python爬虫学习,使用requests库来实现模拟登录4399小游戏网站。
1.首先分析请求,打开4399网站。
右键检查元素或者F12打开开发者工具。然后找到network选项,
这里最好勾选perserve log 选项,用来保存请求日志。这时我们来先用我们的账号密码登陆一下,然后查看一下截获的请求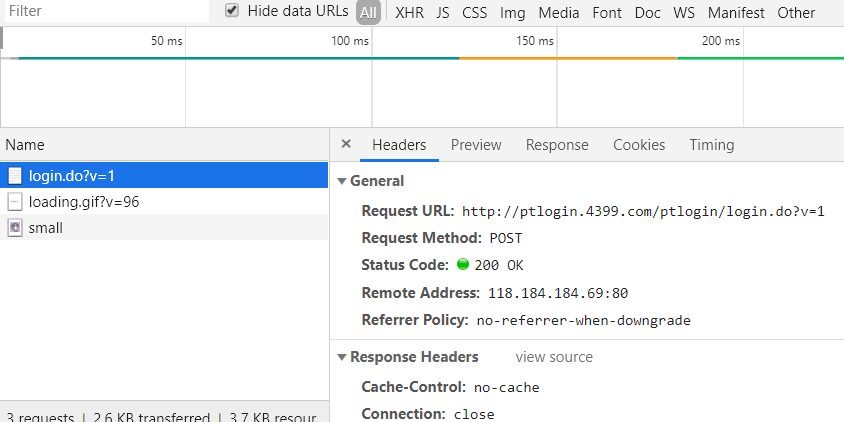
可以很清楚的看到这里有个login,而且这个请求是post请求,下拉查看一下Form data,也就是表单数据
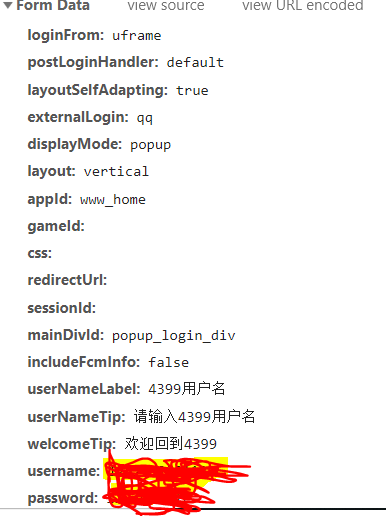
可以很清楚的看到我们的刚才登录发送给服务器的表单数据,更重要的是,除了uername和password之外,所有的数据都是一成不变的,这意味着我们不需要解析网页的源码获得信息,只需要把用户名和密码提交上去就行,下面开始构建我们的代码。
import requests
#模拟登陆4399 成功 一定要灵活运用session()这个好东西
#这是我们要提交的表单
data={
'loginFrom':'uframe',
'postLoginHandler':'default',
'layoutSelfAdapting':'true',
'externalLogin':'qq',
'displayMode':'popup',
'layout':'vertical',
'appId':'www_home',
'mainDivId':'popup_login_div',
'includeFcmInfo':'false',
'userNameLabel':'4399用户名',
'userNameTip':'请输入4399用户名',
'welcomeTip':'欢迎回到4399',
'username':'',
'password':''
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
url='http://ptlogin.4399.com/ptlogin/login.do?v=1'
session=requests.Session()
res=session.post(url=url,data=data,headers=headers)
res2=session.get(url='http://u.4399.com/user/info',headers=headers) #成功登陆以后,查看我们的用户数据
#这里把我们的请求结果保存到文件
f=open('4399.html','wb')
f.write(res2.content)
f.close()
运行起来,然后查看我们保存的html文件,
模拟登录成功! 这就是我们个人用户信息的源代码。
这个例子主要讲了requests 的post方法,用于post请求,还有很重要的session,用于维持会话,希望这个例子对大家能有所帮助,谢谢,
python爬虫学习,使用requests库来实现模拟登录4399小游戏网站。的更多相关文章
- Python爬虫学习1: Requests模块的使用
Requests函数库是学习Python爬虫必备之一, 能够帮助我们方便地爬取. Requests: 让HTTP服务人类. 本文主要参考了其官方文档. Requests具有完备的中英文文档, 能完全满 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
- PYTHON 爬虫笔记三:Requests库的基本使用
知识点一:Requests的详解及其基本使用方法 什么是requests库 Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库,相比u ...
- Python爬虫的开始——requests库建立请求
接下来我将会用一段时间来更新python爬虫 网络爬虫大体可以分为三个步骤. 首先建立请求,爬取所需元素: 其次解析爬取信息,剔除无效数据: 最后将爬取信息进行保存: 今天就先来讲讲第一步,请求库re ...
- python爬虫#网络请求requests库
中文文档 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html requests库 虽然Python的标准库中 urlli ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- 网络爬虫入门:你的第一个爬虫项目(requests库)
0.采用requests库 虽然urllib库应用也很广泛,而且作为Python自带的库无需安装,但是大部分的现在python爬虫都应用requests库来处理复杂的http请求.requests库语 ...
随机推荐
- spoj 839 OPTM - Optimal Marks&&bzoj 2400【最小割】
因为是异或运算,所以考虑对每一位操作.对于所有已知mark的点,mark的当前位为1则连接(s,i,inf),否则连(i,t,inf),然后其他的边按照原图连(u,v,1),(v,u,1),跑最大流求 ...
- spring boot 项目发布运行
1. maven install 发布jar包 2. java -jar webservice.jar 启动jar包
- How many Fibs? POJ - 2413
How many Fibs? POJ - 2413 高精模板 #include<cstdio> #include<cstring> #include<algorithm& ...
- 205 Isomorphic Strings 同构字符串
给定两个字符串 s 和 t,判断它们是否是同构的.如果 s 中的字符可以被替换最终变成 t ,则两个字符串是同构的.所有出现的字符都必须用另一个字符替换,同时保留字符的顺序.两个字符不能映射到同一个字 ...
- 移动web开发基础(二)——viewport
本文主要研究为什么移动web开发需要设置viewport,且一般设置为<meta name="viewport" content="width=device-wid ...
- 为OS X开发者准备的15个超棒应用
几乎所有的开发人员在他们日常的开发工作中都有他们自己不可缺少的工具或实用程序集. 这些工具中的每一个都提供了特定的功能,大多数开发者都已经将他们集成到了其工作流程中. 使用这些工具或实用程序不单单只是 ...
- object -c OOP , 源码组织 ,Foundation 框架 详解1
object -c OOP , 源码组织 ,Foundation 框架 详解1 1.1 So what is OOP? OOP is a way of constructing softwar ...
- git创建分支及日常使用
克隆代码 git clone https://github.com/master-dev.git 查看所有分支 git branch --all # 默认只有master分支,所以会看到如下两个分支 ...
- iOS-UI控件之UITableView(一)
UITableView 介绍 UITableView 是用来用列表的形式显示数据的UI控件 举例 QQ好友列表 通讯录 iPhone设置列表 tableView 常见属性 // 设置每一行cell的高 ...
- CentOS 7 配置本地yum 源
1. 加载 CentOS的ISO镜像并挂载: [root@localhost files]# mount /media/files/CentOS-7-x86_64-DVD-1611.iso /mnt/ ...