论文阅读笔记四十二:Going deeper with convolutions (Inception V1 CVPR2014 )

论文原址:https://arxiv.org/pdf/1409.4842.pdf
代码连接:https://github.com/titu1994/Inception-v4(包含v1,v2,v4)
摘要
本文提出了一个深层的卷积网络结构-Inception,该结构的主要特点是提高了网络内部计算资源的利用率。在预估计算资源消耗量不变的情况下增加网络的深度及宽度。为了进行有效的优化,结构决策基于Hebbian原理及多尺寸处理操作。本文思想的一个经典实现是GoogLeNet,网络的深度为22层,该网络在分类及检测任务上进行评估。
介绍
相比于ILSVRC2014的冠军网络,GoogLeNet的参数量要少12倍多,准确率却得到大幅度的改善。目标检测任务上的改进主要来自于网络结构及经典计算机视觉的协同作用。
本文的另一个特点是针对移动端及嵌入端上的计算,本文在计算资源及内存方面的利用率提高方面证明了该网络的有效性。大部分实验证明,Inception在推理时保持1.5 billion次的加乘法操作,因此可以应用至实际生活中。
本文提出的Inception网络为深度更深的卷积网络。这里的“更深”包含两个方面意义,一定意义上引入了Inception形式的层次组织,同时也直接增加了网络的深度。该网络结构在ILSVRC的分类和检测任务上超过了当时最好的模型。
相关工作
自LeNet-5开始,卷积网络有固定的结构:一系列卷积层一般夹杂着固定的标准化处理及池化层,及一个或者多个全连接层。对于更大的数据集,开始流行改变网络的深度来提高分类准确率,同时利用Dropout来防止过拟合。
尽管最大池化层会造成空间信息上准确率的损失,但相似的网络结构成功的应用于定位,分类及人体姿态估计任务上,受原始神经科学模型的启发,使用一系列固定的具有不同尺寸的Gabor核来处理多尺度问题,这与Inception模型相类似,与固定的两层深的模型不同,Inception模型中的所有卷积核都是可以学习的。在GoogLeNet中,Inception层可以重复多次,最终得到一个22层深的卷积网络模型。
Network in Network用于增强网络的表示能力,此方法可以看作是在经典的整流激活函数后增加额外的1x1的卷积核,同时,此模型可以很容易的融合到当前的卷积网络中。本文主要使用此网络结构,然而,本文中1x1的卷积核有两个用途,更主要的是用于降维,移除计算量较大的模块,从而可以增加网络的深度及宽度。
当时,目标检测算法最好的是R-CNN,R-CNN将所有检测问题分为两个子问题:首先利用像颜色,超像素的一致性等低层次的特征生成类别不可知的proposals,然后,利用卷积及分类器对对应位置进行类别分类。两阶段的方法利用具有低层次线索的边界框分割的准确率及最好卷积网络的分类特性。本文在检测阶段采用相似的流程,比如使用多尺寸的框预测出更高召回率的边界框及对目标框进行更有效分类的集成方法等。
动机
增强深度神经网络最直接的方式是直接增加网络的尺寸,包括增加网络的深度及宽度。这种方式简单粗暴,然而存在两个重要的缺点。
更大的尺寸通常意味着拥有更多的参数量,容易造成网络过拟合,特别是当有标记的数据及其有限的条件下,这会成为主要瓶颈因素,由于创建像ImageNet中的细粒度分类的数据集(如下图)是十分费力费时的。
 另一个问题是如果一味的增加网络的尺寸则会大大增加计算资源的消耗。比如,相连的两个卷积层,增加其卷积核的数量,则会造成平方级别的计算量级。如果增加的容量无法有效的利用,则会造成计算量大量的浪费。由于通常计算资源是有限的,因此合理的分配计算资源要比任意增加尺寸对提高结果的质量更有帮助。
另一个问题是如果一味的增加网络的尺寸则会大大增加计算资源的消耗。比如,相连的两个卷积层,增加其卷积核的数量,则会造成平方级别的计算量级。如果增加的容量无法有效的利用,则会造成计算量大量的浪费。由于通常计算资源是有限的,因此合理的分配计算资源要比任意增加尺寸对提高结果的质量更有帮助。
解决上述问题的基本方法是将全部的全连接层,甚至卷积层中的,变为稀疏连接结构。有结论表明,如果存在一个更大的及更稀疏的网络能够表示数据集的概率分布,则可以通过分析最后一层激活值的相关性统计分布,及聚合较高相关性的输出来一层一层的构建最优的网络。虽然其有较强的假设条件,但实际上即使在较弱的假设条件下,该理论仍然有效。
当前对于非均匀的数据集进行数值计算的计算效率是非常低效的。虽然将计算量降低了100倍,但查找的开销及缓存丢失的原因,使得即使将数据变换为稀疏结构,结果也是于事无补。随着算法的不断改进、高度调优的数字库,及利用底层CPU或GPU硬件的细微细节,可以实现极其快速的密集矩阵乘法,会进一步扩大这种差距。而非均匀的稀疏的模型需要更加复杂的流程及计算基础。目前大多数基于机器学习的视觉系统利用卷积结构来获得空间的稀疏性。然而,卷积可以看作是前面几层网络中patch密集连接的集合。传统的卷积网络在特征维度上使用随机的,稀疏的连接表,从而打破了对称性,并提高了学习的效率,同时为了更好的并行计算,选择使用全连接层。均匀化的结构,更多的卷积核及更大的batch可以实现高效的密集运算。
本文联想到一个问题,是否在基于当前的硬件资源及密集矩阵计算的条件下利用额外的稀疏性,有研究表明,将稀疏矩阵转变为密集的子矩阵会得到比稀疏矩阵更好的效果。
基于前面的理论构建了Inception网络拓扑结构。经过微调及调参优化,Inception在上下文定位及目标检测上十分有效。
网络结构
Inception结构的主要目标是如何将卷积网络中的局部最优稀疏结构近似的转变为密集结构。本文的变换不变性意味着从卷积结构中进行构建,找到局部最优的结构,并将此结构进行重复。本文认为卷积网络前几层的单元为输入图像的对应响应,并将这些卷积核聚到一个卷积bank中。底层网络的单元作用于图像的局部区域。因此,可以在单独的一个区域中使用多个卷积核bank,然后在其后一层使用1x1的卷积来进行聚合。同时,期望更少数量但具有更多稀疏的集群,在更大的patch中被卷积覆盖,因此,更大区域上的patch数量也会减少。为了避免patch对齐问题。目前,Inception模型将结构限制在1x1,3x3,5x5几种结构尺寸。这意味着网络是将所有层的卷积banks的输出做了串联处理后作为下个阶段的输入,同时,在正常的卷积上增加一个平行的池化操作会有利于结果的生成。结构如下图。
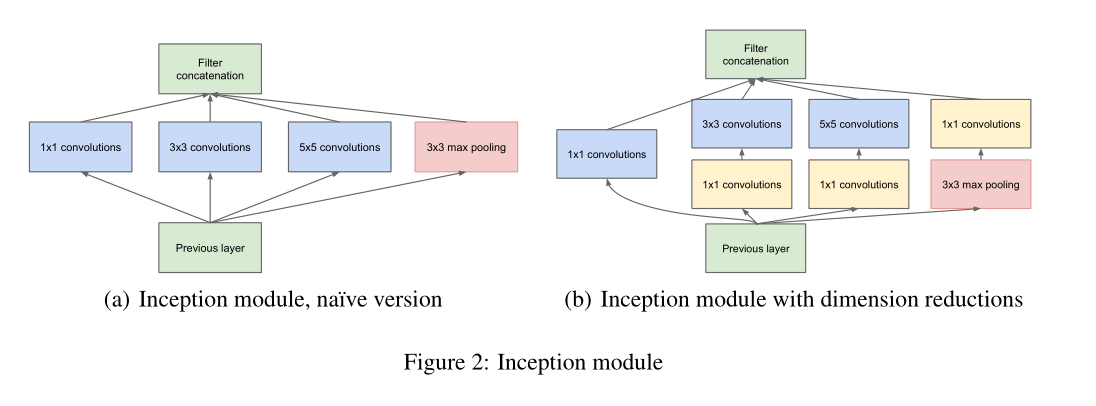 由于Inception 模型堆叠在顶部,因此,其输出的相关性统计是有所不同的:较高层次的抽象特征由较高层次的网络提取。而其空间注意力的减少表明在更高层的网络中应该增加3x3,5x5卷积核的比例。
由于Inception 模型堆叠在顶部,因此,其输出的相关性统计是有所不同的:较高层次的抽象特征由较高层次的网络提取。而其空间注意力的减少表明在更高层的网络中应该增加3x3,5x5卷积核的比例。
上述模型存在一个弊端,大量5x5的卷积核需要占用大量的计算资源,如果后接池化层,影响会更严重,输出filter的通道数与上一阶段的通道数相同。将卷积层的输出与池化层的输出相融合会不可避免的增加输出量,使计算效率低下。
为解决上述问题,在计算量较大的地方应用降维处理。低纬度的嵌入表示也可以表示相对较大的patch信息,然而,嵌入式以一种压缩密集的形式对信息进行表示,压缩的信息很难建模。本文希望在大多数区域进行稀疏表示,当需要将信号聚合时才进行压缩处理。因此,在3x3,5x5的卷积后加1x1的卷积来进行压缩。
本文结构的一个优点是在不过分增加计算量的基础上可以增加每个层的单元。在与一个较大patch进行卷积之前进行降维操作。另一个优点是该结构结合了不同的尺寸信息,因此,网络可以获取不同尺寸大小的抽象信息。
随着计算条件的改善,网络逐渐趋于更深,更宽的情形。本文发现使用Inception结构的网络要比没有的快两到三倍。
GoogLeNet
本文使用了较深的和较宽的Inception模型,发现将其嵌入到整个网络中效果得到大幅度的改进。其中,GoogLeNet的Inception部分结构如下:
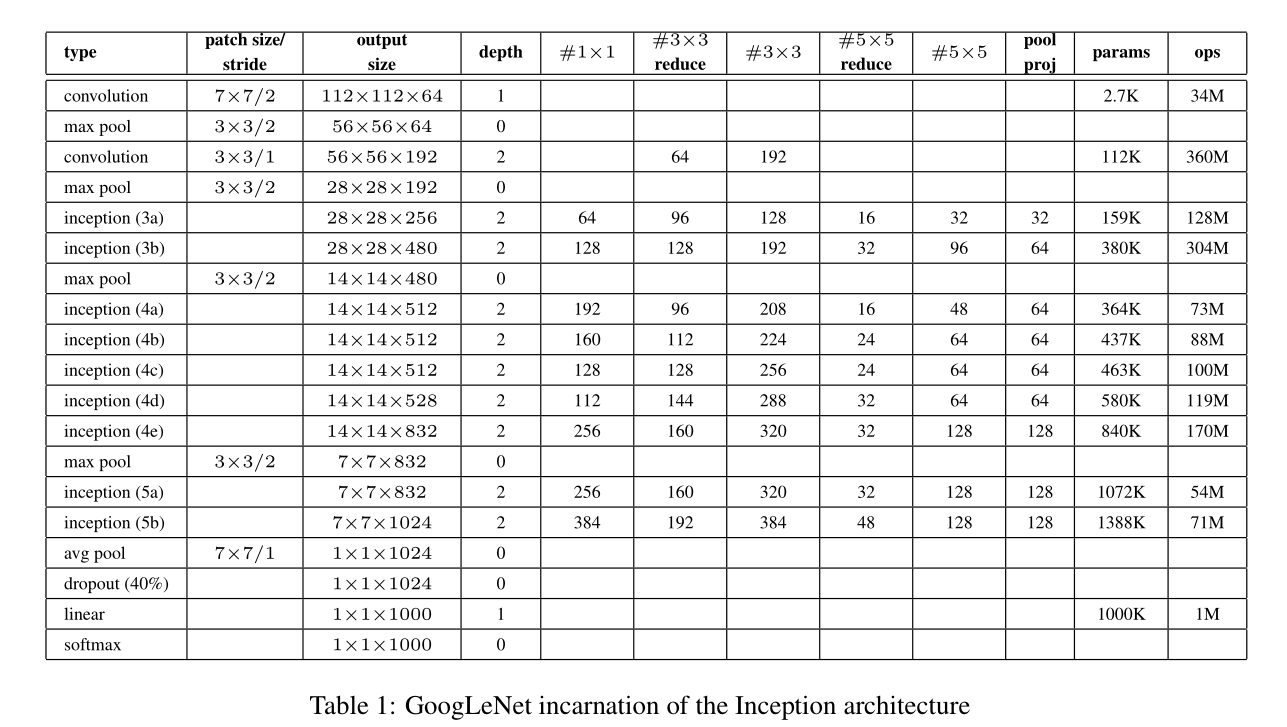 网络中的所有卷积都接着一个整流线性激活层。感受野的大小为224x224,输入为减均值处理后的RGB图像。在最大池化层后增加一个1x1的卷积,以进行降维操作。
网络中的所有卷积都接着一个整流线性激活层。感受野的大小为224x224,输入为减均值处理后的RGB图像。在最大池化层后增加一个1x1的卷积,以进行降维操作。
此网络结构偏于高效计算设计的,因此,可以在计算资源有限的独立设备上运行。网络的深度为22层。在分类器前增加了平均池化层,同时增加了一些额外的非线性层。可以使网络很容易的对其他的数据集的进行微调或者训练。然而,将全连接层替换为平均池化层可以提高top-1的准确率为0.6%。
较深的网络,其梯度信息反向传播到所有层是至关重要的。一种有趣的观点是网络中间层产生的特征区分度较高。在中间层增加一些辅助分类器,增加分类器低层次的区分度,增加梯度信号并能够进行反向传递,同时,增加一些正则化处理。GoogleNet的结构如下图所示(详细请看论文原文)。
 实验结果
实验结果

Reference
[1] Know your meme: We need to go deeper. http://knowyourmeme.com/memes/ we-need-to-go-deeper. Accessed: 2014-09-15.
[2] Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013.
[3]¨Umit V. C¸atalyürek, Cevdet Aykanat, and Bora Uc ¸ar. On two-dimensional sparse matrix partitioning: Models, methods, and a recipe. SIAM J. Sci. Comput., 32(2):656–683, February 2010.
论文阅读笔记四十二:Going deeper with convolutions (Inception V1 CVPR2014 )的更多相关文章
- 论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction (1)Motivation: 大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据. (2)Method: 对没有标记的数据生成 ...
- 论文阅读笔记四十四:RetinaNet:Focal Loss for Dense Object Detection(ICCV2017)
论文原址:https://arxiv.org/abs/1708.02002 github代码:https://github.com/fizyr/keras-retinanet 摘要 目前,具有较高准确 ...
- 论文阅读笔记四十九:ScratchDet: Training Single-Shot Object Detectors from Scratch(CVPR2019)
论文原址:https://arxiv.org/abs/1810.08425 github:https://github.com/KimSoybean/ScratchDet 摘要 当前较为流行的检测算法 ...
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记四十六:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1903.00621 摘要 本文提出了基于无anchor机制的特征选择模块,是一个简单高效的单阶段组件,其可以结合特征金字塔嵌入到单阶段检测器中. ...
- 论文阅读笔记三十二:YOLOv3: An Incremental Improvement
论文源址:https://pjreddie.com/media/files/papers/YOLOv3.pdf 代码:https://github.com/qqwweee/keras-yolo3 摘要 ...
- 论文阅读笔记六十二:RePr: Improved Training of Convolutional Filters(CVPR2019)
论文原址:https://arxiv.org/abs/1811.07275 摘要 一个训练好的网络模型由于其模型捕捉的特征中存在大量的重叠,可以在不过多的降低其性能的条件下进行压缩剪枝.一些skip/ ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- 论文阅读笔记四十五:Region Proposal by Guided Anchoring(CVPR2019)
论文原址:https://arxiv.org/abs/1901.03278 github:code will be available 摘要 区域anchor是现阶段目标检测方法的重要基石.大多数好的 ...
随机推荐
- Linux(Ubuntu)使用日记(七)------终端控制器Terminator安装使用
1.目的 实现分屏效果,如图: 如果使用系统自带的终端,可能会使这种效果: 综上所述,知道我们为什么要安装Terminator了吧. 2.安装过程 Terminator 的安装非常方便,在 Ubunt ...
- Django+Vue打造购物网站(九)
支付宝沙箱环境配置 https://openhome.alipay.com/platform/appDaily.htm?tab=info 使用支付宝账号进行登陆 RSA私钥及公钥生成 https:// ...
- [linux]解除linux对多次登录密码错误的账户的锁定
其他wheel账户下,执行: sudo pam_tally2 --user=username --reset
- Mysql相关知识点梳理(一):优化查询
EXPLAIN解析SELECT语句执行计划: EXPLAIN与DESC同义,通过它可解析MySQL如何处理SELECT,提供有关表如何联接和联接的次序,还可以知道什么时候必须为表加入索引以得到一个使用 ...
- Python【pyyaml】模块
pyyaml模块安装: pip install pyyaml pyyaml导入: import yaml pyyaml使用: 1.使用前,在pycharm中新建一个以yaml或yml结尾的文件,保存为 ...
- utf8的大小写敏感性测试及其修改方法
utf8的大小写敏感性测试及其修改方法 # 测试utf8的大小写敏感性及其修改方法 -- 以下是utf8不区分大小写 # 修改数据库: ALTER DATABASE database_name CHA ...
- GO语言系列(二)- 基本数据类型和操作符
一.文件名 & 关键字 & 标识符 1.所有go源码以.go结尾 2.标识符以字母或下划线开头,大小写敏感 3._是特殊标识符,用来忽略结果 4.保留关键字 二.Go程序的基本结构 p ...
- MapReduce-序列化(Writable)
Hadoop 序列化特点 Java 的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传 ...
- Hadoop记录-hadoop jmx配置
1.hadoop-env.sh添加export HADOOP_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dco ...
- 【1】JDK8 HashMap扩容优化
JDK1.7 VS JDK1.8 比较 优化概述: resize 扩容优化 引入了红黑树,目的是避免单条链表过长而影响查询效率 解决了resize时多线程死循环问题,但仍是非线程安全的 这里主要讲讲扩 ...