洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2)
前面学习了元家军以及其他的字符匹配方法,那得会用啊对吧?本篇博文就简单的解析怎么运用
正则表达式使用
前面说了正则表达式的知识点,本篇博文就是针对常用的正则表达式进行举例解析。相信你知道要用正则表达式的话,得导入re模块
1.re模块方法/属性

2.re模块常用方法/属性(正则表达式举例使用)
re模块的匹配数据的相关方法一般就这四个:search,match,findall,compile
search(string[, pos[, endpos]])
1.简介

官方文档说的很直白,像我等屌丝都能读懂啥意思:扫描并查找字符串里的的pattern值,如果匹配到则返回一个match对象,即一个匹配对象,否则没找到的的话则返回None。
- 第一个参数是模式,也就是我们需要匹配的字符
- 第二个参数是被用来匹配的字符串
- 第三个是以什么为标准来匹配。它的值一般为三个:
re.X:忽略空格和注释
re.I:忽略大小写的区别
re.S:匹配任意字符,包括新行
2.说再多不如来一个例子:

什么意思呢?为什么报错?因为正则表达式,匹配的都是字符串对不对,不可以是其他任何数据类型,所以报错。
正确匹配之后,返回了一个match对象对不对?有朋友说,反正电脑上都装了两个版本的python,以上是在python2.7.13环境下的,试试另一个版本呢?
python3.6.1(上面是python2.7.13)
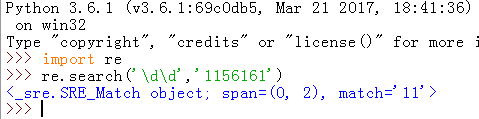
哎?WTF?咋回事,怎么不同版本匹配到的结果不一样啊?这是BUG还是什么?
好的,我可以负责任的告诉你,这不是BUG,这就是不同版本之间的区别,并且从python3.4还是python3.5开始(实在想不起了,但就是这俩版本之中其中一个版本),search方法才会智能的返回匹配到的字符所在起始位置(其实就是索引值)参数以及pattern参数的值或者None,而在之前,都只是返回一个匹配对象或None。
那怎么操作才能显示匹配的结果呢?
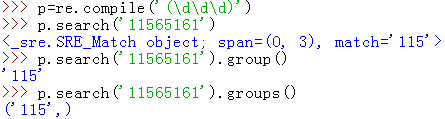
用group(),groups(),以及span()
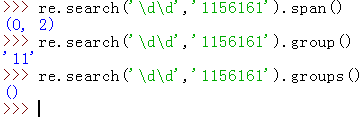
span():表示返回匹配字符串所在的起始位置,及索引值。上面的例子里匹配两个数字字符,则是0到2
group():表示获得一个或多个分组截获的字符串
- 指定多个参数时将以元组形式返回
- group1可以使用编号也可以使用别名
- 编号0代表整个匹配的子串,即group()==group(0)(group()等价于group(0))
- 没有截获字符串的组返回None
- 截获了多次的组返回最后一次截获的子串
groups():表示以元组形式返回全部分组截获的字符串,即groups()==group()==group(0)==(group(1),group(2),group(3),……)
但是这里为什么会返回一个空元组呢?因为给的pattern就只是一个参数,\d\d是被当作一个参数的。
当这么写groups()就可以匹配到一个元素的元组

那么匹配多个参数呢?

看到这里,我相信你也顺便的理解了前面说的groups()==group()==group(0)==(group(1),group(2),group(3),……)是什么意思了
并且在python3中,这几个方法也同样:

所以,不同的版本,使用相同的方法会有不同的结果
如果string中存在多个pattern子串,默认只返回第一个:

match
1.简介

意思是:尝试在字符串的起始处应用该pattern模式,如果匹配成功返回一个match对象,否则返回None
2.例
match和search基本没啥区别:

findall
1.简介

直译过来就是:搜索被匹配的string,以列表形式返回全部能匹配的子串。既然返回对象是一个列表,那么不存在group,groups,span等方法
2.例
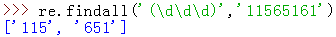
就这么简单
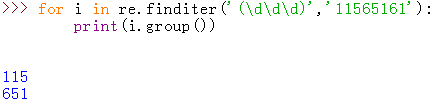
finditer
1.简介

搜索被匹配的string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器
2.例

或者可以这样:
compile
1.简介

这个方法是Pattern类对象的方法,用于将字符串形式的正则表达式编译为Pattern对象。换句话就是通过pattern值编译为pattern对象,再利用pattern对象的方法进行匹配
- 第一个参数是pattern模式
- 第二个参数flag是匹配模式,可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的
2.例
所以相信你也看来了,其实compile与search,match没什么区别,就是把之前一个步骤或者一行代码能搞定的拆分成了两个步骤或者两行代码
好的,看到那么多次的flags参数,这到底是干嘛的,上面也只是说可以等于多少,那么这里详细说明一下,它可以叫做修饰符,也可以叫做可选标志,前面只说了常用的三个值,下面是详细的:
re.IGNORECASE:忽略大小写,简写为 re.I
re.MULTILINE:多行模式,改变^和$的行为,简写为 re.M
re.DOTALL:点任意匹配模式,让'.'可以匹配包括'\n'在内的任意字符,简写为re.S
re.LOCALE:使预定字符类 \w \W \b \B \s \S 取决于当前区域设定, 简写为 re.L
re.ASCII:使 \w \W \b \B \s \S 只匹配 ASCII 字符,而不是 Unicode 字符,简写为 re.A
- re.UNICODE:使\w \W \b \B \s \S取决于Unicode定义的字符属性,简写为re.U
re.VERBOSE:详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。主要是为了让正则表达式更易读,简写为re.X
re.DEBUG:显示调试信息编译的表达式
以上的并不是都会用到,最常用的就是re.I,re.S,re.X
re.I
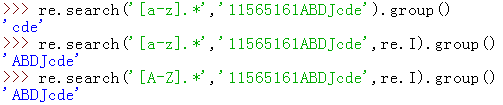
注意加与不加re.I参数的区别
re.S

注意加与不加re.S参数的区别
re.X
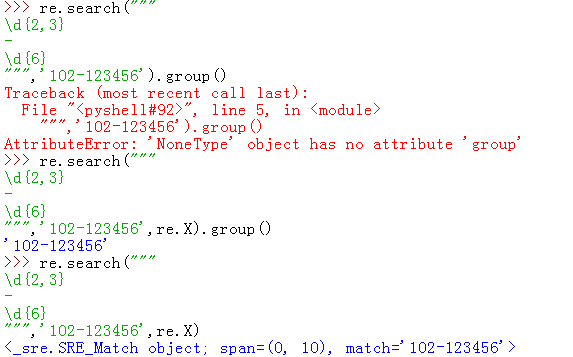
所以你看到了,使用re.X就可以把pattern值定时跨越多行了
这里要补充一句,不是每次匹配非得要在其后加入group()或者groups(),我加参数只是为了方便展示结果的
其他就很少用了,自己下去研究了
然后re模块还有其他的方法,大多是少用的或者是和字符串方法一样的,所以直接略过
作业:
1.匹配11位手机号
2.匹配身份证号(包括最后带‘X’的)
3.匹配ip地址,如:192.168.1.1
洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2)的更多相关文章
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
- 洗礼灵魂,修炼python(54)--爬虫篇—urllib2模块
urllib2 1.简介 urllib2模块定义的函数和类用来获取URL(主要是HTTP的),他提供一些复杂的接口用于处理: 基本认证,重定向,Cookies等.urllib2和urllib差不多,不 ...
- Python 学习 第九篇:模块
模块是把程序代码和数据封装的Python文件,也就是说,每一个以扩展名py结尾的Python源代码文件都是一个模块.每一个模块文件就是一个独立的命名空间,用于封装顶层变量名:在一个模块文件的顶层定义的 ...
- 洗礼灵魂,修炼python(53)--爬虫篇—urllib模块
urllib 1.简介: urllib 模块是python的最基础的爬虫模块,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如 ...
- 洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块
这里先要补充一下,Python3自带两个用于和HTTP web 服务交互的标准库(内置模块): http.client 是HTTP协议的底层库 urllib.request 建立在http.clien ...
- 洗礼灵魂,修炼python(59)--爬虫篇—httplib模块
httplib 1.简介 同样的,httplib默认存在于python2,python3不存在: httplib是python中http协议的客户端实现,可以用来与 HTTP 服务器进行交互,支持HT ...
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
通过 正则表达式 来获取一个网页中的所有的 URL链接,并下载这些 URL链接 的源代码 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 ...
随机推荐
- for循环输出树木的形状【java】
使用for循环语句输出以下“树木”效果: * *** ***** ******* ********* * * * * * 代码: /* * *** ***** ******* ********* * ...
- python练习七—P2P下载
最近有些事儿比较忙,python的学习就断断续续,这个练习来得比预期的晚,不过还好,不管做什么,我都希望能认真对待,认真做好每一件事. 引入 这个练习原书中称作“使用XML-RPC进行文件共享”,题目 ...
- Ubuntu环境下mysql常见的操作
1 启动mysql服务:Service mysql start 再次启动:service mysql restart 停止mysql服务:service mysql stop 确定mysql是否 ...
- Jenkins入门之任务基本操作
首先先简单讲一下Jenkins构建任务各种图标的含义 我的主界面有以下构建任务,这里前两列都是图标,第一列为构建的状态,前面已经讲过蓝色代表成功,红色代表失败.当然那是针对一次构建,一个构建任务可能有 ...
- python按引用赋值和深、浅拷贝
按引用赋值而不是拷贝副本 在python中,无论是直接的变量赋值,还是参数传递,都是按照引用进行赋值的. 在计算机语言中,有两种赋值方式:按引用赋值.按值赋值.其中按引用赋值也常称为按指针传值(当然, ...
- 巨杉数据库 MySQL兼容项目正式开源
9月7日.8日,2018 ODF 开源数据库论坛,在北京盛大开幕.在大会上,巨杉数据库正式发布了巨杉全新的MySQL/MariaDB兼容架构,并将项目正式开源. 开源数据库论坛(ODF)是中国开源数 ...
- OJ:自己实现一个简单的 priority_queue
Description 补足程序,使得下面程序输出结果是: 1.8 2.4 3.8 4.9 8.8 #include <iostream> #include <algorithm&g ...
- 在AspNetCore中扩展Log系列 - 介绍开源类库的使用(一)
转发时请注明原创作者及地址,否则追究责任. 原创:alunchen 当创建AspNetCore项目时 当我们创建一个AspNetCore项目时,需要我们手动添加Log: services.AddLog ...
- Code First下迁移数据库更改
第一步:Enable-Migrations -ContextTypeName [你的项目名].[你的数据库上下文] -Force 其中-Force为强制覆盖现有迁移配置 第二步:Add-Migrati ...
- [转]Angular4首页加载慢优化之路
本文转自:https://blog.csdn.net/itest_2016/article/details/80048398 Angular是一个比较完善的前端MVC框架,包含了模板,数据双向绑定,路 ...