Python-S9-Day127-Scrapy爬虫框架2
01 今日内容概要
02 内容回顾:爬虫
03 内容回顾:并发和网络
04 Scrapy框架:起始请求定制
05 Scrapy框架:深度和优先级
06 Scrapy框架:内置代理
07 Scrapy框架:自定义代理
08 Scrapy框架:解析器
01 今日内容概要
1.1 starts_url;
1.2 下载中间件;
- 代理
1.3 解析器
1.4 爬虫中间件
- 深度
- 优先级
02 内容回顾:爬虫
2.1 Scrapy依赖Twisted
2.2 Twisted是什么以及他和requests的区别?
2.2.1 requests是一个Python实现的可以伪造浏览器发送HTTP请求的模块;——封装SOCKET发送请求;
2.2.2 Twisted是基于事件循环的异步非阻塞循环网络框架; ——封装SOCKET发送请求,单线程完成并发请求;
- 非阻塞:不等待;
- 异步:回调;
- 事件循环:不断地去轮询去检查状态;
2.3 HTTP请求的本质;
- 请求头
- 请求体
2.4 Scrapy
- 创建project
- 创建爬虫
- 启动爬虫
- response对象-text、body、request
- xpath解析器——/ // .// //div[@x = "xx"] //div/text() //div/@href .extract() .extract_first()
2.5 pipeline持久化
- pipeline的5个方法
- 爬虫中:yield Item对象
- yield Request对象
- cookie
03 内容回顾:并发和网络
3.1 OSI七层模型,TCP/IP五层模型,
3.2 三次握手和四次挥手
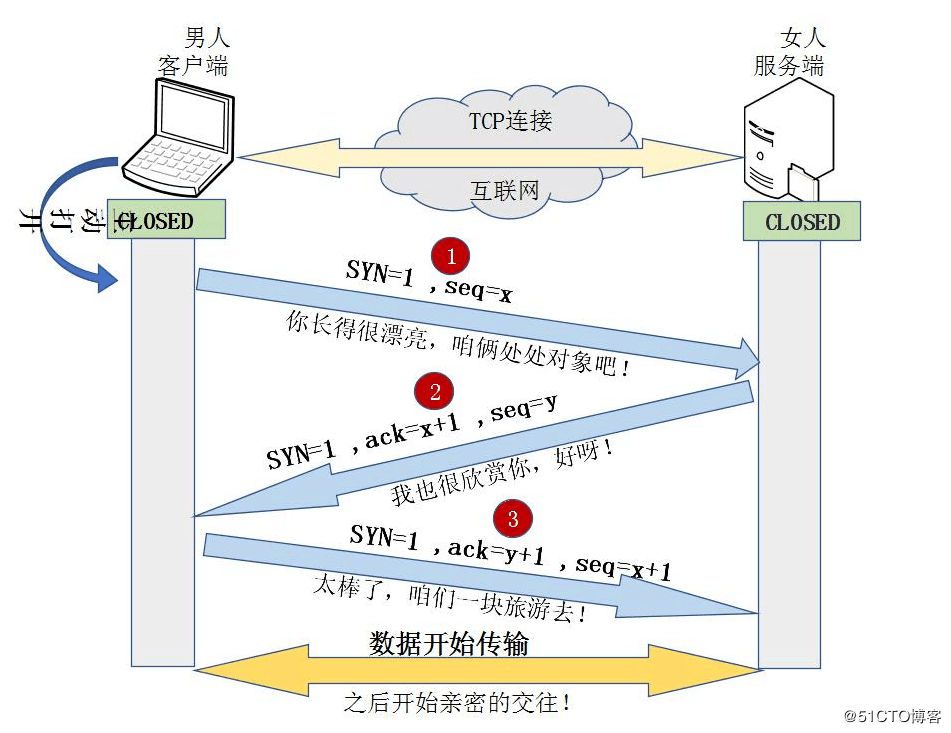
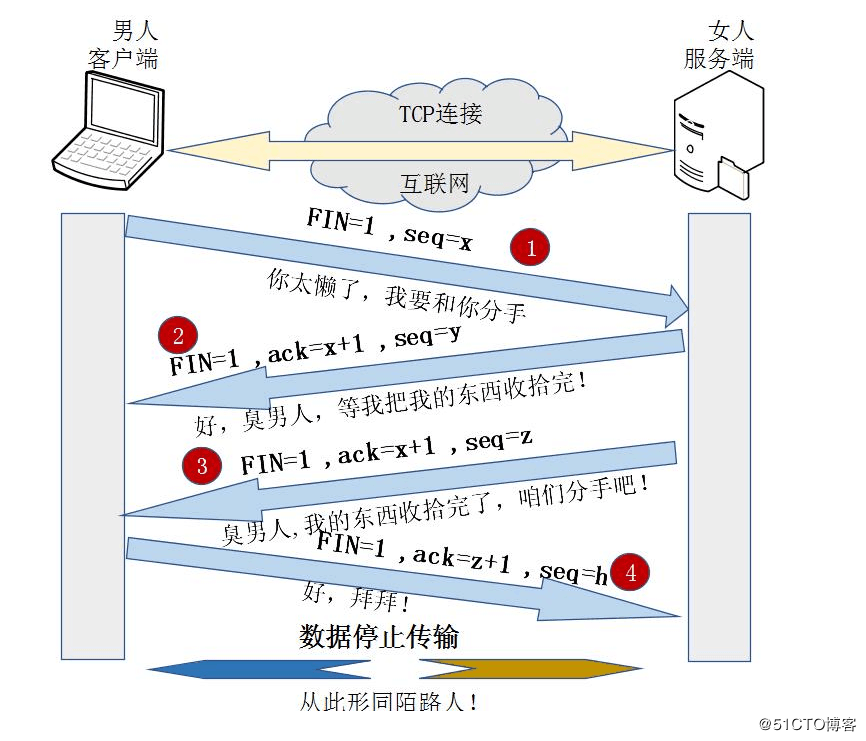
3.3 路由器和交换机的区别?
3.4 ARP协议
3.5 DNS解析
3.6 HTTP和HTTPS
3.7 进程、线程和协程的区别
3.8 GIL锁
3.9 进程如何实现进程共享?
04 Scrapy框架:起始请求定制
4.1 start_urls;
4.2 什么是可迭代对象?
05 Scrapy框架:深度和优先级
5.1 深度
- 最开始是0
- 每次yield时候,会根据原来的请求中的depth + 1
- 通过配置DEPTH_LIMIT 深度控制
5.2 优先级
- 请求被下载的优先级——深度*配置 DEPTH_PRIORITY
- 配置DEPTH_PROORITY
06 Scrapy框架:内置代理
6.1 Scrapy内置代理;
6.2 Scrapy自定义代理;
6.3 学习到一定程度,就要读源码;
07 Scrapy框架:自定义代理
7.1 自定义代理池
7.2 商业产品,阿布云
08 Scrapy框架:解析器
8.1 xpath解析器
8.2 css解析器
Python-S9-Day127-Scrapy爬虫框架2的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python的两个爬虫框架PySpider与Scrapy安装
Python的两个爬虫框架PySpider与Scrapy安装 win10安装pyspider: 最好以管理员身份运行CMD,不然可能会出现拒绝访问文件夹的情况! pyspider:pip instal ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
随机推荐
- Hadoop 分片、分组与排序
首先需要明确的是,hadoop里的key一定要是可排序的,要么key自身实现了WritableComparator接口,要么有一个排序类可以对key进行排序.如果key本身不实现WritableCom ...
- C#环形缓冲区(队列)完全实现
公司项目中经常设计到串口通信,TCP通信,而且大多都是实时的大数据的传输,然后大家都知道协议通讯肯定涉及到什么,封包.拆包.粘包.校验--什么鬼的概念一大堆,说简单点儿就是要一个高效率可复用的缓存区. ...
- VMware Workstation Pro 11、12 密钥
11:1F04Z-6D111-7Z029-AV0Q4-3AEH8 12:5A02H-AU243-TZJ49-GTC7K-3C61N
- linux 命令——8 cp (转)
cp 命令用来复制文件或者目录,是Linux系统中最常用的命令之一.一般情况下,shell会设置一个别名,在命令行下复制文件时,如果目标文件已经存在, 就会询问是否覆盖,不管你是否使用-i参数.但是如 ...
- libav(ffmpeg)简明教程(2)
距离上一次教程又过去了将近一个多月,相信大家已经都将我上节课所说的东西所完全消化掉了. 这节课就来点轻松的,说说libav的命令使用吧. 注:遇到不懂的或者本文没有提到的可以用例如命令后加 --hel ...
- 关于SIGSEGV错误及处理方法
http://blog.csdn.net/brace/article/details/1102422 今天编程遇到了SIGSEGV错误,比较困惑,所以找了些资料,总结一下: (1)官方说法是: SIG ...
- Problem G: 角谷步数
Problem G: 角谷步数 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 78 Solved: 28[Submit][Status][Web Bo ...
- VC-基础-WebBrowser控件中弹出新网页窗口
用webbrowser控件浏览网页时,常弹出新的网页窗口,若不做任何控制的话,会在默认浏览器(一般是IE)中打开,这样就在新的窗口打开了,原程序就很难控制了,且存在webbrowser控件和IE的se ...
- js call 函数
function bb(){ console.log(this.x) } function cc(){ this.x = 200 } var p = new cc(); bb.call(p) // ...
- GNU汇编程序框架
汇编的作用:1.对芯片进行初始化 2. 和C混合编程提升C的运行效率 .section .data < 初始化的数据> .section .bss <未初始化的数据> .sec ...