Python爬虫的开始——requests库建立请求
接下来我将会用一段时间来更新python爬虫
网络爬虫大体可以分为三个步骤。
首先建立请求,爬取所需元素;
其次解析爬取信息,剔除无效数据;
最后将爬取信息进行保存;
今天就先来讲讲第一步,请求库requests
request库主要有七个常用函数,如下所示
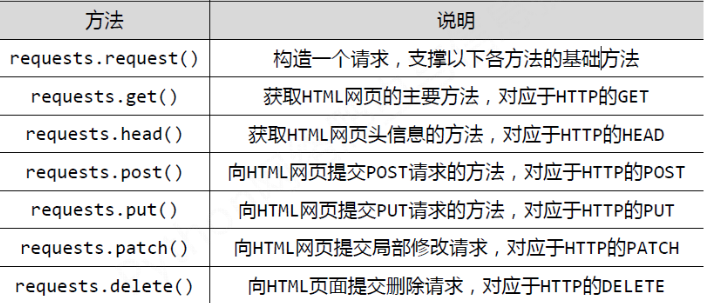
而通过requests创建的数据类型为response
我们以爬取百度网站为例
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
运行结果如下所示
<class 'requests.models.Response'>
[Finished in 1.3s]
那么作为请求对象,具有哪些属性呢?
爬取数据第一步要做的事便是确认是否连接成功
status_code()从功能角度考虑,算的上是一种判断函数,调用将会返还结果是否成功
如果返回结果为200,则代表连接成功,如果返回结果为404,则代表连接失败
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
print(t.status_code)
如图所示返回结果为200,连接成功

那么下一步便是获得网址代码,不过在获得代码之前,还需要做一件事,得到响应内容的编码方式
不同的编码方式将会影响爬取结果
比如说百度网址:https://www.baidu.com/
采用编码方式为ISO-8859-1
获取编码方式为encoding
如下所示
import requests as r
t=r.get("https://www.baidu.com/")
print(type(t))
print(t.status_code)
print(t.encoding)
结果:
<class 'requests.models.Response'>
200
ISO-8859-1
当然有的网页采用 utf8,也有使用gbk,
不同的编码方式会影响我们获得的源码
也可以通过手动更改来改变获得的编码方式
比如:
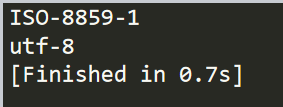
import requests as r
t=r.get("https://www.baidu.com/")
print(t.encoding)
t.encoding="utf-8"
print(t.encoding)
结果
也可以试着备选码方式,apparent_encoding
之后我们就可以获得源代码了,我们需要将源代码以字符串类型输出保存
这就需要用到text
如下所示:
import requests as r
t=r.get("https://www.baidu.com/")
print(t.text)
结果:

这样我们就获得了对应网站的源码,完成了爬虫的第一步
Python爬虫的开始——requests库建立请求的更多相关文章
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
- PYTHON 爬虫笔记三:Requests库的基本使用
知识点一:Requests的详解及其基本使用方法 什么是requests库 Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库,相比u ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- 网络爬虫入门:你的第一个爬虫项目(requests库)
0.采用requests库 虽然urllib库应用也很广泛,而且作为Python自带的库无需安装,但是大部分的现在python爬虫都应用requests库来处理复杂的http请求.requests库语 ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
随机推荐
- sql优化提速整理
sql优化提速整理 场景描述 在我们实际开发中,随着业务的不断增加,数据量也在不断的攀升,这样就离不开一个问题:数据查询效率优化 根据自己的以往实际项目工作经验和学习所知,现在对SQL查询优化做一个简 ...
- 第三方软件 pcanywhere提权
pcanywhere 是一个远程管理软件 1.访问pcanywhere默认安装目录 访问 下载打开 利用破解工具直接 选择刚刚下载的软件 点破解 拿到用户密码后去百度下载客户端让后连接
- 三维动画形变算法(Mixed Finite Elements)
混合有限元方法通入引入辅助变量后可以将高阶微分问题变成一系列低阶微分问题的组合.在三维网格形变问题中,我们考虑如下泛函极值问题: 其中u: Ω0 → R3是变形体的空间坐标,上述泛函极值问题对应的欧拉 ...
- 彻底解决 Mechanism level: Failed to find any Kerberos tgt
错误描述 Secure Client Cannot Connect ([Caused by GSSException: No valid credentials provided(Mechanism ...
- [正确配置]win7 PL/SQL 连接Oralce 11g 64位
PL/SQL 版本号:15.0.5.1710 32位 win7 64位系统 instantclient 12.1 32位,PL/SQL不支持64位 关键问题 1.Not logged on 2.没有c ...
- django-Views之request(二)
book/views.py def index(request): http_list = { '<h1>请求协议: <span style="color:red" ...
- vue进入新页面,与原页面滚动到相同高度的解决方案
可以在vue路由新增scrollBehavior,控制跳转页面高度 import Router from 'vue-router' new Router({ scrollBehavior (to, f ...
- Flask框架实现给视图函数增加装饰器操作示例
在@app.route的情况下增加装饰器的写法: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 2 ...
- 在线API文档管理工具Simple doc
Simple doc是一个简易的文档发布管理工具,为什么要写Simple doc呢?主要原因还是github的wiki并不好用:没有目录结构,文章没有Hx标签索引,最悲剧的是文章编辑的时候不能直接图片 ...
- CSPS模拟 41
说不会鸽就不会鸽的 虽然是炸裂的一场 T1没读懂题,T23交了两个无脑暴力 (公式懒得打了 latex过于感人) T1 点阵内不重合的直线有多少条? 枚举斜率,那么“后继”不在点阵内的点可以作出一个贡 ...