rocketmq中。
我们对配置做如下修改:
整个配置如下:
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0 # enable gtid use true/false
canal.instance.gtidon=false # 数据库地址
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid= # rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId= # table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid= # 用户名密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.defaultDatabaseName = cms_manage
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # 只选择文章表
canal.instance.filter.regex=.*\\.article
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # 创建一个文章的队列
canal.mq.topic=article
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
配置完成后,尝试在 表 article对数据进行增加,修改删除。
可以通过对列管理器看到。

写消息到队列后,我们就可以读取队列做我们需要处理的任务了。
使用canal将数据同步到ROCKETMQ的更多相关文章
- 【Canal】数据同步的终极解决方案,阿里巴巴开源的Canal框架当之无愧!!
写在前面 在当今互联网行业,尤其是现在分布式.微服务开发环境下,为了提高搜索效率,以及搜索的精准度,会大量使用Redis.Memcached等NoSQL数据库,也会使用大量的Solr.Elastics ...
- 阿里巴巴开源canal 工具数据同步异常CanalParseException:parse row data failed,column size is not match for table......
一.异常现象截图 二.解决方式: 1.背景 早期的canal版本(<=1.0.24),在处理表结构的DDL变更时采用了一种简单的策略,在内存里维护了一个当前数据库内表结构的镜像(通过desc ...
- canal数据同步
前面提到数据库缓存不一致的几种解决方案,但是在不同的场景下各有利弊,而今天我们使用的canal进行缓存与数据同步的方案是最好的,但是也有一个缺点,就是相对前面几种解决方案会引入阿里巴巴的canal组件 ...
- 开源数据同步神器——canal
前言 如今大型的IT系统中,都会使用分布式的方式,同时会有非常多的中间件,如redis.消息队列.大数据存储等,但是实际核心的数据存储依然是存储在数据库,作为使用最广泛的数据库,如何将mysql的数据 ...
- 基于canal的client-adapter数据同步必读指南
本文将介绍canal项目中client-adapter的使用,以及落地生产中需要考虑的可靠性.高可用与监控报警.(基于canal 1.1.4版本) canal作为mysql的实时数据订阅组件,实现了对 ...
- canal+mysql+kafka实时数据同步安装、配置
canal+mysql+kafka安装配置 概述 简介 canal译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费. 基于日志增量订阅和消费的业务包括 数 ...
- 实战!Spring Boot 整合 阿里开源中间件 Canal 实现数据增量同步!
大家好,我是不才陈某~ 数据同步一直是一个令人头疼的问题.在业务量小,场景不多,数据量不大的情况下我们可能会选择在项目中直接写一些定时任务手动处理数据,例如从多个表将数据查出来,再汇总处理,再插入到相 ...
- 基于Canal实现MySQL 8.0 数据库数据同步
前言 服务器说明 主机名称 操作系统 说明 192.168.11.82 Ubuntu 22.04 主库所在服务器 192.168.11.28 Oracle Linux Server 8.7 从库所在服 ...
- 数据同步canal客户端
1.增量订阅.消费设计 get/ack/rollback协议介绍: ① Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回 ...
- 数据同步canal服务端介绍
1.下载安装包 canal&github的地址,最权威的学习canal相关知识的地方 https://github.com/alibaba/canal 在下面的wiki列表中找到AdminGu ...
随机推荐
- GPUStack 0.2:开箱即用的分布式推理、CPU推理和调度策略
GPUStack 是一个专为运行大语言模型(LLM)设计的开源 GPU 集群管理器,旨在支持基于任何品牌的异构 GPU 构建统一管理的算力集群,无论这些 GPU 运行在 Apple Mac.Windo ...
- QT硬件异构计算
QT硬件异构计算 使用AI技术辅助生成 1 QT硬件异构计算概述 1.1 硬件异构计算概念 1.1.1 硬件异构计算概念 硬件异构计算概念 <QT硬件异构计算>正文 硬件异构计算概念 在进 ...
- [OI] 平衡树
1. 二叉查找树 二叉查找树的思想和优先队列比较像,都是把若干个数据按一定规则插到一棵树里,然后就可以维护特定的信息. 在优先队列的大根堆实现里,我们让每棵子树的根节点都大于它的儿子,这样就可以保证根 ...
- 14. 迭代器、生成器、模块与包、json模块
1.迭代器 1.1 迭代器介绍 迭代器是用来迭代取值的工具 每一次迭代得到的结果会作为下一次迭代的初始值,单纯的重复并不是迭代 # while循环实现迭代取值 a = [1, 2, 3, 4, 5, ...
- Qt构建cmake工程方法总结
由于工作需要,最近打算统一将所有C/C++项目都改成使用cmake编译.传统后台业务问题不大,但是有些牵涉到跨平台的Qt项目还是折腾了一阵.下面对这段时间的收获做一个总结,也希望帮助看到本文的朋友少走 ...
- 腾讯自研Git客户端,助力每个人都可以轻松使用Git
工具介绍 UGit是一款腾讯自研的Git客户端,为了让每个人都可以轻松使用Git,从而提高开发效率和团队协作的流畅性.支持工蜂MR/CR,工蜂议题管理,另外对于Git的原生特性有着深度支持. 支持的系 ...
- DWC3和XHCI的区别
DWC3(DesignWare USB 3.0 Controller)和XHCI(eXtensible Host Controller Interface)都是与USB控制器相关的技术,但它们的作用和 ...
- docker容器中启动tomcat应用
Dockerfile FROM tomcat:8.5.46-jdk8-openjdk-slim COPY ecs-console.war /usr/local/tomcat/webapps/ ENV ...
- 使用 Cursor 和 Devbox 快速开发基于 Rust 的 WASM 智能合约
本教程以一个智能合约(使用 NEAR 的一个官方 Fungible Tokens 来实现)的例子来介绍一下 Devbox 的强大功能,轻松构建环境,轻松发布. NEAR 是一个去中心化的应用平台,使用 ...
- manim边做边学--复数平面
所谓复数平面,就是一种二维坐标系统,用于几何表示复数的场景,其中横轴代表实部,纵轴代表虚部. 每个点对应一个唯一的复数,反之亦然,这种表示方法使得复数的加法.乘法等运算可以通过直观的图形变换来理解. ...