hadoop分布式集群搭建(2.9.1)
1、环境
操作系统:ubuntu16
jdk:1.8
hadoop:2.9.1
机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.168.199.90
2、搭建步骤
2.1 修改主机名hostname,三台机器分别执行如下命令,依次填入master,node1,node2
sudo vim /etc/hostname

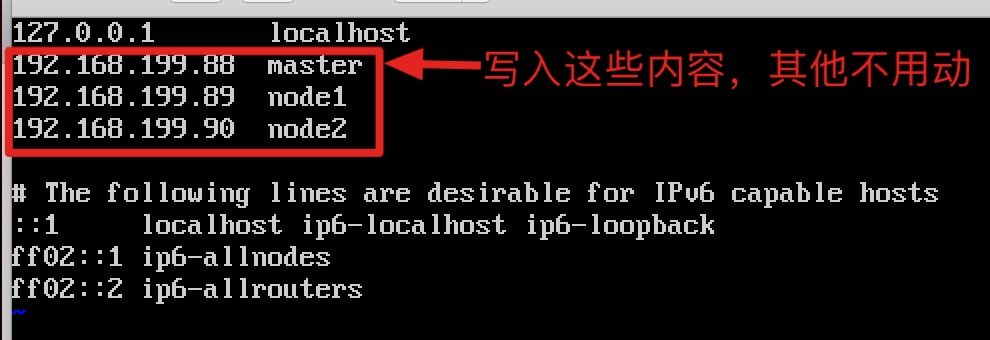
2.2 修改hosts文件,三台机器依次执行
sudo vim /etc/hosts
2.3 修改环境变量,三台依次执行
vim /etc/profile,然后source /etc/profile使之生效

JAVA_HOME是java的安装路径,如果不知道自己的java安装路径,请参考如下操作:

which java定位到的是java程序的执行路径,而不是安装路径,经过两次-lrt最后的输出才是安装路径
2.3 配置master对node1和node2的免密登陆
效果就是在master上输入ssh node1即可登陆node1,否则开启集群服务时,master与node无法连接,会报出connection refused
2.3.1 配置前,先确保安装了openssh-server,默认是不安装的
输入dpkg --list | grep ssh,如果没有openssh-server,执行以下命令安装:
sudo apt-get install openssh-server
2.3.2 每台机器执行ssh-keygen -t rsa,然后回车
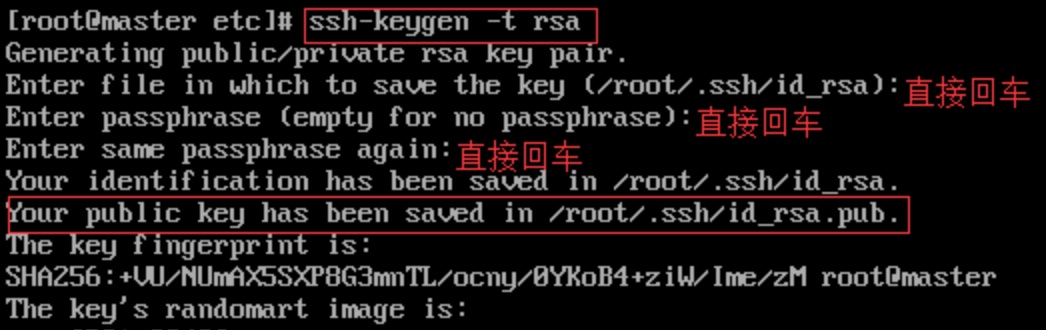
生成的公钥私钥都保存在~/.ssh下
2.3.3、在master上将公钥放入authorized_keys,命令如下:
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
2.3.4、将master上的authorized_keys放到其它机器上
scp ~/.ssh/authorized_keys root@node1:~/.ssh/
scp ~/.ssh/authorized_keys root@node2:~/.ssh
2.3.5、测试是否成功
2.4 下载hadoop及修改配置文件在master上执行即可,修改完再复制到其他机器上
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-2.9.1.tar.gz (我下载时这里的稳定版是2.9.1,如果更新了,下载相应的tar.gz包即可)
解压:tar zxf hadoop-2.9.1.tar.gz
2.5 创建HDFS存储目录
进入解压后的文件夹: cd hadoop2.9.1
mkdir hdfs
cd hdfs
mkdir name data tmp
./hdfs/name --存储namenode文件
./hdfs/data --存储数据
./hdfs/tmp --存储临时文件
2.6 修改xml配置文件
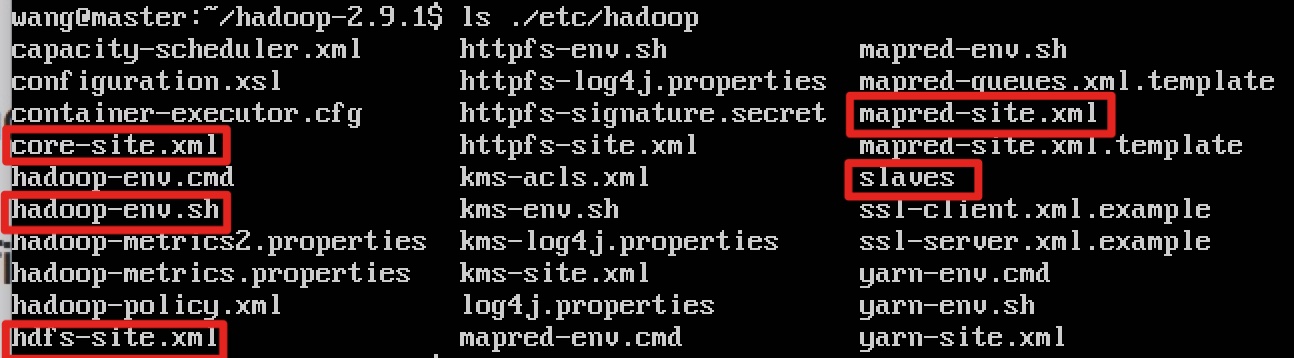
需要修改的xml文件在hadoop2.9.1/etc/hadoop/下
主要有5个文件要修改:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
2.6.1、vim hadoop-env.sh,填写的是java的安装路径

2.6.2、vim core-site.xml,configuration标签中插入如下内容

2.6.3、vim hdfs-site.xml
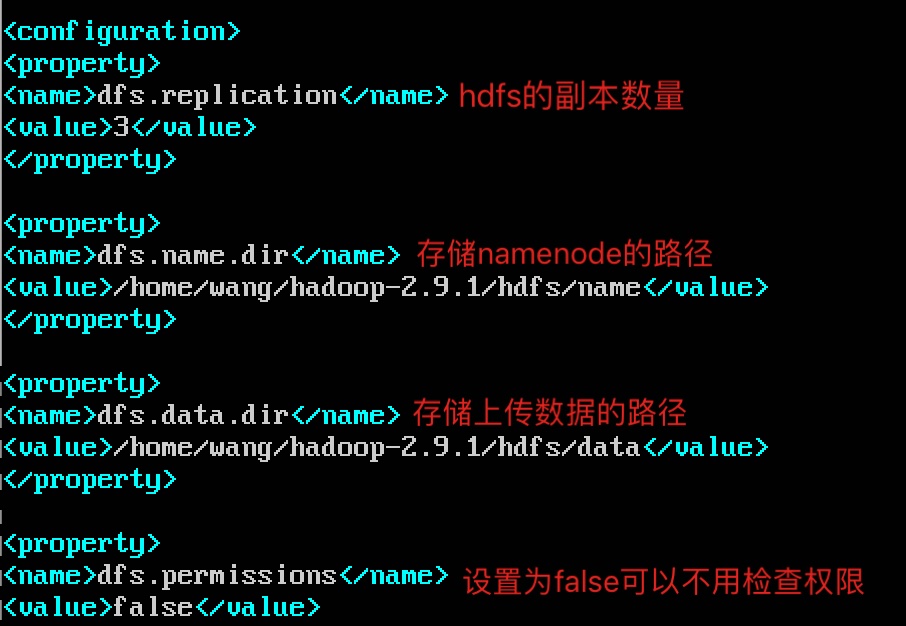
2.6.4、vim mapred-site.xml

2.6.5、vim yarn-site.xml

2.6.6、vim slaves,将里面的localhost删掉,写入从节点主机名
2.7 将hadoop文件夹远程拷贝到node节点上
scp -r hadoop-2.9.1 wang@node1:/home/wang/
scp -r hadoop-2.9.1 wang@node2:/home/wang/
2.8 启动hadoop
2.8.1 启动之前要先格式化,格式化命令:hadoop namenode -format
因为master是namenode,node1和node2都是datanode,所以只在master上执行
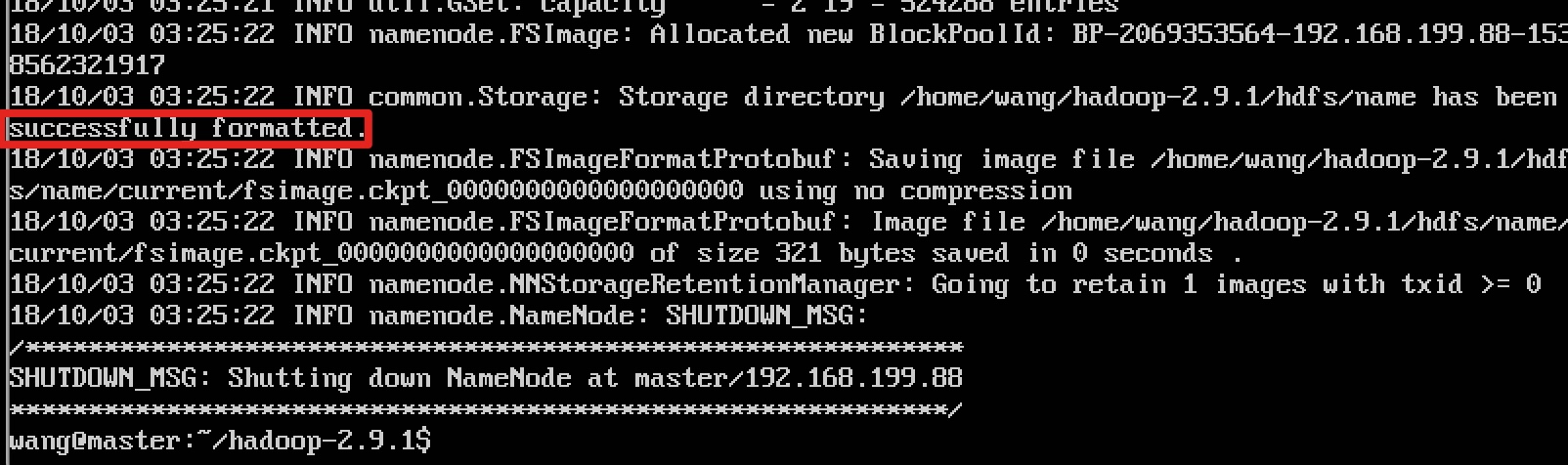
如果出现successfully formatted,即表示格式化成功,会看到name下多出current文件夹

2.8.2 格式化成功后,在master上执行命令:start-all.sh,启动后可用jps命令查看开启的进程,master上有四个进程,node上是三个

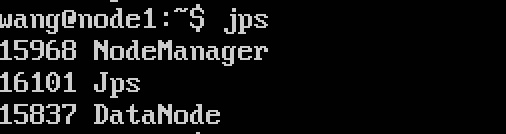
如果不是,请从头到尾再检查一下配置文件,看是否有拼错的地方
另外还可以在浏览器查看:192.168.199.88:50070
(masterIP,50070固定端口)
hadoop分布式集群搭建(2.9.1)的更多相关文章
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- [过程记录]Centos7 下 Hadoop分布式集群搭建
过程如下: 配置hosts vim /etc/hosts 格式: ip hostname ip hostname 设置免密登陆 首先:每台主机使用ssh命令连接其余主机 ssh 用户名@主机名 提示是 ...
- Centos 7下Hadoop分布式集群搭建
一.关闭防火墙(直接用root用户) #关闭防火墙 sudo systemctl stop firewalld.service #关闭开机启动 sudo systemctl disable firew ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
随机推荐
- Java notepad++ 配置
1.下载安装插件 NppExec https://nchc.dl.sourceforge.net/project/npp-plugins/NppExec/NppExec%20Plugin%20v0.6 ...
- 剑指Offer 7. 斐波那契数列 (递归)
题目描述 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0). n<=39 题目地址 https://www.nowcoder.com/prac ...
- Beta周王者荣耀交流协会第四次Scrum会议
1.立会照片 成员王超,高远博,冉华,王磊,王玉玲,任思佳,袁玥全部到齐. master:任思佳 2.时间跨度: 2017年11月13日 11:40 — 12:10 ,总计30分钟. 3.地点: 一食 ...
- 3.1 unittest简介
3.1 unittest简介 前言 熟悉java的应该都清楚常见的单元测试框架Junit和TestNG.python里面也有单元测试框架-unittest,相当于是一个python版的junit.py ...
- Linux 堆溢出原理分析
堆溢出与堆的内存布局有关,要搞明白堆溢出,首先要清楚的是malloc()分配的堆内存布局是什么样子,free()操作后又变成什么样子. 解决第一个问题:通过malloc()分配的堆内存,如何布局? 上 ...
- 解决使用C/C++配置ODBC链接使用SQLConnect返回-1
VS中建立空项目使用ODBC连接时,SQLConnect函数总是返回-1,mysql和命令行连接数据库都是没问题的 retcode = SQLConnect(hdbc, (SQLCHAR*)" ...
- PythonStudy——可变与不可变 Variable and immutable
ls = [10, 20, 30] print(id(ls), ls) ls[0] = 100 print(id(ls), ls) print(id(10)) print(id(20)) print( ...
- jsp后台取出request请求头
请求发到a2这个servlet 在这个servlet中请求转发到index.jsp 在jsp中如下的java代码 Enumeration headernames=request.getHeaderNa ...
- DL服务器主机环境配置(ubuntu14.04+GTX1080+cuda8.0)解决桌面重复登录
DL服务器主机环境配置(ubuntu14.04+GTX1080+cuda8.0)解决桌面重复登录 前面部分是自己的记录,后面方案部分是成功安装驱动+桌面的正解 问题的开始在于:登录不了桌面,停留在重复 ...
- Day 06 元组,字典,集合
元组 一.定义:参数为for可以循环的对象(可迭代对象) t2 = tuple("123")print(t2, type(t2))t3 = tuple([1, 2, 3])prin ...