Hadoop HA 高可用集群搭建
一、首先配置集群信息
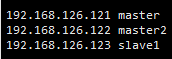
vi /etc/hosts
二、安装zookeeper
1、解压至/usr/hadoop/下
tar -zxvf zookeeper-3.4..tar.gz -C /usr/hadoop/
2、进入/usr/hadoop/zookeeper-3.4.10/conf目录,将zoo_sample.cfg 复制为 zoo.cfg
cp /usr/hadoop/zookeeper-3.4./conf/zoo_sample.cfg /usr/hadoop/zookeeper-3.4./conf/zoo.cfg
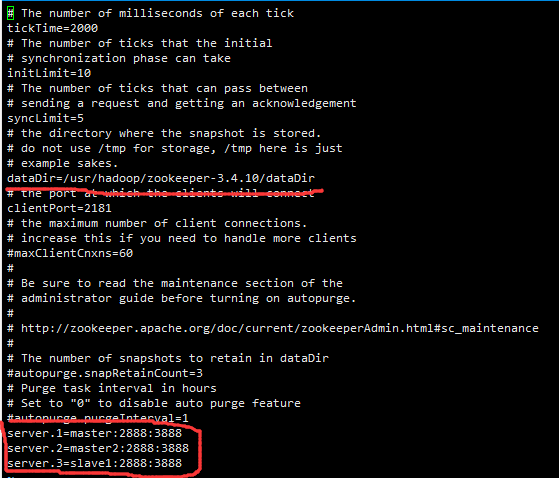
3、编辑zoo.cfg
4、新建dataDir目录
mkdir /usr/hadoop/zookeeper-3.4./dataDir/
5、向dataDir目录写入myid,mater为1,master2为2,slave1为3,对应着zoo.cfg的server.?
echo > /usr/hadoop/zookeeper-3.4./dataDir/myid
6、将整个文件夹考入其他主机
scp -r /usr/hadoop/zookeeper-3.4./ master2:/usr/hadoop/
scp -r /usr/hadoop/zookeeper-3.4./ slave1:/usr/hadoop/
7、修改myid
echo > /usr/hadoop/zookeeper-3.4./dataDir/myid echo > /usr/hadoop/zookeeper-3.4./dataDir/myid
三、安装hadoop
1、修改hadoo-env.sh yarn-env.sh mapred-env.sh

上面是我的java 路径,改为你自己的
2、修改core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration> <property><!--hdfs namenode集群访问地址-->
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,master2:2181,slave1:2181</value>
</property>
<property><!--HA模式下 fsimage 存储位置、tmp数据-->
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/haData</value>
</property> </configuration>
3、修改hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration> <!--HA-->
<property><!--hdfs namenode集群别名,与core-site.xml中一致 -->
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property><!-- namenodes下面有两个NameNode,分别是nn1,nn2 -->
<name>dfs.ha.namenodes.ns1</name>
<value>master,master2</value>
</property>
<property><!-- nn1的RPC通信地址 -->
<name>dfs.namenode.rpc-address.ns1.master</name>
<value>master:9000</value>
</property>
<property><!-- nn1的http通信地址 -->
<name>dfs.namenode.http-address.ns1.master</name>
<value>master:50070</value>
</property>
<property><!-- nn2的RPC通信地址 -->
<name>dfs.namenode.rpc-address.ns1.master2</name>
<value>master2:9000</value>
</property>
<property><!-- nn2的http通信地址 -->
<name>dfs.namenode.http-address.ns1.master2</name>
<value>master2:50070</value>
</property>
<property><!-- 配置JournalNode组的访问地址,格式qjournal://host:port/journalId。 journalId需要与“nameserviceID”一致 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;master2:8485;slave1:8485/ns1</value>
</property>
<property><!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<name>dfs.journalnode.edits.dir</name>
<value>/usr/hadoop/hadoop-2.8.5/haData/journalData</value>
</property>
<property><!-- 启用ZKFC,NameNode自动切换功能 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property><!-- NameNode自动切换配置失败后的解决方案 -->
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property><!-- Fecing隔离机制指定,多个方案间换行分割 -->
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property><!-- sshfence隔离机制时需要ssh免登陆 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property><!-- 配置sshfence隔离机制超时时间 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property> <property><!--指定 fsimage 元数据的存储位置-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/haData/dfs/name</value>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.8.5/haData/dfs/data</value>
</property> </configuration>
4、修改mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property> </configuration>
5、修改yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration> <property><!-- 启用YARN HA -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property><!-- 指定YARN cluster id -->
<name>yarn.resourcemanager.cluster-id</name>
<value>yrmc1</value>
</property>
<property><!-- 指定ResourceManager的名字 -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property><!-- 分别指定ResourceManager的地址 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,master2:2181,slave1:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property> <property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property> <!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property> </configuration>
6、修改slaves
7、免密配置authorized_keys
(1)最好的免密配置就是在克隆之前免密自己 ,把自己的公钥放进authorized_keys里,这样以后克隆多台都不需要配置免密
(2)其次
ssh-keygen
一路回车
ssh-copy-id master2
ssh-copy-id slave1
8、拷贝hadoop到其他机器
scp -r /usr/hadoop/hadoop-2.8.5/ master2:/usr/hadoop/
scp -r /usr/hadoop/hadoop-2.8.5/ slave1:/usr/hadoop/
四、启动集群(第一次顺序必须严格执行)
1、为了方便起见将环境变量配置如下:
export JAVA_HOME=/usr/java/jdk1..0_131
export JRE_HOME=/usr/java/jdk1..0_131/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export HADOOP_HOME=/usr/hadoop/hadoop-2.8.
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export ZOOKEEPER_HOME=/usr/hadoop/zookeeper-3.4.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
2、启动zookeeper集群
在三台机器上全部启动
zkServer.sh start
查看三台机器选举情况
zkServer.sh status
一台loader,其余两天为flower ,其它情况为错,重新配置



3、在三台机器上启动 journalnode
hadoop-daemon.sh start journalnode
查看进程,如没有进程将不能格式化
4、在master上进行格式化,状态为0为成功
不是第一次装Hadoop的需要把name 、data 删除 ,否则将启动不了进程
hdfs namenode -format
5、在master上单独启动namenode
hadoop-daemon.sh start namenode
6、在master2上同步master,状态为0成功
hdfs namenode -bootstrapStandby
7、关闭master上namenode
hadoop-daemon.sh stop namenode
8、在master上格式化ZK,格式化成功标志为,在任意一台登陆zkCli 查看 ls / 会有 hadoop ha 目录
hdfs zkfc -formatZK
9、在master上启动集群
start-dfs.sh
10、启动yarn集群
start-yarn.sh
*以后启动顺序,先启动zookeeper集群,然后在master上执行 start-all.sh 即可
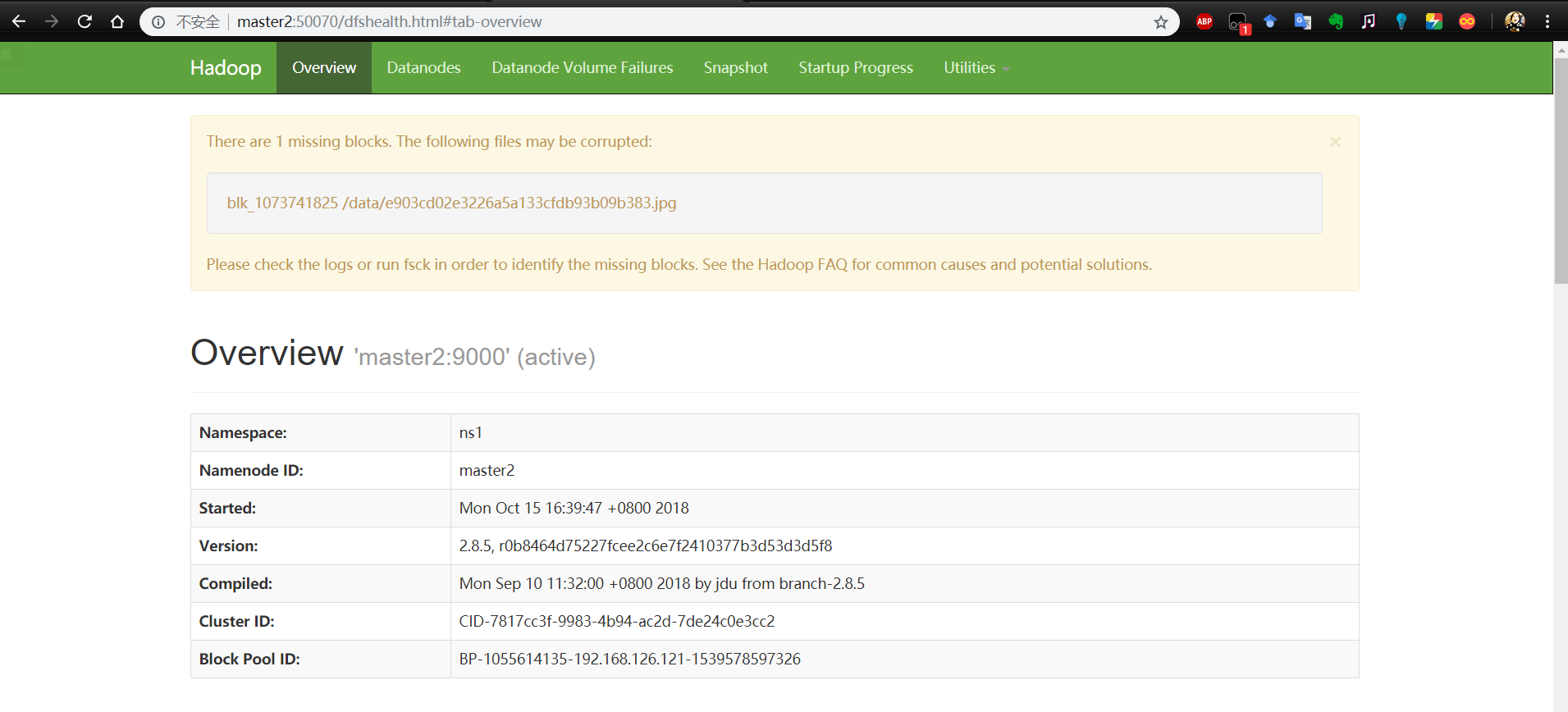
五、查看状态
在浏览器上访问
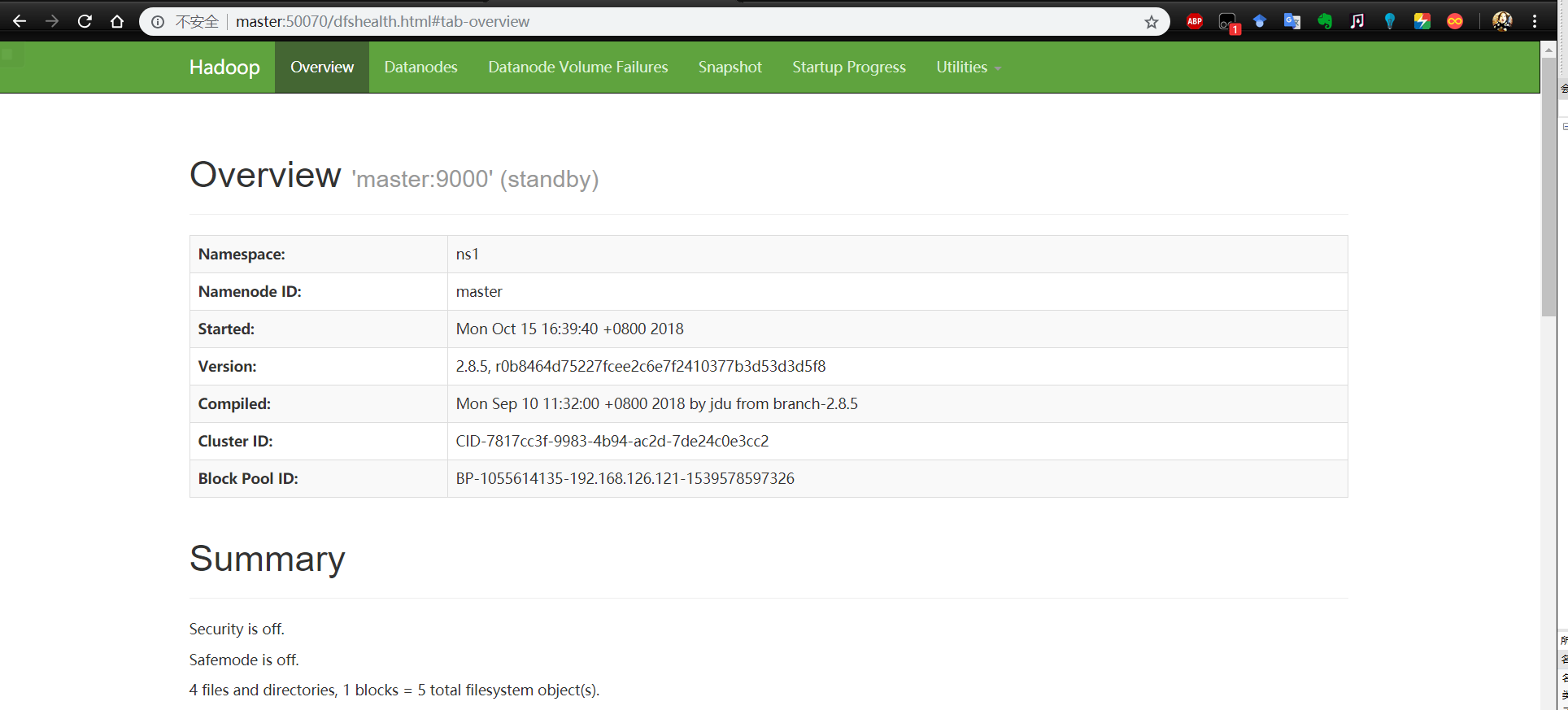
Hadoop HA 高可用集群搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- Hadoop HA 高可用集群的搭建
hadoop部署服务器 系统 主机名 IP centos6.9 hadoop01 192.168.72.21 centos6.9 hadoop02 192.168.72.22 centos6.9 ha ...
- HDFS-HA高可用集群搭建
HA高可用集群搭建 1.总体集群规划 在hadoop102.hadoop103和hadoop104三个节点上部署Zookeeper. hadoop102 hadoop103 hadoop104 Nam ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
随机推荐
- TPS和事务响应时间的关系、计算公式 (转)
例子:一个高速路有10个入口,每个入口每秒钟只能进1辆车1.请问1秒钟最多能进几辆车? TPS=102.每辆车需要多长时间进行响应? reponse time = 13.改成20辆车,每秒能进 ...
- leetcode Ch5-Linked List
一. 1. Remove Duplicates from Sorted List II class Solution { public: ListNode* deleteDuplicates(List ...
- Python 解决写入csv中间隔一行空行问题
转载解决写入csv中间隔一行空行问题 写入csv: with open(birth_weight_file,'w') as f: writer=csv.writer(f) writer.writero ...
- 微信 公众号 小程序 授权 unionid 用户信息 实验总结
-*-*-*-*-*-*-*-*-*--*-*-*-1.小程序通过code获取用户openid的接口,如果用户曾经授权并未过期,或者用户关注过同主体的公众号,会带回unionID,但没有用户头像等信息 ...
- December 27th 2016 Week 53rd Tuesday
A journey of one thousand miles begins with one step. 千里之行始于足下. No matter how slowly you walk, as lo ...
- codeforces 407D Largest Submatrix 3
codeforces 407D Largest Submatrix 3 题意 找出最大子矩阵,须满足矩阵内的元素互不相等. 题解 官方做法 http://codeforces.com/blog/ent ...
- Linux基础入门 - 1
第一节 Linux简介 Linux 就是一个操作系统,也就是系统调用和内核那两层,Linux 本身只是操作系统的内核(内核是使其他程序能够运行的基础.它实现了多任务和硬件管理,用户或者系统管理员交互运 ...
- GET POST 传值与接收案例
第一种:GET传递 前台 ajax GET 传递 :即在请求的地址后面加上参数,URL地址长度有显示,安全性低 后台接收:Request.QueryString[“参数名字”]! 例如: fu ...
- Hive安装报错
安装好hive后在bin路径下输入hive报错: [ERROR] Terminal initialization failed; falling back to unsupported 原因是hado ...
- Centos7 之目录处理命令(八)
linux中 关于目录 有几个重要概念 一个是 / 根目录 还有一个当前用户的家目录 比如 root用户的家目录是 /root 普通用户的家目录是/home/xxx 下 root登录 默认家目录 ...