python爬虫学习,使用requests库来实现模拟登录4399小游戏网站。
1.首先分析请求,打开4399网站。
右键检查元素或者F12打开开发者工具。然后找到network选项,
这里最好勾选perserve log 选项,用来保存请求日志。这时我们来先用我们的账号密码登陆一下,然后查看一下截获的请求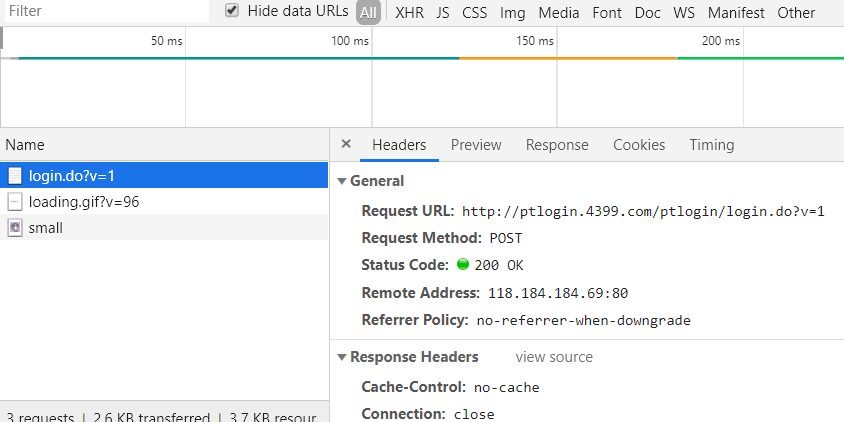
可以很清楚的看到这里有个login,而且这个请求是post请求,下拉查看一下Form data,也就是表单数据
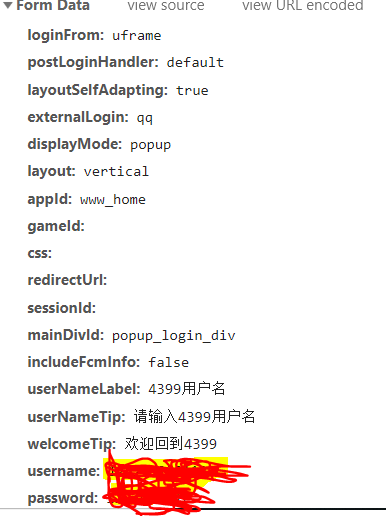
可以很清楚的看到我们的刚才登录发送给服务器的表单数据,更重要的是,除了uername和password之外,所有的数据都是一成不变的,这意味着我们不需要解析网页的源码获得信息,只需要把用户名和密码提交上去就行,下面开始构建我们的代码。
import requests
#模拟登陆4399 成功 一定要灵活运用session()这个好东西
#这是我们要提交的表单
data={
'loginFrom':'uframe',
'postLoginHandler':'default',
'layoutSelfAdapting':'true',
'externalLogin':'qq',
'displayMode':'popup',
'layout':'vertical',
'appId':'www_home',
'mainDivId':'popup_login_div',
'includeFcmInfo':'false',
'userNameLabel':'4399用户名',
'userNameTip':'请输入4399用户名',
'welcomeTip':'欢迎回到4399',
'username':'',
'password':''
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
url='http://ptlogin.4399.com/ptlogin/login.do?v=1'
session=requests.Session()
res=session.post(url=url,data=data,headers=headers)
res2=session.get(url='http://u.4399.com/user/info',headers=headers) #成功登陆以后,查看我们的用户数据
#这里把我们的请求结果保存到文件
f=open('4399.html','wb')
f.write(res2.content)
f.close()
运行起来,然后查看我们保存的html文件,
模拟登录成功! 这就是我们个人用户信息的源代码。
这个例子主要讲了requests 的post方法,用于post请求,还有很重要的session,用于维持会话,希望这个例子对大家能有所帮助,谢谢,
python爬虫学习,使用requests库来实现模拟登录4399小游戏网站。的更多相关文章
- Python爬虫学习1: Requests模块的使用
Requests函数库是学习Python爬虫必备之一, 能够帮助我们方便地爬取. Requests: 让HTTP服务人类. 本文主要参考了其官方文档. Requests具有完备的中英文文档, 能完全满 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
- PYTHON 爬虫笔记三:Requests库的基本使用
知识点一:Requests的详解及其基本使用方法 什么是requests库 Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库,相比u ...
- Python爬虫的开始——requests库建立请求
接下来我将会用一段时间来更新python爬虫 网络爬虫大体可以分为三个步骤. 首先建立请求,爬取所需元素: 其次解析爬取信息,剔除无效数据: 最后将爬取信息进行保存: 今天就先来讲讲第一步,请求库re ...
- python爬虫#网络请求requests库
中文文档 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html requests库 虽然Python的标准库中 urlli ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- 网络爬虫入门:你的第一个爬虫项目(requests库)
0.采用requests库 虽然urllib库应用也很广泛,而且作为Python自带的库无需安装,但是大部分的现在python爬虫都应用requests库来处理复杂的http请求.requests库语 ...
随机推荐
- Quartz.Net实现的定时执行任务调度
在之前的文章<推荐一个简单.轻量.功能非常强大的C#/ASP.NET定时任务执行管理器组件–FluentScheduler>和<简单.轻量.功能非常强大的C#/ASP.NET定时调度 ...
- 转【Python】Python-skier游戏[摘自.与孩子一起学编程]
http://www.cnblogs.com/zhaoxd07/p/4914818.html 我遇到的问题 问题1 self.image=pygame.image.load("skier_d ...
- javaservlet介绍
servlet 是 serve applet的意思 Java servlet是用Java编写的服务器端程序.其主要功能在于交互式地浏览和修改数据,生成动态Web内容. Servlet运行于支持Jav ...
- 面相切面编程AOP以及在Unity中的实现
一.AOP概念 AOP(Aspect-Oriented Programming,面向切面的编程),它是可以通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术.它是 ...
- java获取公网ip以及物理地址和代理商
package ipconfig; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStr ...
- 前端:常见的6种HTML5错误用法
一.不要使用section作为div的替代品 人们在标签使用中最常见到的错误之一就是随意将HTML5的<section>等价于<div>——具体地说,就是直接用作替代品(用于样 ...
- vim设置默认显示行号
vim /root/.vimrc 设置在当前登录用户根目录下,.vimrc文件本身不存在,创建后之间添加下面配置保存即可 set number
- [转]JavaScript线程运行机制
从开始接触js时,我们便知道js是单线程的.单线程,异步,同步,互调,阻塞等.在实际写js的时候,我们都会用到ajax,不管是原生的实现,还是借助jQuery等工具库实现,我们都知道,ajax可以实现 ...
- Farseer.net轻量级ORM开源框架 V1.x 入门篇:数据库上下文
导航 目 录:Farseer.net轻量级ORM开源框架 目录 上一篇:Farseer.net轻量级ORM开源框架 V1.x 入门篇:数据库配置文件 下一篇:Farseer.net轻量级ORM开源 ...
- 一些常用的meta标签及其作用
声明文档使用的字符编码 <meta charset='utf-8'>优先使用 IE 最新版本和 Chrome <meta http-equiv="X-UA-Compat ...