nodejs的简单爬虫
闲聊

看代码啦:
1.首先先安装node。
2.新建package.json:
在自己创建的一个工程目录下打开cmd ,在里面输入命令npm init
3.新建data和img文件夹
4.新建app.js
"use strict"; // 引入模块
var http = require('http');
var fs = require('fs');
var path = require('path');
var cheerio = require('cheerio'); // 爬虫的UR L信息
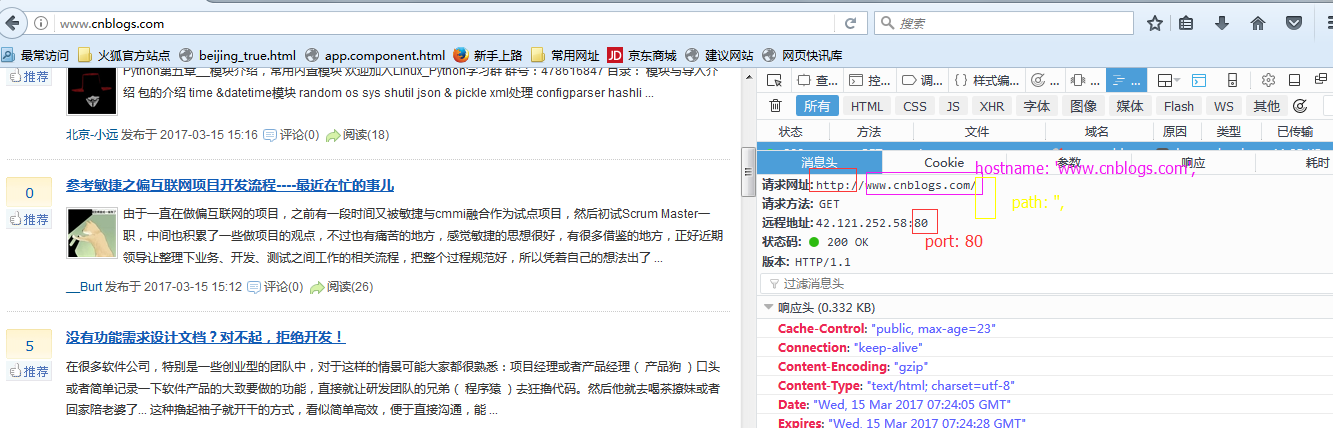
var opt = {
hostname: 'www.cnblogs.com',
path: '',
port: 80
}; // 创建http get请求
http.get(opt, function(res) {
var html = ''; // 保存抓取到的HTML源码
var blogs = []; // 保存解析HTML后的数据,即我们需要的电影信息 // 前面说过
// res 是 Class: http.IncomingMessage 的一个实例
// 而 http.IncomingMessage 实现了 stream.Readable 接口
// 所以 http.IncomingMessage 也有 stream.Readable 的事件和方法
// 比如 Event: 'data', Event: 'end', readable.setEncoding() 等 // 设置编码
res.setEncoding('utf-8'); // 抓取页面内容
res.on('data', function(chunk) {
html += chunk;
}); res.on('end', function() {
// 使用 cheerio 加载抓取到的HTML代码
// 然后就可以使用 jQuery 的方法了
// 比如获取某个class:$('.className')
// 这样就能获取所有这个class包含的内容
var $ = cheerio.load(html); // 解析页面
// 每篇文章都在 item class 中
$('#post_list .post_item .post_item_body').each(function() {
// 获取图片链接
var blog = {
title: $('.post_item_body .titlelnk', this).text(), // 获取文章标题
titleUrl: $('.post_item_body a', this).attr('href'), //文章链接地址
peopleUrl: $('.post_item_summary a', this).attr('href'), // 博客地址
peopleImg: $('.post_item_summary img', this).attr('src'),// 园友头像
intro: $('.post_item_summary', this).text(), // 获取文章简介
name: $('.post_item_foot .lightblue', this).text() // 获取文章简介
}; // 把所有文章放在一个数组里面
blogs.push(blog);
if (blog.peopleImg) {// 如果有图片则下载图片
downloadImg('img/', 'http:' + blog.peopleImg);
}
}); // 保存抓取到的文章数据
saveData('data/data.json', blogs);
});
}).on('error', function(err) {
console.log(err);
}); /**
* 保存数据到本地
*
* @param {string} path 保存数据的文件
* @param {array} blogs 文章信息数组
*/
function saveData(path, blogs) {
// 调用 fs.writeFile 方法保存数据到本地
fs.writeFile(path, JSON.stringify(blogs, null, 4), function(err) {
if (err) {
return console.log(err);
}
console.log('Data saved');
});
} /**
* 下载图片
*
* @param {string} imgDir 存放图片的文件夹
* @param {string} url 图片的URL地址
*/
function downloadImg(imgDir, url) {
http.get(url, function(res) {
var data = ''; res.setEncoding('binary'); res.on('data', function(chunk) {
data += chunk;
}); res.on('end', function() {
// 调用 fs.writeFile 方法保存图片到本地
fs.writeFile(imgDir + path.basename(url), data, 'binary',
function(err) {
if (err) {
return console.log(err);
}
console.log('Image downloaded: ', path.basename(url));
});
});
}).on('error', function(err) {
console.log(err);
});
}
5.打开cmd执行 node app.js
然后看data文件夹下会生成data.json文件,img文件夹下会生成许多图片。
补充
// 爬虫的UR L信息
var opt = {
hostname: 'www.cnblogs.com',
path: '',
port: 80
};
nodejs的简单爬虫的更多相关文章
- nodejs实现简单爬虫
nodejs结合cheerio实现简单爬虫 let cheerio = require("cheerio"), fs = require("fs"), util ...
- 用nodejs实现简单爬虫
前言 本喵最近工作中需要使用node,并也想晋升为全栈工程师,所以开始了node学习之旅,在学习过程中, 我会总结一些实用的例子,做成博文和视频教程,以实例形式来理解体会node的用法,所以跟小猫 ...
- NodeJS简单爬虫
NodeJS简单爬虫 最近一直在追火星的一本书,然后每次都要去网站看,感觉很麻烦,于是,想起用爬虫爬取章节,务实派,说干就干! 爬取思路 1.该网站的页面呈现出一定的规律 2.使用NodeJS的req ...
- 一次使用NodeJS实现网页爬虫记
前言 几个月之前,有同事找我要PHP CI框架写的OA系统.他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP. 我上QeePHP官网,发现官方网站打不开了,GOOGL ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- 简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制 文章地址:http://www.cnblogs.com/likeli/p/4730709.html 好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
随机推荐
- 如何利用express新建项目(上)
如何利用express新建项目(上) 摘要 这篇文章将讲解了如何快速利用express新建项目 一.express4.x的安装 1. npm install -g express 2. npm ins ...
- Graphql入门
Graphql入门 GraphQL是一个查询语言,由Facebook开发,用于替换RESTful API.服务端可以用任何的语言实现.具体的你可以查看Facebook关于GraphQL的文档和各种语言 ...
- .Net学习难点讨论系列17 - 线程本地变量的使用
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- Unity随手记
过年11天假期,带娃带了7天,吃吃喝喝.也看了点书,<射雕英雄传>(书)看了一半,还有就是在看<unity官方案例精讲>这本. 随手记一些自觉有价值或者有意思的点. 1. 对脚 ...
- ArcGIS制图技巧系列(1)还原真实的植被
ArcGIS制图技巧系列(1)还原真实的植被 by 李远祥 在GIS数据中,植被一般都是面装要素的形式存在.很多人在使用植被渲染的时候,一般会采用填充符号去渲染.而在ArcGIS中,填充符号要么就是纯 ...
- 面试之Java知识整理
1.面向对象都有哪些特性 继承.封装.多态性.抽象 2.Java中实现多态的机制是什么? 继承与接口 3.Java中异常分为哪些种类 3.1按照异常需要处理的时机分为编译时异常(CheckedExce ...
- Win8下,以管理员身份启动VS项目
之前一直是先以管理员身份启动VS,然后再打开项目的,比较麻烦,找了好久,总算有一个处理方案了 在Windows7下 通常使用修改属性的方式:在任意快捷方式上右击,选择属性,选择高级,选择以管理员身份启 ...
- ASP.NET MVC5 实现分页查询
对于大量数据的查询和展示使用分页是一种不错的选择,这篇文章简要介绍下自己实现分页查询的思路. 分页需要三个变量:数据总量.每页显示的数据条数.当前页码. //数据总量 int dataCount; / ...
- 给ubuntu安装VNC远程桌面
(只有背景,没有菜单栏问题没有解决)Virtual Network Computing(VNC)是进行远程桌面控制的一个软件.客户端的键盘输入和鼠标操作通过网络传输到远程服务器,控制服务器的操作.服务 ...
- php查询,多条件查询
单条件查询: 1.先要有一张表,显示出表中的数据: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ...