LDA——线性判别分析基本推导与实验
介绍与推导
LDA是线性判别分析的英文缩写,该方法旨在通过将多维的特征映射到一维来进行类别判断。映射的方式是将数值化的样本特征与一个同维度的向量做内积,即:
$y=w^Tx$
因此,建立模型的目标就是找到一个最优的向量,使映射到一维后的不同类别的样本之间“距离”尽可能大,而同类别的样本之间“距离”尽可能小,使分类尽可能准确。
具体来说,就是使映射后类内样本方差尽可能小,类间样本方差尽可能大。也就是(这里为二分类,多分类类似):
$ \begin{align*} &\quad \min\limits_w \left[\sum\limits_{x\in X_0}(w^Tx-w^T\mu_0)^2+\sum\limits_{x\in X_1}(w^Tx-w^T\mu_1)^2\right]\\ &=\min\limits_w w^T \left[\sum\limits_{x\in X_0}(x-\mu_0)(x-\mu_0)^T+\sum\limits_{x\in X_1}(x-\mu_1)(x-\mu_1)^T\right]w \\ &=\min\limits_w w^TS_ww \\ \end{align*} $
和
$ \begin{align*} &\quad \max\limits_w \left[(w^T\mu_0-\frac{w^T\mu_0+w^T\mu_1}{2})^2+(w^T\mu_1-\frac{w^T\mu_0+w^T\mu_1}{2})^2\right]\\ &=\max\limits_w \frac{1}{2}w^T(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw\\ &=\max\limits_w \frac{1}{2}w^TS_bw \\ \end{align*} $
因为自变量只有$w$,不一定二者都能同时达到最优,所以整合到一起取下式的最大值:
$J = \displaystyle \frac{w^TS_bw}{w^TS_ww}$
也就是:
$ \begin{align*} &\min\limits_w -w^TS_bw\\ &\text{s.t.}\,\, w^TS_ww = 1 \end{align*} $
因为$S_w$正定,$S_b$半正定,所以使用拉格朗日乘子法(点击链接),最终得到:
$w = S_w^{-1}(\mu_0-\mu_1)$
其中$S_w^{-1}$是$S_w$的伪逆。
实验
西瓜数据集
实验用数据集为西瓜数据集:

将数据填入Excel中后,在python中读取,然后使用处理好的数据计算出$w$,最后进行测试。
各个样本点、映射平面以及映射后的样本点如下图所示:

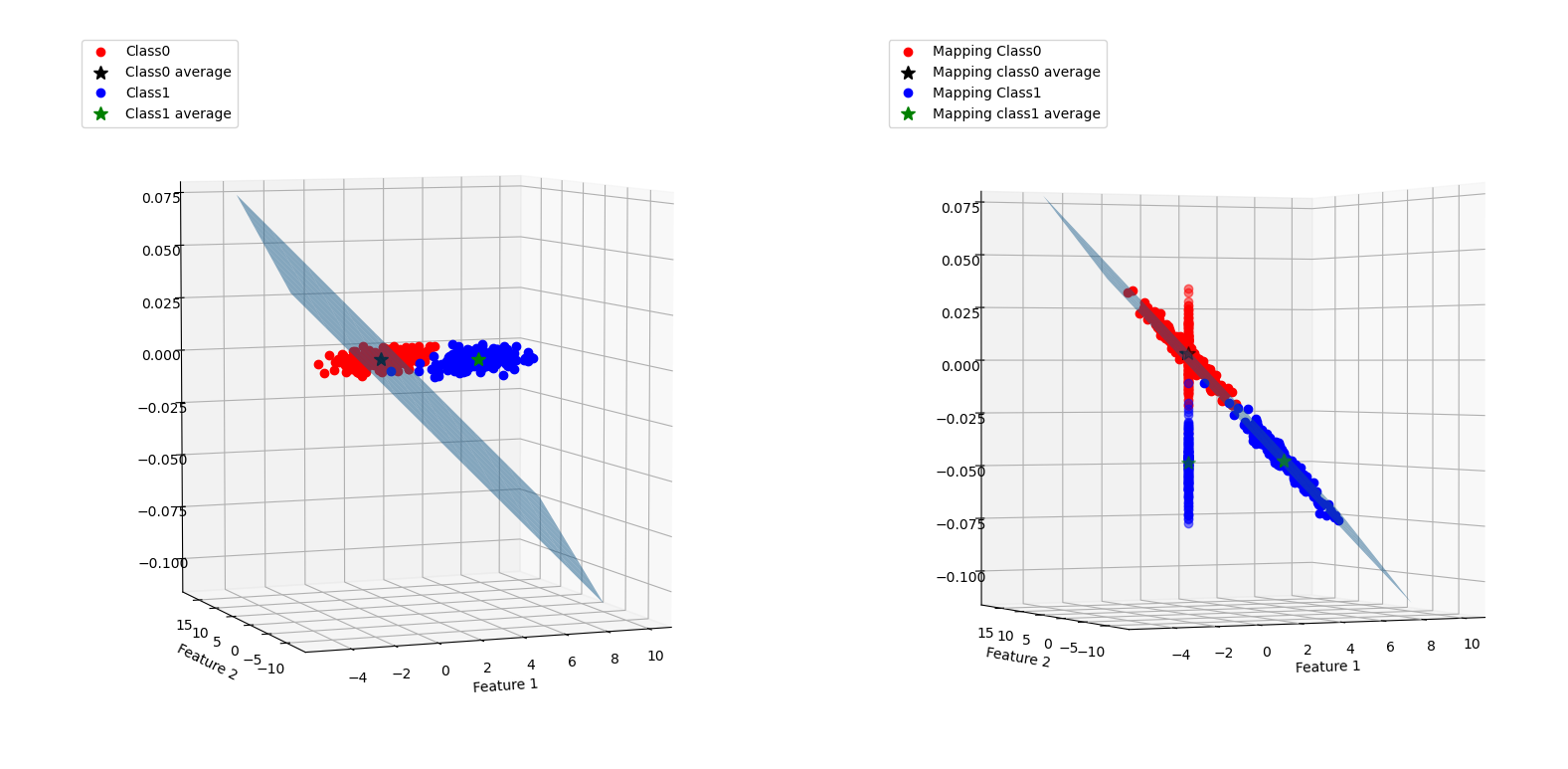
可以看到两类的样本点明显不是线性可分的,因此,不论如何选取一次的线性映射,都不可能将两类样本完全分开。而找到的映射平面将样本映射到一维后(即在右图的Z轴上),依然是很多不同类别的点穿插在一起。
因此,判别训练集的正确率较低:
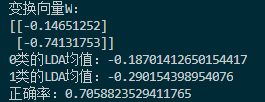
仅0.7。
线性数据集
为了测试LDA在线性可分特征数据集上的性能,以二维正态分布生成如下样本点:
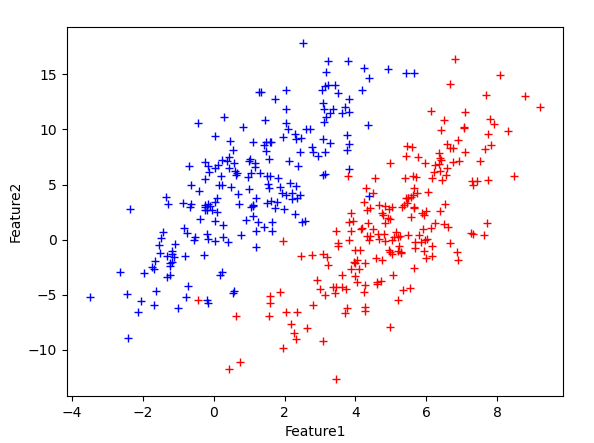
其中蓝色点均值为$[1,5]$,红色为$[5,1]$;两类样本的协方差矩阵都为:
$\left[\begin{matrix}1.4&1\\1&5\\\end{matrix}\right]$
映射图如下:
判断结果如下:
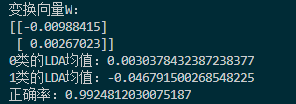
正确率提高到了0.99,可见LDA在线性可分数据上的性能还是不错的。
实验代码
LDA代码(数据输入data.xlsx中第一个表即可):
1 #%%
2 import matplotlib.pyplot as plt
3 import numpy as np
4 import xlrd
5
6 table = xlrd.open_workbook('test.xlsx').sheets()[0]#读取Excel数据
7 data = []
8 for i in range(1,table.nrows):#假设第一行是表头不读入
9 data.append(table.row_values(i))
10 class0 = []
11 class1 = []
12 #划分正反特征集,编号第一列,类别最后一列,特征在中间
13 for i in data:
14 if i[-1] == 0:
15 class0.append(i[1:-1])
16 else:
17 class1.append(i[1:-1])
18 data = np.array(data) #转为数字矩阵
19 class0 = np.array(class0) #特征都是行向量,组成矩阵
20 class1 = np.array(class1)
21
22 # %%
23 #计算相应类别特征的平均
24 n0 = len(class0)
25 n1 = len(class1)
26 miu0 = np.dot(np.ones([1,n0]),class0)/n0
27 miu1 = np.dot(np.ones([1,n1]),class1)/n1
28
29 #%%
30 #计算类内散度矩阵
31 s0 = class0 - miu0
32 s1 = class1 - miu1
33 Sw = np.dot(s0.transpose(),s0)+np.dot(s1.transpose(),s1)
34 W = np.dot(np.linalg.pinv(Sw),(miu0-miu1).transpose()) #计算W
35 #输出W、miu0和miu1在映射后的值
36 miu0_LDA = np.dot(miu0,W)
37 miu1_LDA = np.dot(miu1,W)
38 print("变换向量W:")
39 print(W)
40 print("0类的LDA均值:"+str(miu0_LDA[0,0]))
41 print("1类的LDA均值:"+str(miu1_LDA[0,0]))
42
43 #%%
44 #判断类别
45 c_discrim = np.dot(data[:,1:-1],W)
46 #统计正确率
47 right = 0
48 for i in range(len(data)):
49 if np.abs(miu0_LDA[0,0] - c_discrim[i]) < np.abs(miu1_LDA[0,0] - c_discrim[i]):
50 if data[i][-1] == 0:
51 right +=1
52 else:
53 if data[i][-1] == 1:
54 right +=1
55 print("正确率:"+str(right / len(data)))
56
57 #%%
58 #画图(仅适用于二维特征)
59 ##################图一
60 fig = plt.figure()
61 ax = fig.add_subplot(121,projection = '3d')
62 plt.xlabel("Feature 1")
63 plt.ylabel("Feature 2")
64 ax.plot(class0[:,0],class0[:,1],'o',label = 'Class0',color = "red") #0类
65 ax.plot([miu0[0,0]],[miu0[0,1]],'*',label = 'Class0 average',color = "black",markersize = 10) #0类平均
66 ax.plot(class1[:,0],class1[:,1],'o',label = 'Class1',color = "blue") #1类
67 ax.plot([miu1[0,0]],[miu1[0,1]],'*',label = 'Class1 average',color = "green",markersize = 10) #1类平均
68 #映射平面
69 t = np.linspace(-5,10,10)
70 X,Y = np.meshgrid(t,t)
71 ax.plot_surface(X,Y,X*W[0]+Y*W[1],alpha = 0.5)
72 ax.legend(loc = 'upper left')
73
74 ##################图二
75 ax = fig.add_subplot(122,projection = '3d')
76 plt.xlabel("Feature 1")
77 plt.ylabel("Feature 2")
78 ax.plot(class0[:,0],class0[:,1],np.dot(class0,W)[:,0],'o',label = 'Mapping Class0',color = "red") #0类映射
79 ax.plot([miu0[0,0]],[miu0[0,1]],np.dot(miu0[0],W),'*',label = 'Mapping class0 average',color = "black",markersize = 10) #0类平均映射
80 ax.plot(class1[:,0],class1[:,1],np.dot(class1,W)[:,0],'o',label = 'Mapping Class1',color = "blue") #1类映射
81 ax.plot([miu1[0,0]],[miu1[0,1]],np.dot(miu1[0],W),'*',label = 'Mapping class1 average',color = "green",markersize = 10) #1类平均映射
82 ax.plot(np.zeros([len(class0)]),np.zeros([len(class0)]),np.dot(class0,W)[:,0],'o',color = "red",alpha = 0.5) #0类映射值
83 ax.plot(np.zeros([len(class1)]),np.zeros([len(class1)]),np.dot(class1,W)[:,0],'o',color = "blue",alpha = 0.5) #1类映射值
84 ax.plot([np.zeros([1])],np.zeros([1]),np.dot(miu0[0],W),'*',color = "black",alpha = 0.5,markersize = 10) #0类平均映射值
85 ax.plot([np.zeros([1])],np.zeros([1]),np.dot(miu1[0],W),'*',color = "green",alpha = 0.5,markersize = 10) #1类平均映射值
86 #映射平面
87 X,Y = np.meshgrid(t,t)
88 ax.plot_surface(X,Y,X*W[0]+Y*W[1],alpha = 0.5)
89 ax.legend(loc = 'upper left')
90
91 plt.show()
生成线性数据集代码:
1 import openpyxl
2 import numpy as np
3 import matplotlib.pyplot as plt
4
5 sampleNum = 200
6
7 # 二维正态分布
8 mu = np.array([[1, 5]])
9 Sigma = np.array([[1.4, 1], [1, 5]])
10 s1 = np.dot(np.random.randn(sampleNum, 2), Sigma) + mu
11 plt.plot(s1[:,0],s1[:,1],'+',color='blue')
12
13 mu = np.array([[5, 1]])
14 Sigma = np.array([[1.4, 1], [1, 5]])
15 s2 = np.dot(np.random.randn(sampleNum, 2), Sigma) + mu
16 plt.plot(s2[:,0],s2[:,1],'+',color='red')
17 plt.xlabel('Feature1')
18 plt.ylabel('Feature2')
19
20 plt.show()
21 data = openpyxl.Workbook()
22 table = data.create_sheet('test')
23 table.cell(1,1,'id')
24 table.cell(1,2,'feature1')
25 table.cell(1,3,'feature2')
26 table.cell(1,4,'class')
27 for i in range(sampleNum):
28 table.cell(i+2,1,i+1)
29 table.cell(i+2,2,s1[i][0])
30 table.cell(i+2,3,s1[i][1])
31 table.cell(i+2,4,0)
32 for i in range(sampleNum):
33 table.cell(i+1+sampleNum,1,i+1)
34 table.cell(i+1+sampleNum,2,s2[i][0])
35 table.cell(i+1+sampleNum,3,s2[i][1])
36 table.cell(i+1+sampleNum,4,1)
37 data.remove(data['Sheet'])
38 data.save('test.xlsx')
LDA——线性判别分析基本推导与实验的更多相关文章
- PCA主成分分析 ICA独立成分分析 LDA线性判别分析 SVD性质
机器学习(8) -- 降维 核心思想:将数据沿方差最大方向投影,数据更易于区分 简而言之:PCA算法其表现形式是降维,同时也是一种特征融合算法. 对于正交属性空间(对2维空间即为直角坐标系)中的样本点 ...
- LDA线性判别分析
LDA线性判别分析 给定训练集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能的近,异类样例点尽可能的远,对新样本进行分类的时候,将新样本同样的投影,再根据投影得到的位置进行判断,这个新样本的 ...
- LDA线性判别分析原理及python应用(葡萄酒案例分析)
目录 线性判别分析(LDA)数据降维及案例实战 一.LDA是什么 二.计算散布矩阵 三.线性判别式及特征选择 四.样本数据降维投影 五.完整代码 结语 一.LDA是什么 LDA概念及与PCA区别 LD ...
- LDA 线性判别分析
LDA, Linear Discriminant Analysis,线性判别分析.注意与LDA(Latent Dirichlet Allocation,主题生成模型)的区别. 1.引入 上文介绍的PC ...
- LDA线性判别分析(转)
线性判别分析LDA详解 1 Linear Discriminant Analysis 相较于FLD(Fisher Linear Decriminant),LDA假设:1.样本数据服从正态分布,2 ...
- LDA(线性判别分析,Python实现)
源代码: #-*- coding: UTF-8 -*- from numpy import * import numpy def lda(c1,c2): #c1 第一类样本,每行是一个样本 #c2 第 ...
- 线性判别分析 LDA
点到判决面的距离 点\(x_0\)到决策面\(g(x)= w^Tx+w_0\)的距离:\(r={g(x)\over \|w\|}\) 广义线性判别函数 因任何非线性函数都可以通过级数展开转化为多项式函 ...
- LDA(Linear discriminate analysis)线性判别分析
LDA 线性判别分析与Fisher算法完全不同 LDA是基于最小错误贝叶斯决策规则的. 在EMG肌电信号分析中,... 未完待续:.....
- 机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题 ...
- 运用sklearn进行线性判别分析(LDA)代码实现
基于sklearn的线性判别分析(LDA)代码实现 一.前言及回顾 本文记录使用sklearn库实现有监督的数据降维技术——线性判别分析(LDA).在上一篇LDA线性判别分析原理及python应用(葡 ...
随机推荐
- 探索一下 Enum 优化
探索一下 Enum 优化 SV.Enums主要是探索如何让 enum 更高效 其中涉及的优化手段并非完全自创 很多内容参考于以下项目 NetEscapades.EnumGenerators FastE ...
- 神经网络之卷积篇:详解简单卷积网络示例(A simple convolution network example)
详解简单卷积网络示例 假设有一张图片,想做图片分类或图片识别,把这张图片输入定义为\(x\),然后辨别图片中有没有猫,用0或1表示,这是一个分类问题,来构建适用于这项任务的卷积神经网络.针对这个示例, ...
- 【YashanDB知识库】ycm托管数据库时,数据库非OM安装无法托管
问题现象 ps -ef | grep yas 查看无yasom和yasagent进程,且在{数据库安装目录}/om/{数据库名称}的目录下没有conf.data.log等目录,确定数据库不是用yasb ...
- Angular 18+ 高级教程 – Component 组件 の Dependency Injection & NodeInjector
前言 在 Dependency Injection 依赖注入 文章中,我们学习了 50% 的 Angular DI 知识,由于当时还不具备组件知识,所以我们无法完成另外 50% 的学习. 经过了几篇组 ...
- 从零开始搭建一个LoRaWAN基站
先说两句 SX1301/SX1302是semtech公司推出的基站端射频基带芯片,其与SX127x/SX126x的主要区别在于: 只是个基带芯片,使用时需要加射频前端(SX125x/SAW/...) ...
- 命令行gcc -v和g++ -v输出版本不一致
命令行gcc -v和g++ -v输出版本不一致 前言:本文初编辑于2024年1月30日 CSDN主页:https://blog.csdn.net/rvdgdsva 博客园主页:https://www. ...
- 三维医学图像数据扩充:flip and rotate
对于小数据量医学图像进行深度学习使,会由于数据量过小而过拟合.因此我们需要采用数据扩充方法,而flip和rotate又是经常用到的,这里做一个简单的实现. 输入为[batchsize,height, ...
- c#传统读取配置文件
using Microsoft.Extensions.Configuration; using Microsoft.Extensions.Configuration.Json; namespace C ...
- 小程序的image组件
mode属性:用来制定图片的裁剪和缩放模式:常用属性如下:
- 云原生周刊:Karmada 成为 CNCF 孵化项目 | 2023.12.25
开源项目推荐 kubernetes-reflector Reflector 是一个 Kubernetes 的插件,旨在监视资源(secrets 和 configmaps)的变化,并将这些变化反映到同一 ...