Spark:如何替换sc.parallelize(List(item1,item2)).collect().foreach(row=>{})为并行?
代码场景:
1)设定的几种数据场景,遍历所有场景:依次统计满足每种场景条件下的数据,并把统计结果存入hive;
2)已有代码如下:
case class IndoorOTTCalibrateBuildingVecotrLegend(oid: Int, minHeight: Int, maxHeight: Int, minGridIDCount: Int, maxGridIDCount: Int, heightType: Int) extends Serializable
// 实例化建筑物区间段:按照栅格的个数(面积)、楼的高度(商场等场景)来划分场景
val buildingHeightLegends = List(
IndoorOTTCalibrateBuildingVecotrLegend(1, 1, 30, 1, 21, BuildingCalibrateHeightType.HeightType1.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(2, 1, 30, 21, 45, BuildingCalibrateHeightType.HeightType2.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(3, 1, 30, 45, 100, BuildingCalibrateHeightType.HeightType3.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(4, 30, 50, 1, 21, BuildingCalibrateHeightType.HeightType4.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(5, 30, 50, 21, 45, BuildingCalibrateHeightType.HeightType5.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(6, 30, 50, 45, 100, BuildingCalibrateHeightType.HeightType6.toString.toInt),
IndoorOTTCalibrateBuildingVecotrLegend(7, 50, 5000, 1, 100, BuildingCalibrateHeightType.HeightType7.toString.toInt)
)
spark.sparkContext.parallelize(buildingHeightLegends).collect().foreach(buildingHeightLegend => {
generateSampleBySenceType(spark, p_city, p_hour_start, p_hour_end, p_fpb_day, p_day_sample, linkLossCalibrateParameter, buildingHeightLegend)
})
备注:
在generateSampleBySenceType()函数内部包含有:
spark.sql(s"""
|xxx
|where t10.heihgt>=${buildingHieghtLegend.MinHeight} and t10.height<${buildingHieghtLegend.MaxHeight}
|and t10.gridcount<=${buildingHieghtLegend.MinGridIDCount} and t10.gridcount>${buildingHieghtLegend.MaxGridIDCount}
|""".stripMargin)
如果把代码修改:
val buildingHeightLegends_df = spark.sqlContext.createDataFrame(buildingHeightLegends)
buildingHeightLegends_df.createOrReplaceTempView("temp_buildingheightlegends") sql(s"""|select * from temp_buildingheightlegends""".stripMargin).repartition(buildingHeightLegends.length).foreachPartition(rows => {
for (row <- rows) {
val buildingHeightLegend = new IndoorOTTCalibrateBuildingVecotrLegend(
row.getAs[Int]("oid"),
row.getAs[Int]("minheight"),
row.getAs[Int]("maxheight"),
row.getAs[Int]("mingrididcount"),
row.getAs[Int]("maxgrididcount"),
row.getAs[Int]("heighttype"))
generateSampleBySenceType(spark, p_city, p_hour_start, p_hour_end, p_fpb_day, p_day_sample, linkLossCalibrateParameter, buildingHeightLegend)
}
})
则会提示:generateSampleBySenceType()内部sql代码位置抛出SparkSession为NULL的异常。
修改方案:
把buildingHeightLegends注册为临时表temp_buildingHeightLegends,去掉外层的foreach,之后在generateSampleBySenceType()内部把temp_buildingHeightLegends与其他结果集合进行cross join:
测试代码如下:
-- 场景表
CREATE TABLE [dbo].[test_senceitems](
[sencetype] [int] NULL,
[minheight] [int] NULL,
[maxheight] [int] NULL,
[mingridcount] [int] NULL,
[maxgridcount] [int] NULL
)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (1, 1, 30, 1, 21)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (2, 1, 30, 21, 45)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (3, 1, 30, 45, 100)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (4, 30, 50, 1, 21)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (5, 30, 50, 21, 45)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (6, 30, 50, 45, 100)
INSERT [dbo].[test_senceitems] ([sencetype], [minheight], [maxheight], [mingridcount], [maxgridcount]) VALUES (7, 50, 5000, 1, 100) -- 业务过滤统计表
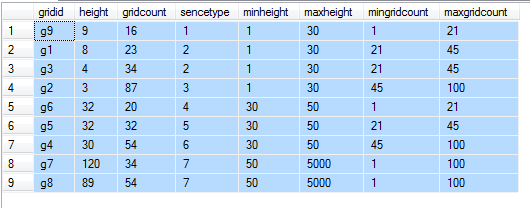
CREATE TABLE [dbo].[test_grid](
[gridid] [nvarchar](50) NULL,
[height] [int] NULL,
[gridcount] [int] NULL
) INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g1', 8, 23)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g2', 3, 87)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g3', 4, 34)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g4', 30, 54)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g5', 32, 32)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g6', 32, 20)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g7', 120, 34)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g8', 89, 54)
INSERT [dbo].[test_grid] ([gridid], [height], [gridcount]) VALUES (N'g9', 9, 16)
替换generateSampleBySenceType()内部sql(s"""|""".stripMargin)代码类似如下:
select t10.*,t11.*
from test_grid t10
cross join test_senceitems t11
where t10.height>=t11.minheight and t10.height<t11.maxheight
and t10.gridcount>=t11.mingridcount and t10.gridcount<t11.maxgridcount
Spark:如何替换sc.parallelize(List(item1,item2)).collect().foreach(row=>{})为并行?的更多相关文章
- 单表千亿电信大数据场景,使用Spark+CarbonData替换Impala案例
[背景介绍] 国内某移动局点使用Impala组件处理电信业务详单,每天处理约100TB左右详单,详单表记录每天大于百亿级别,在使用impala过程中存在以下问题: 详单采用Parquet格式存储,数据 ...
- arrayObj.splice(start, deleteCount, [item1[, item2[, . . . [,itemN]]]])
测试方法 function test(){ var arr = [0,1,2,3]; arr.splice(1,1,'a');//case console.dir(arr); } case1: arr ...
- Spark(二)【sc.textfile的分区策略源码分析】
sparkcontext.textFile()返回的是HadoopRDD! 关于HadoopRDD的官方介绍,使用的是旧版的hadoop api ctrl+F12搜索 HadoopRDD的getPar ...
- Spark算子--first、count、reduce、collect、lookup
转载请标明出处http://www.cnblogs.com/haozhengfei/p/4b8582c8dde1529abb11e4ccc8296171.html first.count.reduce ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- 【spark】常用转换操作:sortByKey()和sortBy()
1.sortByKey() 功能: 返回一个根据键排序的RDD 示例 val list = List(("a",3),("b",2),("c" ...
- Spark_Transformation和Action算子
Transformation 和 Action 常用算子 一.Transformation 1.1 map 1.2 filter 1.3 flatMap ...
- 入门大数据---Spark_Transformation和Action算子
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
随机推荐
- IPFS网络是如何运行的(p2p网络)
IPFS是一个p2p网络,先来看看BitTorrent的p2p网络是如何工作的? 想要bt下载一个文件,首先你需要一个种子文件torrent,种子文件包含至少一个 Tracker(一台服务器地址)信息 ...
- numpy用法小结
前言 个人感觉网上对numpy的总结感觉不够详尽细致,在这里我对numpy做个相对细致的小结吧,在数据分析与人工智能方面会有所涉及到的东西在这里都说说吧,也是对自己学习的一种小结! numpy用法的介 ...
- python安装第三方库
在编写爬虫程序时发现unsolved import 一时不解,以为是ide出问题了,其实是没有安装第三方库导致的. 于是到https://pypi.python.org/pypi/requests/去 ...
- Java并发系列[9]----ConcurrentHashMap源码分析
我们知道哈希表是一种非常高效的数据结构,设计优良的哈希函数可以使其上的增删改查操作达到O(1)级别.Java为我们提供了一个现成的哈希结构,那就是HashMap类,在前面的文章中我曾经介绍过HashM ...
- java实现循环链表的增删功能
java实现循环链表的增删功能,完整代码 package songyan.test.demo; public class Demo { // java 实现循环链表 public static voi ...
- 【Python】 更多数据类型collections&简易数据文件shelve
■collections collections在python内建的数据类型基础上新增一些实用的数据类型,其目的在于增加代码的可读性?(虽然我自己没怎么用过..) ① deque 双端队列 q = d ...
- 大数据 --> 淘宝异构数据源数据交换工具 DataX
淘宝异构数据源数据交换工具 DataX DataX是什么? DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesys ...
- 设计模式 --> (16)观察者模式
观察者模式 定义对象间的 一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新.它还有两个别名,依赖(Dependents),发布- 订阅(Publish-Sub ...
- Algorithm --> 爬楼梯求最大分数
爬楼梯求最大分数 如下图,最大分数是: 10+20+25+20=75. 要求: 1.每次只能走一步或者两步: 2.不能连续三步走一样的,即最多连续走两次一步,或者连续走两次两步: 3.必 ...
- java.lang.Object学习总结