SparkStreaming流处理
一、Spark Streaming的介绍
1. 流处理
流式处理(Stream Processing)。流式处理就是指源源不断的数据流过系统时,系统能够不停地连续计算。所以流式处理没有什么严格的时间限制,数据从进入系统到出来结果可能是需要一段时间。然而流式处理唯一的限制是系统长期来看的输出速率应当快于或至少等于输入速率。否则的话,数据岂不是会在系统中越积越多(不然数据哪去了)?如此,不管处理时是在内存、闪存还是硬盘,早晚都会空间耗尽的。就像雪崩效应,系统越来越慢,数据越积越多。
2、spark架构
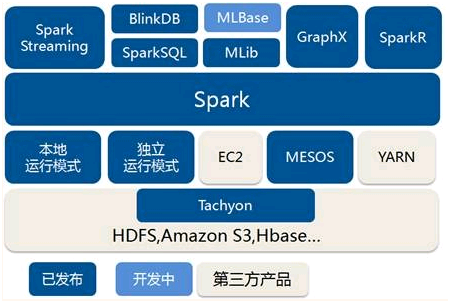
3、Spark Streaming特点
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的优势在于:
能运行在100+的结点上,并达到秒级延迟。
使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
能集成Spark的批处理和交互查询。
为实现复杂的算法提供和批处理类似的简单接口。
Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
4、程序流程
引入头文件
|
import org.apache.spark._ |
1. 创建StreamingContext对象 同Spark初始化需要创建SparkContext对象一样,使用Spark Streaming就需要创建StreamingContext对象。创建StreamingContext对象所需的参数与SparkContext基本一致,包括指明Master,设定名称(如NetworkWordCount)。需要注意的是参数Seconds(1),Spark Streaming需要指定处理数据的时间间隔,如上例所示的1s,那么Spark Streaming会以1s为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置;
|
|
- 创建InputDStream Spark Streaming需要指明数据源。如上例所示的socketTextStream,Spark Streaming以socket连接作为数据源读取数据。当然Spark Streaming支持多种不同的数据源,包括Kafka、 Flume、HDFS/S3、Kinesis和Twitter等数据源;
|
val lines = |
- 操作DStream对于从数据源得到的DStream,用户可以在其基础上进行各种操作,如上例所示的操作就是一个典型的WordCount执行流程:对于当前时间窗口内从数据源得到的数据首先进行分割,然后利用Map和ReduceByKey方法进行计算,当然最后还有使用print()方法输出结果;
|
val words = val pairs = |
- 启动Spark Streaming之前所作的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当ssc.start()启动后程序才真正进行所有预期的操作。
|
ssc.start() ssc.awaitTermination() |
5、单词统计例子
|
object Count ssc.awaitTermination() } |
二、SparkStreaming累加器及广播变量的使用
Spark Streaming的累加器和广播变量无法从checkpoint恢复。如果在应用中既使用到checkpoint又使用了累加器和广播变量的话,最好对累加器和广播变量做懒实例化操作,这样才可以使累加器和广播变量在driver失败重启时能够重新实例化。
定义累加器
|
Object DroppedWordsCounter { |
定义广播变量
|
object |
删除重复的单词
|
object SparkConf().setAppName("RecoverableNetworkWordCount").setMaster("local[2]") |
主函数
|
def |
SparkStreaming流处理的更多相关文章
- Spark之 Spark Streaming流式处理
SparkStreaming Spark Streaming类似于Apache Storm,用于流式数据的处理.Spark Streaming有高吞吐量和容错能力强等特点.Spark Streamin ...
- 通过案例对SparkStreaming透彻理解三板斧之一
本节课通过二个部分阐述SparkStreaming的理解: 一.解密SparkStreaming另类在线实验 二.瞬间理解SparkStreaming本质 Spark源码定制班主要是自己做发行版.自己 ...
- (转)park1.0.0生态圈一览
转自博客:http://www.tuicool.com/articles/FVBJBjN Spark1.0.0生态圈一览 Spark生态圈,也就是BDAS(伯克利数据分析栈),是伯克利APMLab实验 ...
- Spark1.0.0 生态圈一览
Spark生态圈,也就是BDAS(伯克利数据分析栈),是伯克利APMLab实验室精心打造的,力图在算法(Algorithms).机器(Machines).人(People)之间通过大规模集 ...
- Storm简介及使用
一.Storm概述 网址:http://storm.apache.org/ Apache Storm是一个免费的开源分布式实时计算系统.Storm可以轻松可靠地处理无限数据流,实现Hadoop对批处理 ...
- 基于Hadoop生态SparkStreaming的大数据实时流处理平台的搭建
随着公司业务发展,对大数据的获取和实时处理的要求就会越来越高,日志处理.用户行为分析.场景业务分析等等,传统的写日志方式根本满足不了业务的实时处理需求,所以本人准备开始着手改造原系统中的数据处理方式, ...
- Spark-Streaming 常用流式计算算子
UpdateStateByKey 使用说明:维护key的状态. 使用注意:使用该算子需要设置checkpoint 使用示例: object UpdateStateByKeyTest { def mai ...
- 大数据学习——SparkStreaming整合Kafka完成网站点击流实时统计
1.安装并配置zk 2.安装并配置Kafka 3.启动zk 4.启动Kafka 5.创建topic [root@mini3 kafka]# bin/kafka-console-producer. -- ...
- SparkStreaming(源码阅读十二)
要完整去学习spark源码是一件非常不容易的事情,但是咱可以积少成多嘛~那么,Spark Streaming是怎么搞的呢? 本质上,SparkStreaming接收实时输入数据流并将它们按批次划分,然 ...
随机推荐
- 20175211 2017-2018-2 《Java程序设计》第六周学习记录
目录 7.1 内部类 7.2 匿名类 7.3 异常类 断言 参考资料 <Java 2实用教程>第七章 内部类和异常类 7.1 内部类 内部类的外嵌类的成员变量在内部类中依然有效,内部类中的 ...
- IR2104s半桥驱动使用经验
多次使用IR2104s,每次的调试都有种让人吐血的冲动.现在将使用过程遇到的错误给大家分享一下,方便大家找到思路. 一.自举电容部分(关键) 1.听说自举电路必须要安装场效应管,于是我在使用过程中,安 ...
- if __name__ == '__main__' 这段代码怎么理解???
__name__是内置变量,可用于表示当前模块的名字,而“__main__”等于当前执行文件的名称. 两个名称搞不清没关系,往下看待会解释 对很多编程语言来说,程序都需要一个入口,例如C系列.Java ...
- 用HTML5+原生js实现的推箱子游戏
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- UBUNTU安装 SSH 服务
输入命令"sudo apt -y install openssh-server" 输入当前用户密码,等待完成openssh-server安装. 安装完毕,运行命令"sud ...
- 查看Python、flask 版本
查看Django版本检查是否安装成功,可以在dos下查看Django版本. 1.输入python 2.输入import django3.输入django.get_version() 查看flask版本 ...
- CentOS 7 配置DHCP
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一个局域网的网络协议,使用UDP协议工作, 主要有两个用途:给内部网络或网络服务供应商自动分配IP ...
- 【数据结构】算法 LinkList (Merge Two Sorted Lists)
合并2个有序链表 list A, list B, Solution: 对A,B 表按序读取数据,比较大小后插入新链表C. 由于两个输入链表的长度可能不同,所以最终会有一个链表先完成插入所有元素,则直接 ...
- Ubuntu14.04 安装 Sublime Text 3
Linux下安装,一种办法是从官网下载 tar.bz ,手动安装.另一种是使用apt-ge安装 这里介绍用 apt-get 自动安装方法: 1.添加sublime text 3的仓库: sudo ad ...
- Java EE开发技术课程第五周(Applet程序组件与AJAX技术)
1.Applet程序组件 1.1.定义: Applet是采用Java编程语言编写的小应用程序,该程序可以包含在HTML(标准通用标记语言的一个应用)页中,与在页中包含图像的方式大致相同.含有Apple ...