selenium 淘宝登入反爬虫解决方案(亲测有效)
前言
目前在对淘宝进行数据爬取的时候都会碰到,登入时的滑块问题,无论是手动还是脚本都不成功。这里的很重要一个原因是很多的网站都对selenium做了反爬虫机制。接下来是笔者参考网上的网友们的方法亲自测试的一个方法,希望可以帮助到大家。注意这里使用的浏览器是Chrome。所以使用的驱动也是chromedriver
一,淘宝反扒js
在淘宝登入页面加载的js中,可以看到怎么一行代码,如下图:
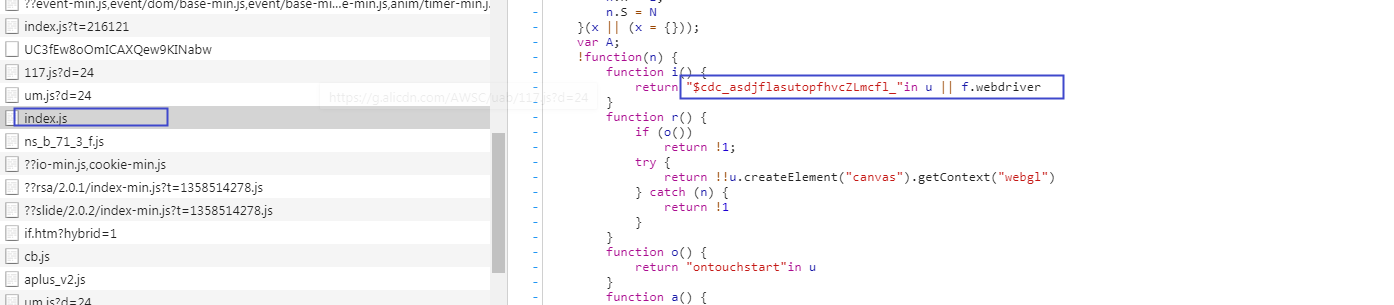
上图的这一行代码就对selenium进行了检测。所以我们只需要修改驱动的改行代码就可以。
二,修改chromedriver.exe
vim chromedriver.exe
cdc_通过键入/cdc_并按下来搜索return。- 按下启用编辑
a。 - 删除任意数量的内容
$cdc_lasutopfhvcZLmcfl并用等量字符替换已删除的内容。如果不这样做,chromedriver将会失败。 - 完成编辑后,按
esc。 - 要保存更改并退出,请键入
:wq!并按return。
完成上述步骤就可以了:下图是笔者的修改,就将最后一个字符l 改为 a

三,测试代码
注意下面代码的:chrome_option 以开发者模式,否则依然需要滑块
#!/usr/bin/env python
# -*- coding: utf-8 -*- from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC chrome_option = webdriver.ChromeOptions()
chrome_option.add_experimental_option('excludeSwitches', ['enable-automation']) # 以开发者模式 driver = webdriver.Chrome(options=chrome_option)
wait = WebDriverWait(driver, 10) def search():
driver.get('https://www.taobao.com')
try:
search_input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#q'))
)
search_submit = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))
)
finally:
pass
search_input.send_keys('美食'.decode('utf-8'))
search_submit.click()
login() def login():
try:
login_before = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#J_QRCodeLogin > div.login-links > a.forget-pwd.J_Quick2Static'))
)
login_before.click() username = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#TPL_username_1'))
)
password = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#TPL_password_1'))
)
username.send_keys('xxxxx') # 用户名
password.send_keys('xxxxx') # 密码
login_submit = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#J_SubmitStatic'))
)
login_submit.click()
finally:
pass def main():
search() if __name__ == '__main__':
main()
selenium 淘宝登入反爬虫解决方案(亲测有效)的更多相关文章
- python获取淘宝登入cookies
重点:去新浪微博登入接口登入 一.代码 # coding=utf-8 import requests from selenium.webdriver.common.by import By from ...
- pyppeteer硬钢掉淘宝登入的滑块验证
完整代码我也不好公布,我可以给你们思路,以及部分代码动动脑子看看文档应该也能搞定 一.初始化Chromium浏览器相关属性 browser = await pyppeteer.launch({'hea ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- MyEclipse8.6启动后提示内存不足的解决方案(亲测,完美解决)
转自:http://www.bubuko.com/infodetail-1625857.html 最近可能由于公司项目大了,启动MyEclipse后经常提示内存不足的警告框,如下: 其实点击close ...
- Python攻破淘宝网各类反爬手段,采集淘宝网ZDB(女用)的销量!
声明: 由于某些原因,我这里会用手机代替,其实是一样的! 环境: windows python3.6.5 模块: time selenium re 环境与模块介绍完毕后,就可以来实行我们的操作了. 第 ...
- Selenium与phantomJS 登入豆瓣 有bug
# -*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.common.keys import Key ...
- selenium 淘宝商品分页
通过这行代码确定每页的下一页,因为从淘宝的第4页 xpath就匹配不出下一页的位置#这是面向对象写法,不用的把self. 去掉即可next_button = self.driver.find_elem ...
- office2010使用mathtype时,出现未找到MathPage.WLL解决方案--亲测有用
安装mathtype时,出现如下错误: 解决方案: 参考此网址中的内容:http://www.mathtype.cn/wenti/word-jianrong.html 首先需要找到在Word加载的两个 ...
- secureCRT无操作自动登出时间修改(亲测可用)
转自:http://blog.sina.com.cn/s/blog_6bcf42010102vlt9.html secureCRT连接机器经常会因为一段时间无操作就退出了,提示timed out wa ...
随机推荐
- Redux 入门到高级教程
Redux 是 JavaScript 状态容器,提供可预测化的状态管理. (如果你需要一个 WordPress 框架,请查看 Redux Framework.) Redux 除了和 React 一起用 ...
- Spring-boot之 rabbitmq
今天学习了下spring-boot接入rabbitmq. windows下的安装:https://www.cnblogs.com/ericli-ericli/p/5902270.html 使用博客:h ...
- Java多线程:volatile 关键字
一.内存模型的相关概念 大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入.由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存 ...
- 利用SEH防范BP(int 3)断点
利用SEH技术实现反跟踪,这个方法比单纯用判断API函数第一个字节是否为断点更加有效,可以防止在API函数内部的多处地址设置断点 通过int 3指令故意产生一个异常,从而让系统转入自己的异常处理函数, ...
- macos下golang 1.9配置
1.golang最新版本下载地址 https://golang.org/dl/ (下载与安装过程此处省略一万字) 注意,go1.9与以往版本安装不同,直接安装到/usr/local/go目录下,而/u ...
- 【分享】Asp.net Core相关教程及开源项目
入门 全新的ASP.NET: https://www.cnblogs.com/Leo_wl/p/5654828.html 在IIS上部署你的ASP.NET Core项目: https://www.c ...
- [tomcat启动报错]registered the JDBC driver [com.alibaba.druid.proxy.DruidDriver] but failed to unregister it when the web application was stopped
环境:一个tomcat ,一个工程配置了多数据源,在启动的时候报如下错误: SEVERE: The web application [/qdp-resource-job] registered the ...
- 深度讲解 .net session 过期机制
[参考]net session过期 原理及解决办法 [参考]深入理解session过期机制
- org.hibernate.InvalidMappingException: Could not parse mapping document from无法创建sessionFactory
把 "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd" 改为 "http://hibernate.sourc ...
- 搭建Pypi转发服务
有时候有些正式环境的机器,不能访问外网,就只能在能访问外网的机器上搭建一个转发服务. 一.安装包 pip install flask_pypi_proxy flask_pypi_proxy 二.启动 ...