Java8 新特性之Stream API
1. Stream 概述
- Stream 是Java8中处理集合的关键抽象概念,可以对集合执行非常复杂的查找,过滤和映射数据等操作;
- 使用 Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询;
- 可以使用 Stream API 来并行执行操作;
- Stream API 提供了一种高效且易于使用的处理数据的方式;
1.1 什么是 Stream
- Stream(流)是数据渠道,用于操作数据源(集合,数组等)所生成的元素序列;
"集合讲的是数据,流讲的是计算!" - 注意:
- Stream 自己不会存储元素;
- Stream 不会改变源对象; 相反,它们会返回一个持有结果的新Stream;
- Stream 操作是延迟执行的; 这意味着它们会等到需要结果的时候,才执行;
1.2 Stream 操作的三个步骤
- 创建 Stream
- 一个数据源(如: 集合,数组),获取一个流;
- 中间操作
- 一个中间操作链,对数据源的数据进行处理;
- 终止操作(终端操作)
- 一个终止操作,执行中间操作链,并产生结果;
// 测试类
public class TestStreamAPI{
// 创建 Stream
@Test
public void test(){
// 1. 可以通过 Collection 集合提供的 stream() 或 parallelStream()
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream();
// 2. 可以通过 Arrays 中的静态方法 stream() 获取数组流
Employee[] emps = new Employee[10];
Stream<Employee> stream2 = Arrays.stream(emps);
// 3. 通过 Stream 类中的静态方法 of()
Stream<String> stream3 = Stream.of("aa","bb","cc");
// 4. 创建无限流
// 迭代
Stream<Integer> stream4 = Stream.iterate(0,(x) -> x+2);
// 生成
Stream.generate(() -> Math.random())
.limit(5)
.forEach(System.out::println);
}
// 中间操作
// 多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则,中间操作不会执行任何的处理!
// 而在终止操作时,一次性全部处理,称为"惰性求值"
// 中间操作包括: 筛选与切片, 映射, 排序,
/*
* 筛选与切片
* filter(): 接收 Lambda, 从流中排除某些元素;
* limit(): 截断流,使其元素不超过给定数量;
* skip(n): 跳过元素,返回一个扔掉了前 n 个元素的流; 若流中元素不足n个,返回一个空流;与 limit(n) 互补;
* distinct(): 筛选,通过流所生成元素的 hashCode() 和 equals() 取出重复元素
*/
List<Employee> employees = Arrays.asList(
new Employee("张三",16,1000),
new Employee("李四",22,2000),
new Employee("熊大",25,1300),
new Employee("熊二",32,1200),
new Employee("赵六",43,3200)
);
@Test
public void test2(){
// 筛选与切片
// 中间操作: 不会执行任何操作
Stream<Employee> stream = employees.stream()
.filter((e) -> e.getAge() > 26);
// 终止操作: 一次性执行全部内容,即"惰性求值"
stream.forEach(System.out:println);
}
/*
* 映射
* map(): 接收 Lambda, 将元素转换成其他形式或提取信息,接受一个函数作为参数; 该函数会被应用到每个
* 元素上,并将其映射成一个新的元素;
* flatMap(): 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流;
*/
@Test
public void test3(){
List<String> list = Arrays.asList("aaa","bbb","ccc","ddd");
// 将 list 集合中的元素转换成大写
list.stream()
.map((str) -> str.toUpperCase())
.forEach(System.out::println);
// 获取employees中的姓名
employees.stream()
.map(Employee::getName)
.forEach(System.out::println);
// flatMap() 使用之前:
Stream<Stream<Character>> stream = list.stream()
.map(TestStreamAPI::filterCharscter);
stream.forEach((sm) ->{
sm.forEach(System.out::println);
});
// flatMap()
list.stream()
.flatMap(TestStreamAPI::filterCharacter)
.forEach(System.out::println);
}
public static Stream<Character> filterCharacter(String str){
List<Character> list = new ArrayList<>();
for(Character ch : str.toCharArray()){
list.add(ch);
}
return list.stream();
}
/*
* 排序
* sorted(): 自然排序(Comparable)
* sorted(Comparator com): 定制排序 (Comparator)
*/
List<String> list = Arrays.asList("bbb","zzz","yyy","ccc","sss");
list.stream()
.sorted()
.forEach(System.out::println);
// 员工排序
employees.stream()
.sorted((e1,e2) -> {
if(e1.getAge().equals(e2.getAge())){
return e1.getName().compareTo(e2.getNme());
}else{
return e1.getAge().compareTo(e2.getAge());
}
}).forEach(System.out::println);
// 终止操作(终端操作)
// 终止操作包括: 查找和匹配, 归约, 收集
/*
* 查找和匹配
* allMatch: 检查是否匹配所有元素
* anyMatch: 检查是否至少匹配一个元素
* noneMatch: 检查是否都不匹配
* findFirst: 返回第一个元素
* findAny: 返回当前流中的任意元素
* count: 返回流中元素的总个数
* max: 返回流中最大值
* min: 返回流中最小值
*/
List<Employee> employees = Arrays.asList(
new Employee("张三",16,1000,Status.FREE),
new Employee("李四",22,2000,Status.BUSY),
new Employee("熊大",25,1300,Status.VACATION),
new Employee("熊二",32,1200,Status.FREE),
new Employee("赵六",43,3200,Stutus.BUSY)
);
// 备注: 其中Status为枚举类型,共有:FREE(空闲),BUSY(忙碌),VACATION(休假)三种状态
boolean b1 = employees.stream()
.allMatch((e) -> e.getStatus().equals(Status.BUSY));
System.out.println(b1);
// 首先,按照工资排序,然后,获取第一个员工
Optional<Employee> op = employees.stream()
.sorted((e1,e2) -> Double.compare(e1.getSalary(),e2.getSalary()))
.findFirst();
System.out.println(op.get());
/*
* 归约
* reduce(T identity, BinaryOperator) / reduce(BinaryOperator)
* 可以将流中元素反复结合起来,得到一个值; 其中 第一个参数identity,表示起始值
*/
// 需求: 将list集合中的元素相加
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum = list.stream()
.reduce(0,(x,y) -> x+y);
System.out.println(sum);
// 获取员工工资的总和
Optional<Double> op = employees.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println(op.get());
/*
* 收集
* collect: 将流转换为其他形式,接收一个Collector 接口的实现,用于给 Stream 中元素做汇总的方法
* Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到 List, Set, Map)
* Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例;
*/
// 需求: 将员工中的名字收集到 list 集合
List<String> list = employees.stream()
.map(Employee:getName)
.collect(Collectors.toList());
list.forEach(System.out::println);
// 将员工姓名收集到 HashSet 中
HashSet<String> hset = employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));
// 员工总人数
Long count = employees.stream()
.collect(Colletors.counting());
System.out.println(count);
// 工资平均值
Double avg = employees.stream()
.collect(Collectors.averagingDouble(Employee::getSalary));
System.out.println(avg);
// 工资总和
Double sum = employees.stream()
.collect(Collectors.summingDouble(Employee::getSalary));
System.out.println(sum);
// 按照Status进行分组
Map<Status, List<Employee>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
System.out.println(map);
// 分区(满足条件的一个区,不满足条件的在另一个区)
Map<Boolean, List<Employee>> map = employees.stream()
.collect(Collectors.partitioningBy((e) -> e.getSalary() > 1700));
System.out.println(map);
DoubleSummaryStatistics dss = employees.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary));
System.out.println(dss.getSum());
System.out.println(dss.getAverage());
System.out.println(dss.getMax());
// 连接字符串
String str = employees.stream()
.map(Employee::getName)
.collect(Collectors.joining(","));
System.out.println(str);
}
2. 并行流
- 并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流;
- Java8 中将并行进行了优化,我们可以很容易的对数据进行并行操作;Stream API 可以声明性地通过
parallel()
与sequential()在并行流与顺序流之间进行切换; - Fork/Join 框架: 就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将
一个个的小任务运算的结果进行 join 汇总;
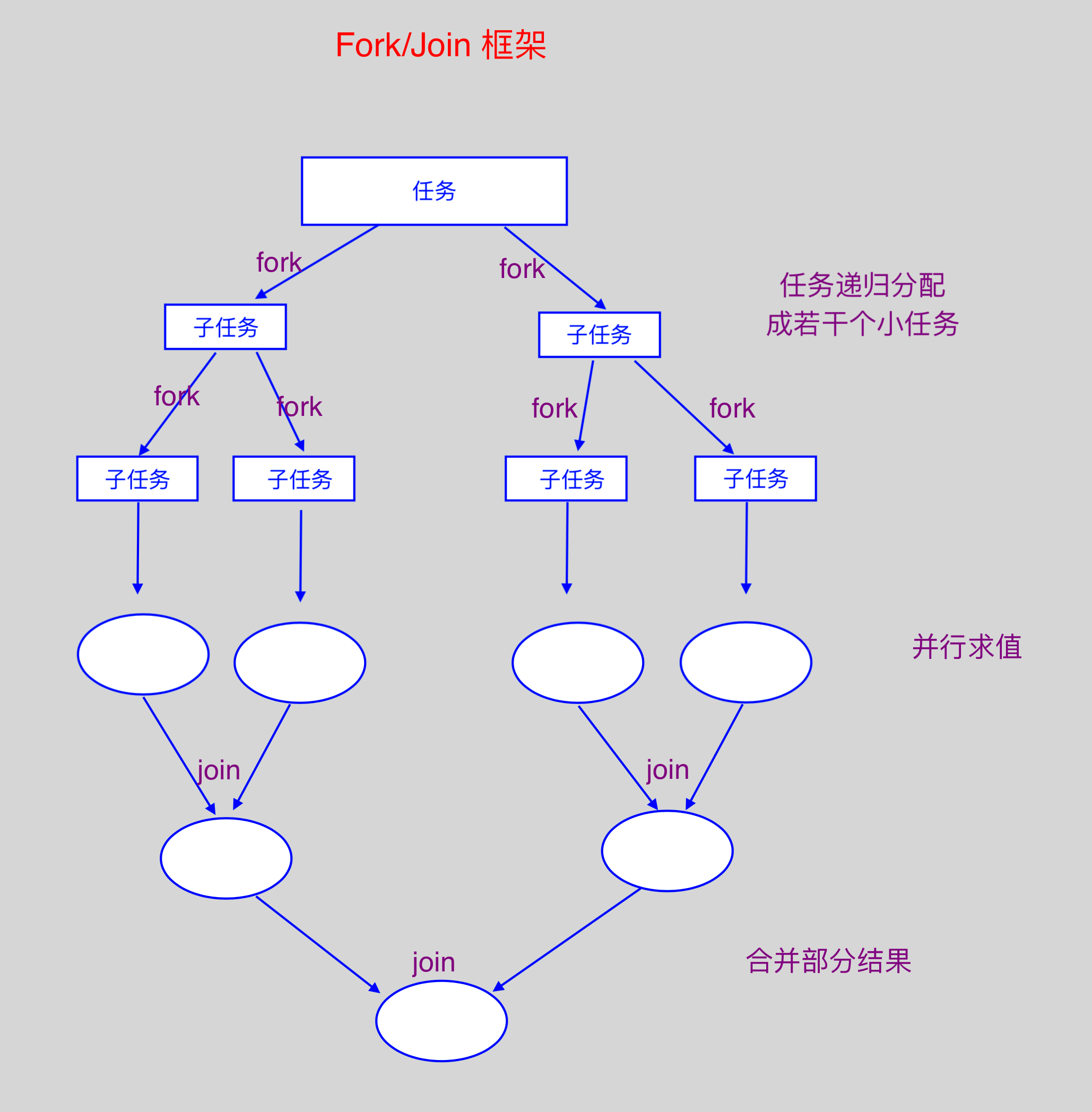
// java8 并行流
// 并行流底层依赖 Fork/Join 框架
// 需求: 计算1000亿的和
public class TestForkJoin{
@Test
public void test(){
LongStream.rangeClosed(0,100000000000L)
.parallel()
.reduce(0, Long::sum);
}
}
3. Optional 类
Optional<T>类(java.util.Optional)是一个容器类,代表一个值存在或不存在,原来用null表示一个值不存
在,现在Optional可以更好的表达这个概念,而且可以避免空指针异常;- 常用方法:
Optional.of(T t): 创建一个 Optional 实例;Optional.empty(): 创建一个空的 Optional 实例;Optional.ofNullable(T t): 若 t 不为null,创建 Optional 实例; 否则,创建空实例;isPresent(): 判断是否包含值;orElse(T t): 如果调用对象包含值,返回该值,否则,返回t;orElseGet(Supplier s): 如果调用对象包含值,返回该值; 否则,返回 s 获取的值;map(Function f): 如果有值,就对其处理,并返回处理后的Optional; 否则,返回Optional.empty();flatMap(Function mapper): 与map类似,要求返回值必须是Optional;
// 测试类
public class TestOptional{
@Test
public void test(){
Optional<Employee> op = Optional.of(new Employee("张三",13,2000));
Employee emp = op.get();
System.out.println(emp);
}
}
参考资料
Java8 新特性之Stream API的更多相关文章
- 【Java8新特性】Stream API有哪些中间操作?看完你也可以吊打面试官!!
写在前面 在上一篇<[Java8新特性]面试官问我:Java8中创建Stream流有哪几种方式?>中,一名读者去面试被面试官暴虐!归根结底,那哥儿们还是对Java8的新特性不是很了解呀!那 ...
- Java8 新特性 Lambda & Stream API
目录 Lambda & Stream API 1 Lambda表达式 1.1 为什么要使用lambda表达式 1.2 Lambda表达式语法 1.3 函数式接口 1.3.1 什么是函数式接口? ...
- 乐字节-Java8新特性之Stream流(上)
上一篇文章,小乐给大家介绍了<Java8新特性之方法引用>,下面接下来小乐将会给大家介绍Java8新特性之Stream,称之为流,本篇文章为上半部分. 1.什么是流? Java Se中对于 ...
- 乐字节-Java8新特性之Date API
上一篇文章,小乐给大家带来了Java8新特性之Optional,接下来本文将会给大家介绍Java8新特性之Date API 前言: Java 8通过发布新的Date-Time API来进一步加强对日期 ...
- 【Java8新特性】- Stream流
Java8新特性 - Stream流的应用 生命不息,写作不止 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放吧德德 分享学习心得,欢迎指正,大家一起学习成长! ...
- Java8 新特性 Data Time API
Java8新的日期类型 在Java8以前,Date日期API对我们非常的不友好,它无法表示日期,只能以毫秒的精试来表示时间,并且可以修改,他的线程还不是安全的.所以Java8中引入了全新的日期和时间A ...
- java8 新特性入门 stream/lambda
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利.高效的聚合操作(aggregate operation),或者大批量数据操作 (b ...
- Java8新特性之Stream
原文链接:http://ifeve.com/stream/ Java8初体验(二)Stream语法详解 感谢同事[天锦]的投稿.投稿请联系 tengfei@ifeve.com上篇文章Java8初体验( ...
- 【Java8新特性】Stream(分类+案例)
一.Stream概述 什么是Stream? Stream是Java8引入的全新概念,它用来处理集合中的数据,可以让你以一种声明的方式处理数据. Stream 使用一种类似用 SQL 语句从数据库查询数 ...
随机推荐
- dp之多重背包poj2392
题意:有k种石头,高为hi,在不超过ai的高度下,这种石头可以放置,有ci种这个石头,求这些石头所能放置的最高高度......... 思路:以往的什么硬币种数,最大硬币数之类的,他们的硬币都已经是排好 ...
- Spring的AOP简单理解
最近在研究spring的AOP,翻译出来的意思是面向切面. 总结如下: 所谓AOP就是将分散在各个方法处的公共代码提取到一处, 并通过类似拦截器的机制实现代码的动态整合.可以简单地想象成, 在某个方法 ...
- windows下端口占用解决方法-查看和杀死占用端口进程
在Windows下启动程序时有时会遇到端口被占用的情况,由于一个端口同时只能运行一个进程,所以要想启动新的程序就要先把占用该端口的进程给kill掉,具体的命令分为以下三步, 以杀死占用了80端口的进程 ...
- jQuery开发中容易忽视的错误
1.引用jQuery库文件的<script>标签,必须放在引用自定义脚本文件的<script>标签之前,否则,就会发生找不到对象:最好在<head>元素中,把引入样 ...
- MyBatis-Spring-Boot 使用总结
接 MyBatis-Spring 使用总结 . mybatis开发团队为Spring Boot 提供了 MyBatis-Spring-Boot-Starter . 首先,MyBatis-Sprin ...
- hashSet的底层是数组,其查询效率非常高
如果偷懒,没有设定equals(),就会造成返回hashCode虽然结果相同,但在程序执行的过程中会多次地调用equals(),从而影响程序执行的效率. 我们要保证相同对象的返回的hashCode一定 ...
- php -- 魔术方法 之 自动加载:__autoload()
自动加载类 背景: 很多开发者写面向对象的应用程序时对每个类的定义建立一个 PHP 源文件.一个很大的烦恼是不得不在每个脚本开头写一个长长的包含文件列表(每个类一个文件). 在 PHP 5 中,不再需 ...
- digitalocean --- How To Install Apache Tomcat 8 on Ubuntu 16.04
https://www.digitalocean.com/community/tutorials/how-to-install-apache-tomcat-8-on-ubuntu-16-04 Intr ...
- 【代码备份】pocs.m
超分辨率算法代码 POCS算法,凸集投影法. pocs.m,没有调用的代码,没看懂..只有这个函数..抱歉. function y = pocs(s,delta_est,factor) % POCS ...
- jboss eap 6.4 部署 从weblogic迁移
从weblogic10.3像jboss 6.4项目迁移,遇到的一些问题: 因为使用weblogic可以自定义公共的war包库,在使用jboss中,也采取项目依赖公共库的方式: 1.jboss中使用公共 ...