【Spark工作原理】Spark任务调度理解
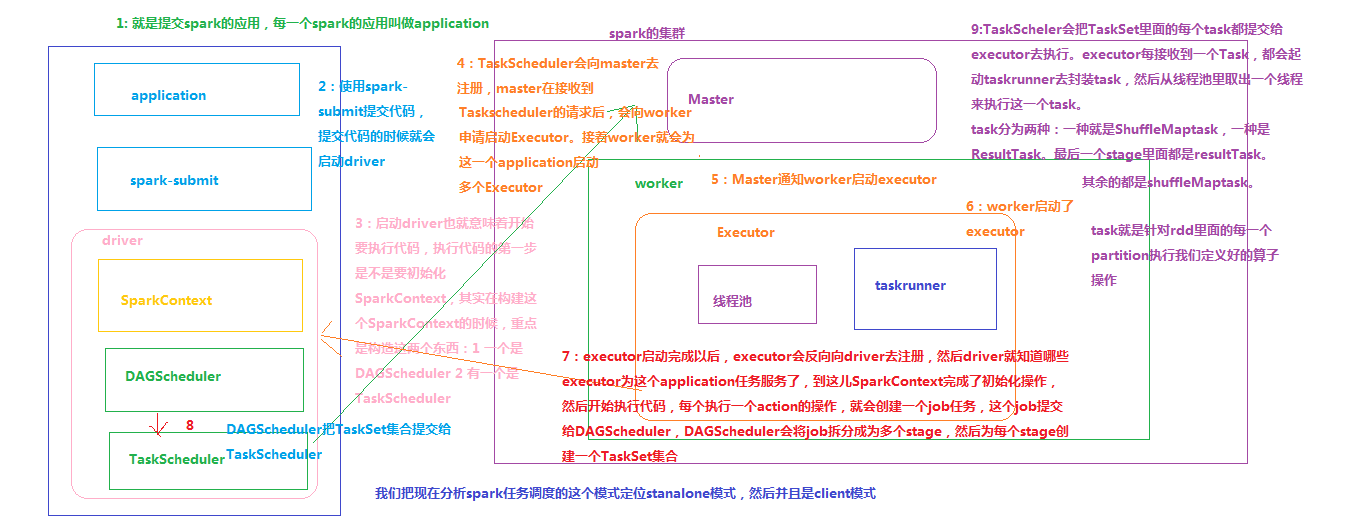
Spark内部有若干术语(Executor、Job、Stage、Task、Driver、DAG等),需要理解并搞清其内部关系,因为这是性能调优的基石。
节点类型有:
1. Master 节点: 常驻master进程,负责管理全部worker节点。
2. Worker 节点: 常驻worker进程,负责管理executor 并与master节点通信。
Dirvier:官方解释为: The process running the main() function of the application and creating the SparkContext。即理解为用户自己编写的应用程序
Executor:执行器:
在每个Worker节点上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个job都有各自独立的Executor。
Executor是一个执行Task的容器。它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,有点类似hadoop的tasktracker和task。
也就是说,Executor是一个应用程序运行的监控和执行容器。Executor的数目可以在submit时,由 --num-executors (on yarn)指定.
Job:
包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action算子的执行会生成一个job。
用户提交的Job会提交给DAGScheduler,Job会被分解成Stage和Task。
Stage:
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。
Stage的划分简单来说是以shuffle和result这两种类型来划分。
在Spark中有两类task,一类是shuffleMapTask,一类是resultTask。第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据:shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。例如:
1) rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;
2) 如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。
如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
spark中会引起shuffle的算子有:
去重distinct、聚合reduceByKey/groupByKey/xxByKey、排序sortByKey、表关联join、重分区Repartition/Coalesce(shuffle=true)等。
Task:
stage 下的单个任务执行单元。
一个rdd有多少个partition,就会有多少个task,因为每一个 task 只是处理一个partition上的数据。所以有时为提高执行并行度,使用Repartition或Coalesce(shuffle=true),增多partition数量,从而增多task数量
【Spark工作原理】Spark任务调度理解的更多相关文章
- How Javascript works (Javascript工作原理) (五) 深入理解 WebSockets 和带有 SSE 机制的HTTP/2 以及正确的使用姿势
个人总结: 1.长连接机制——分清Websocket,http2,SSE: 1)HTTP/2 引进了 Server Push 技术用来让服务器主动向客户端缓存发送数据.然而,它并不允许直接向客户端程序 ...
- 【Spark工作原理】stage划分原理理解
Job->Stage->Task开发完一个应用以后,把这个应用提交到Spark集群,这个应用叫Application.这个应用里面开发了很多代码,这些代码里面凡是遇到一个action操作, ...
- 49、Spark Streaming基本工作原理
一.大数据实时计算介绍 1.概述 Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架.它的底层,其实,也是基于我们之前讲解的Spark Core的. 基本 ...
- 通过一个小故事,理解 HTTPS 工作原理
本文摘录参考: 细说 CA 和证书(主要讲解 CA 的使用) 数字签名是什么?(简单理解原理) 深入浅出 HTTPS 工作原理(深入理解原理) HTTP 协议由于是明文传送,所以存在三大风险: 1.被 ...
- 理解 HTTPS 工作原理(公钥、私钥、签名、数字证书、加密、认证)(转)
本文摘录参考: 细说 CA 和证书(主要讲解 CA 的使用) 数字签名是什么?(简单理解原理) 深入浅出 HTTPS 工作原理(深入理解原理) HTTP 协议由于是明文传送,所以存在三大风险: 1.被 ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- HTTP协议请求响应过程和HTTPS工作原理
HTTP协议 HTTP协议主要应用是在服务器和客户端之间,客户端接受超文本. 服务器按照一定规则,发送到客户端(一般是浏览器)的传送通信协议.与之类似的还有文件传送协议(file transfer p ...
- Protocol Buffers工作原理
这里记录一下学习与使用Protocol Buffer的笔记,优点缺点如何使用这里不再叙述,重点关注与理解Protocol Buffers的工作原理,其大概实现. 我们经常使用Protocol Buff ...
- kube-proxy IPVS 模式的工作原理
原文链接:https://fuckcloudnative.io/posts/ipvs-how-kubernetes-services-direct-traffic-to-pods/ Kubernete ...
随机推荐
- Delphi TXLSReadWriteII导出Excel
TXLSReadWriteII导出Excle (有点复杂,可以自己简化一下,直接从项目中抓取的) procedure TformSubReport.DataToExcel(_Item: Integer ...
- android rc文件分析
service vold /system/bin/vold \ --blkid_context=u:r:blkid:s0 --blkid_untrusted_context=u:r:bl ...
- 最新ceph集群常用命令梳理
结合网络.官网.手动查询等多方渠道,整理ceph维护管理常用命令,并且梳理常规命令在使用过程中的逻辑顺序.另外整理期间发现ceph 集群的命令体系有点乱,详细情况各自体验. 一:ceph集群启动.重启 ...
- Linux学习-linux系统下安装jdk和tomcat,以及遇到的问题清单
安装JDK 1. 在usr目录下建立java安装目录 cd /usr mkdir java 2.下载jdk包 登录网址:http://www.oracle.com/technetwork/java ...
- SSM框架整合的其它方式
---------------------siwuxie095 SSM 框架整合的其它方式 1.主要是整合 Spring ...
- eclipse使用lomnok无效
把下载好的jar包去掉版本号放到与eclipse.exe同级目录 修改sts.ini或者eclipse.ini 在最后面加上: -javaagent:lombok.jar-Xbootclasspath ...
- 【Android】异步加载布局探索
最近在做的项目页面复杂导致布局嵌套多层,而且又使用了百分比布局(可能主要是这个原因)导致页面加载的时候主线程会被阻塞, 那要想减少主线程阻塞,一来就是简化布局,减轻LayoutInflater的负担, ...
- oracle数据库卸数及ddl导出
一.数据库卸数脚本 还是比较明了的,一看就明白. unloaddevice.sh sqlplus atmpbat/atmpbat@inter @"./unloaddevice.sql&quo ...
- 使用android访问SQLServer数据库
1.SQL驱动 下载可以支持android的SQL驱动,下载地址http://sourceforge.net/projects/jtds/files/ 注意只能下载1.2.7版本.android不支持 ...
- tensorflow学习之(三)Varible 变量的使用
#Varible 变量的使用 使用变量进行自加 import tensorflow as tf state = tf.Variable(0,name='counter') #定义一个变量,赋值为0,且 ...