MongoDB水平分片集群(转)
为何需要水平分片
1 减少单机请求数,将单机负载,提高总负载
2 减少单机的存储空间,提高总存空间。
下图一目了然:
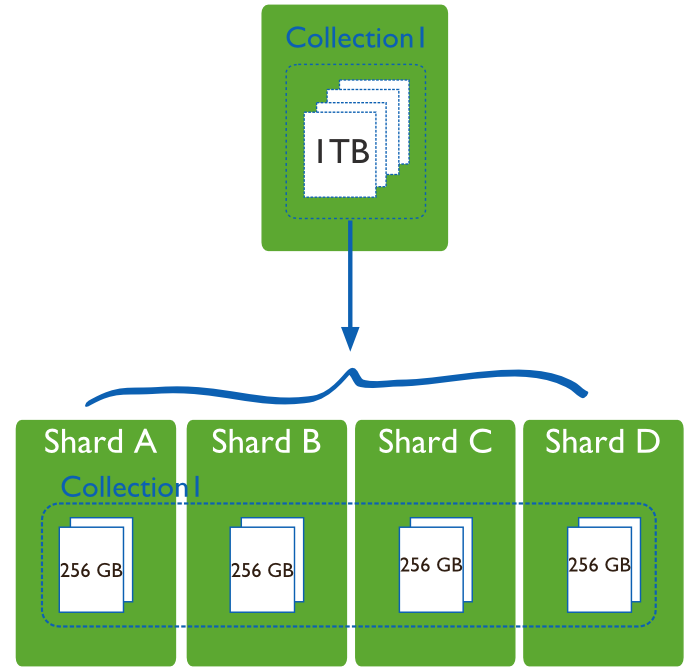
mongodb sharding 服务器架构
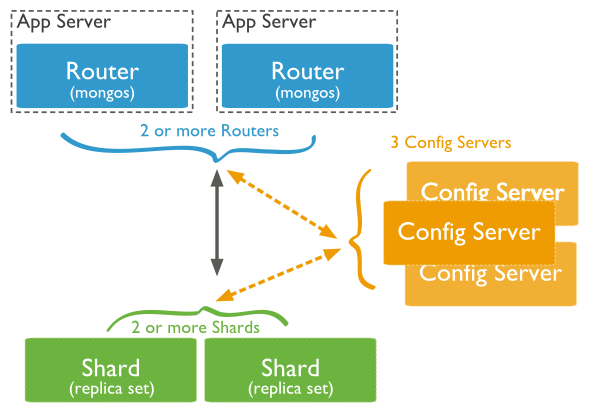
简单注解:
1 mongos 路由进程, 应用程序接入mongos再查询到具体分片。
2 config server 路由表服务。 每一台都具有全部chunk的路由信息。
3 shard为数据存储分片。 每一片都可以是复制集(replica set)。
如何部署分片集群
step 1 启动config server
|
1
2
|
mkdir /data/configdbmongod --configsvr --dbpath /data/configdb --port 27019 |
正式生产环境一般启动3个config server。 启动3个是为了做热备。
step 2 启动mongos
|
1
|
mongos --configdb cfg0.example.net:27019,cfg1.example.net:27019,cfg2.example.net:27019 |
step3 启动分片mongod
分片就是普通的mongod
|
1
|
mongod --dbpath <path> --port <port> |
step4 在mongos添加分片
用mongo 连接上mongos, 然后通过Mongo命令行输入:
添加非replica set作为分片:
sh.addShard( "mongodb0.example.net:27017" )
添加replica set作为分片:
sh.addShard( "rs1/mongodb0.example.net:27017" )
step5 对某个数据库启用分片
sh.enableSharding("<database>")
这里只是标识这个数据库可以启用分片,但实际上并没有进行分片。
step6 对collection进行分片
分片时需要指定分片的key, 语法为
sh.shardCollection("<database>.<collection>", shard-key-pattern)
例子为:
sh.shardCollection("records.people", { "zipcode": 1, "name": 1 } )
sh.shardCollection("people.addresses", { "state": 1, "_id": 1 } )
sh.shardCollection("assets.chairs", { "type": 1, "_id": 1 } )
|
1
2
|
db.alerts.ensureIndex( { _id : "hashed" } )sh.shardCollection("events.alerts", { "_id": "hashed" } ) |
最后一个为hash sharded key。 hash sharded key是为了解决某些情况下sharded key的 write scaling的问题。
如何选择shard key
1 shard key需要有高的cardinality 。 也就是shard key需要拥有很多不同的值。 便于数据的切分和迁移。
2 尽量与应用程序融合。让mongos面对查询时可以直接定位到某个shard。
3 具有随机性。这是为了不会让某段时间内的insert请求全部集中到某个单独的分片上,造成单片的写速度成为整个集群的瓶颈。用objectId作为shard key时会发生随机性差情况。 ObjectId实际上由进程ID+TIMESTAMP + 其他因素组成, 所以一段时间内的timestamp会相对集中。
不过随机性高会有一个副作用,就是query isolation性比较差。
可用hash key增加随机性。
如何查看shard信息
登上mongos
sh.status()或者需要看详细一点
sh.status({verbose:true})
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
Sharding Status --- sharding version: { "_id" : 1, "version" : 3 } shards: { "_id" : "shard0000", "host" : "m0.example.net:30001" } { "_id" : "shard0001", "host" : "m3.example2.net:50000" } databases: { "_id" : "admin", "partitioned" : false, "primary" : "config" } { "_id" : "contacts", "partitioned" : true, "primary" : "shard0000" } foo.contacts shard key: { "zip" : 1 } chunks: shard0001 2 shard0002 3 shard0000 2 { "zip" : { "$minKey" : 1 } } -->> { "zip" : 56000 } on : shard0001 { "t" : 2, "i" : 0 } { "zip" : 56000 } -->> { "zip" : 56800 } on : shard0002 { "t" : 3, "i" : 4 } { "zip" : 56800 } -->> { "zip" : 57088 } on : shard0002 { "t" : 4, "i" : 2 } { "zip" : 57088 } -->> { "zip" : 57500 } on : shard0002 { "t" : 4, "i" : 3 } { "zip" : 57500 } -->> { "zip" : 58140 } on : shard0001 { "t" : 4, "i" : 0 } { "zip" : 58140 } -->> { "zip" : 59000 } on : shard0000 { "t" : 4, "i" : 1 } { "zip" : 59000 } -->> { "zip" : { "$maxKey" : 1 } } on : shard0000 { "t" : 3, "i" : 3 } { "_id" : "test", "partitioned" : false, "primary" : "shard0000" } |
备份cluster meta information
Step1 disable balance process. 连接上Mongos
sh.setBalancerState(false)
Step2 关闭config server
Step3 备份数据文件夹
Step4 重启config server
Step5 enable balance process.
sh.setBalancerState(false)
查看balance 状态
可以通过下面的命令来查看当前的balance进程状态。先连接到任意一台mongos
|
1
2
3
4
5
6
7
8
9
|
use configdb.locks.find( { _id : "balancer" } ).pretty(){ "_id" : "balancer","process" : "mongos0.example.net:1292810611:1804289383", "state" : 2, "ts" : ObjectId("4d0f872630c42d1978be8a2e"), "when" : "Mon Dec 20 2010 11:41:10 GMT-0500 (EST)", "who" : "mongos0.example.net:1292810611:1804289383:Balancer:846930886", "why" : "doing balance round" } |
state=2 表示正在进行balance, 在2.0版本之前这个值是1
配置balance时间窗口
可以通过balance时间窗口指定在一天之内的某段时间之内可以进行balance, 其他时间不得进行balance。
先连接到任意一台mongos
|
1
2
|
use configdb.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "23:00", stop : "6:00" } } }, true ) |
这个设置让只有从23:00到6:00之间可以进行balance。
也可以取消时间窗口设置:
|
1
2
|
use configdb.settings.update({ _id : "balancer" }, { $unset : { activeWindow : true } }) |
修改chunk size
这是一个全局的参数。 默认是64MB。
小的chunk会让不同的shard数据量更均衡。 但会导致更多的Migration。
大的chunk会减少migration。不同的shard数据量不均衡。
这样修改chunk size。先连接上任意mongos
|
1
|
db.settings.save( { _id:"chunksize", value: <size> } ) |
单位是MB
何时会自动balance
每个mongos进程都可能发动balance。
一次只会有一个balance跑。 这是因为需要竞争这个锁:
|
1
|
db.locks.find( { _id : "balancer" } ) |
balance一次只会迁移一个chunk。
只有chunk最多的shard的chunk数目减去chunk最少的shard的chunk数目超过treshhold时才开始migration。
| Number of Chunks | Migration Threshold |
| Fewer than 20 | 2 |
| 21-80 |
4 |
| Greater than 80 | 8 |
上面的treshhold从2.2版本开始生效。
一旦balancer开始行动起来,只有当任意两个shard的chunk数量小于2或者是migration失败才会停止。
设置分片上最大的存储容量
有两种方式,第一种在添加分片时候用maxSize参数指定:
db.runCommand( { addshard : "example.net:34008", maxSize : 125 } )
第二种方式可以在运行中修改设定:
|
1
2
|
use configdb.shards.update( { _id : "shard0000" }, { $set : { maxSize : 250 } } ) |
删除分片
连接上任意一台mongos
STEP1 确认balancer已经打开。
STEP2 运行命令:
db.runCommand( { removeShard: "mongodb0" } )
mongodb0是需要删除的分片的名字。这时balancer进程会开始把要删除掉的分片上的数据往别的分片上迁移。
STEP3 查看是否删除完
还是运行上面那条removeShard命令
如果还未删除完数据则返回:
{ msg: "draining ongoing" , state: "ongoing" , remaining: { chunks: NumberLong(42), dbs : NumberLong(1) }, ok: 1 }
STEP4 删除unsharded data
有一些分片上保存上一些unsharded data, 需要迁移到其他分片上:
可以用sh.status()查看分片上是否有unsharded data。
如果有则显示:
{ "_id" : "products", "partitioned" : true, "primary" : "mongodb0" }
用下面的命令迁移:
db.runCommand( { movePrimary: "products", to: "mongodb1" })
只有全部迁移完上面的命令才会返回:
{ "primary" : "mongodb1", "ok" : 1 }
STEP5 最后运行命令
db.runCommand( { removeShard: "mongodb0" } )
手动迁移分片
一般情况下你不需要这么做,只有当一些特殊情况发生时,比如:
1 预分配空的集合时
2 在balancing时间窗之外
手动迁移的方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
chunks: shard0000 2 shard0001 2 { "zipcode" : { "$minKey" : 1 } } -->> { "zipcode" : 10001 } on : shard0000 Timestamp(6, 0) { "zipcode" : 10001 } -->> { "zipcode" : 23772 } on : shard0001 Timestamp(6, 1) { "zipcode" : 23772 } -->> { "zipcode" : 588377 } on : shard0001 Timestamp(3, 2) { "zipcode" : 588377 } -->> { "zipcode" : { "$maxKey" : 1 } } on : shard0000 Timestamp(5, 1)mongos> db.adminCommand({moveChunk: "contact.people", find:{zipcode:10003}, to:"192.168.1.135:20002"}){ "millis" : 2207, "ok" : 1 }mongos> sh.status()--- Sharding Status --- sharding version: { "_id" : 1, "version" : 3, "minCompatibleVersion" : 3, "currentVersion" : 4, "clusterId" : ObjectId("52ece49ae6ab22400d937891")} shards: { "_id" : "shard0000", "host" : "192.168.1.135:20002" } { "_id" : "shard0001", "host" : "192.168.1.135:20003" } databases: { "_id" : "admin", "partitioned" : false, "primary" : "config" } { "_id" : "test", "partitioned" : false, "primary" : "shard0000" } { "_id" : "contact", "partitioned" : true, "primary" : "shard0000" } contact.people shard key: { "zipcode" : 1 } chunks: shard0000 3 shard0001 1 { "zipcode" : { "$minKey" : 1 } } -->> { "zipcode" : 10001 } on : shard0000 Timestamp(6, 0) { "zipcode" : 10001 } -->> { "zipcode" : 23772 } on : shard0000 Timestamp(7, 0) { "zipcode" : 23772 } -->> { "zipcode" : 588377 } on : shard0001 Timestamp(7, 1) { "zipcode" : 588377 } -->> { "zipcode" : { "$maxKey" : 1 } } on : shard0000 Timestamp(5, 1) mongos> |
预分配空chunk
这是一种提高写效率的方法。相当于在写入真实数据之前,就分配好了数据桶,然后再对号入座。省去了创建chunk和split的时间。
实际上使用的是split命令:
db.runCommand( { split : "myapp.users" , middle : { email : prefix } } );
myapp.users 是 collection的名字。
middle参数是split的点。
split命令如下:
db.adminCommand( { split: <database>.<collection>, <find|middle|bounds> } )
find 表示查找到的记录进行分裂
bounds是指定[low, up]分裂
middle是指定分裂的点。
一个预分配chunk的例子如下:
|
1
2
3
4
5
6
|
for ( var x=97; x<97+26; x++ ){ for( var y=97; y<97+26; y+=6 ) { var prefix = String.fromCharCode(x) + String.fromCharCode(y); db.runCommand( { split : "myapp.users" , middle : { email : prefix } } ); }} |
这个预分配的目的是字母顺序有一定间隔的email, 分配到不同的chunk里。
例如aa-ag到一个chunk
ag-am到一个chunk
预分配的结果如下:
|
1
2
3
4
5
6
|
{ "email" : { "$minKey" : 1 } } -->> { "email" : "aa" } on : shard0001 Timestamp(2, 0) { "email" : "aa" } -->> { "email" : "ag" } on : shard0001 Timestamp(3, 0) { "email" : "ag" } -->> { "email" : "am" } on : shard0001 Timestamp(4, 0) { "email" : "am" } -->> { "email" : "as" } on : shard0001 Timestamp(5, 0) { "email" : "as" } -->> { "email" : "ay" } on : shard0001 Timestamp(6, 0)... |
|
1
2
3
|
{ "email" : "zm" } -->> { "email" : "zs" } on : shard0000 Timestamp(1, 257) { "email" : "zs" } -->> { "email" : "zy" } on : shard0000 Timestamp(1, 259) { "email" : "zy" } -->> { "email" : { "$maxKey" : 1 } } on : shard0000 Timestamp(1, 260) |
如何删除在sharding中删除复制集replica set的成员
假设sharding的分片是复制集,需要删除某个复制集的某个成员。
只要在复制集的设置中删除该成员即可,不需要在mongos中删除。mongos会自动同步这个配置。
例如 sharding cluster中有这个分片:
{ "_id" : "rs3", "host" : "rs3/192.168.1.5:30003,192.168.1.6:30003" }
需要删除192.168.1.6:30003这个成员。
只需要:
step 1: 在192.168.1.6:30003上运行db.shutdownServer()关闭mongod
step 2:在rs3的primary的成员192.168.1.5:30003上执行
rs.remove("192.168.1.6:30003")
如何关闭/打开balancer
关闭
sh.setBalancerState(false)
打开
sh.setBalancerState(true)
查看是否打开:
sh.getBalancerState()
新添加的分片始终不进行数据同步的问题
1 如果sharding cluster中新添加的分片始终不进行数据migration, 并出现类似日志:
migrate commit waiting for 2 slaves for
则需要重启该分片的mongod进程。
特别需要注意的是,如果某mongod进程是一个replica set的primary, 并且该replica set上只有一个mongod, 那么不能用db.shutdownServer()的方法关闭。 会报下面的错误:
no secondary is within 10 seconds of the primary,
需要用下面的命令关闭:
db.adminCommand({shutdown : 1, force : true})
2 另外一个新的分片始终部进行更新的问题:
日志里出现这样的错误:
secondaryThrottle on, but doc insert timed out after 60 seconds, continuing
通过1 将所有分片的secondary和arbitary删除掉,2 重启同步的分片解决。
找到这个问题的解决方法是看到mongo/s/d_migration.cpp里有这样一段代码
|
1
2
3
4
5
|
if ( secondaryThrottle && thisTime > 0 ) { if ( ! waitForReplication( cc().getLastOp(), 2, 60 /* seconds to wait */ ) ) { warning() << "secondaryThrottle on, but doc insert timed out after 60 seconds, continuing" << endl; }} |
这段代码含义是,要进行同步的chunk所在的分片的从服务的secondary的optime和主分片不一致,所以需要等待60秒钟的时间。
所以将要进行同步的chunk所在分片的复制集secondary和arbiter都删除掉,再重启新分片的mongod之后解决。
3 mongod的日志出现:
moveChunk cannot start migration with zero version
解决方法,在mongos上运行
mongos> use admin
switched to db admin
mongos> db.runCommand("flushRouterConfig");
{ "flushed" : true, "ok" : 1 }
转自:http://my.oschina.net/costaxu/blog/196980#OSC_h1_3
MongoDB水平分片集群(转)的更多相关文章
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
- MongoDB分片集群原理、搭建及测试详解
随着技术的发展,目前数据库系统对于海量数据的存储和高效访问海量数据要求越来越高,MongoDB分片机制就是为了解决海量数据的存储和高效海量数据访问而生. MongoDB分片集群由mongos路由进程( ...
- mongodb分片集群
第一章 1.mongodb 分片集群解释和目的 一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合.复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础. 第二章 1. ...
- mongodb分布式集群搭建手记
一.架构简介 目标单机搭建mongodb分布式集群(副本集 + 分片集群),演示mongodb分布式集群的安装部署.简单操作. 说明在同一个vm启动由两个分片组成的分布式集群,每个分片都是一个PSS( ...
- MongoDB主从复制+集群
一.读写分离的概念 读写分离,基本的原理是让主数据库处理事务性增.改.删操作(INSERT.UPDATE.DELETE),而从数据库处理SELECT查询操作.数据库复制被用来把事务性操作导致的变更同步 ...
- mongodb 搭建集群(分片+副本集)
mongodb 搭建集群(分片+副本集) 一.搭建结构图: 二.搭建步骤:
- TiDB和MongoDB分片集群架构比较
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 最近阅读了TiDB源码的说明文档,跟MongoDB的分片集群做了下简单对比. 首先展示TiDB的整体架构 M ...
- 搭建MongoDB分片集群
在部门服务器搭建MongoDB分片集群,记录整个操作过程,朋友们也可以参考. 计划如下: 用5台机器搭建,IP分别为:192.168.58.5.192.168.58.6.192.168.58.8.19 ...
- 网易云MongoDB分片集群(Sharding)服务已上线
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. MongoDB sharding cluster(分片集群)是MongoDB提供的数据在线水平扩展方案,包括 ...
随机推荐
- android基本控件学习-----RadioButton&CheckBox
RadioButton(单选框)和CheckBox(复选框)讲解: 一.基本用法和事件处理 (1)RadioButton单选框,就是只能选择其中的一个,我们在使用的时候需要将RadioButton放到 ...
- C语言中的基础知识变量探讨
C语言中的变量是编程的基础,主要有四个要素:存储类型.存储大小.存储名称和存储地址. 一.变量的要素: 1.存储类型:主要表明名变量存储的特征,主要有auto.extern.static和regist ...
- Android驱动之 Linux Input子系统之TP——A/B(Slot)协议【转】
转自:http://www.thinksaas.cn/topics/0/646/646797.html 将A/B协议这部分单独拿出来说一方面是因为这部分内容是比较容易忽视的,周围大多数用到input子 ...
- golang xorm MSSQL where查询案例
xorm官方中文文档 参考 http://xorm.io/docs/ 以sqlserver为例 先初始化连接等... engine, err := xorm.NewEngine("mssql ...
- Codeforces 761E Dasha and Puzzle(构造)
题目链接 Dasha and Puzzle 对于无解的情况:若存在一个点入度大于4,那么直接判断无解. 从根结点出发(假设根结点的深度为0), 深度为0的节点到深度为1的节点的这些边长度为2^30, ...
- IT人为了自己父母和家庭,更得注意自己的身体和心理健康
我前一阵在一家互联网公司,工作节奏是995,忙的时候,要晚上10点才能离开公司,有时候周六还得加班.自己感觉身体状况有所下降,且听说其它一个组,在体检后多少都查出问题来,细思极恐. 有时候确实忙,那么 ...
- [深入浅出iOS库]之数据库 sqlite
一,sqlite 简介 前面写了一篇博文讲如何在 C# 中使用 ADO 访问各种数据库,在移动开发和嵌入式领域也有一个轻量级的开源关系型数据库-sqlite.它的特点是零配置(无需服务器),单磁盘文件 ...
- DIV相对于父DIV底部对齐的实现方法
代码如下 <style type="text/css"> .box1 {border:1px #cccccc solid; width:500px; height:60 ...
- Mysql中delimiter作用
1. delimiter delimiter是mysql分隔符.在mysqlclient中分隔符默认是分号(:). 假设一次输入的语句较多,而且语句中间有分号,这时须要新指定一个特殊的分隔符. 2. ...
- Python批量复制和重命名文件
Python批量复制和重命名文件 示例代码 #! /usr/bin/env python # coding=utf-8 import os import shutil import time impo ...