Python 初识网络
一.
C/S架构:客户端(client)/服务端(server)架构
B/S架构:浏览器(browser) / 服务端(server)架构
软件cs架构: 浏览器,qq,微信等等
硬件cs架构:打印机
二.网络通信的整个流程
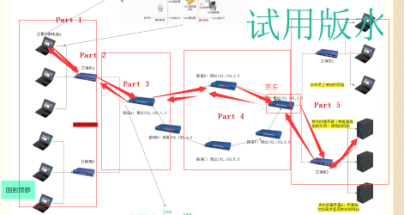
三.初识socket
# 服务器
#导入socket模块
import socket
#创建socket对象,创建了一个手机
server = socket.socket() #给程序设置一个ip地址和端口号,买了个手机卡
ip_port = ('192.168.12.21',8002) #绑定ip地址和端口,插卡
server.bind(ip_port) #监听ip地址和端口,简称开机
server.listen() #等待建立连接, conn是连接通道,addr是客户端的地址
conn,addr = server.accept() #服务端通过conn连接通道来收发消息,通过recv方法,recv里面的参数是字节(B),1024的意思1024B=1KB
from_client_msg = conn.recv(1024) print(from_client_msg.decode('utf-8')) #回复消息:通过send方法,参数必须是字节类型的,
conn.send('你也好呀'.encode('utf-8')) #关闭通道,关电话,通过close方法
conn.close()
#关闭socket对象,关机
server.close()
# 客户端
#导入socket
import socket
#创建一个socket对象
client = socket.socket()
#找到服务端的ip地址和端口
server_ip_port = ('192.168.12.21',8002)
#连接服务端的应用程序,通过connect方法,参数是服务端的ip地址和端口,打电话
client.connect(server_ip_port) #发消息,用的send方法,但是调用者是client的socket对象
client.send('你好'.encode('utf-8')) from_server_msg = client.recv(1024) print(from_server_msg.decode('utf-8'))
client.close()


Python 初识网络的更多相关文章
- Python——初识网络爬虫(网页爬取)
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫 ...
- Python 入门【一】Python 初识及学习资料
Python 初识及学习路线: CodeCademy Python 在线教学: 廖雪峰 Python 2.7 教程: 廖雪峰 Python 3.0 教程: Python 官方文档(2.7~3.7:英文 ...
- python之网络编程
本地的进程间通信(IPC)有很多种方式,但可以总结为下面4类: 消息传递(管道.FIFO.消息队列) 同步(互斥量.条件变量.读写锁.文件和写记录锁.信号量) 共享内存(匿名的和具名的) 远程过程调用 ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- python获取网络时间和本地时间
今天我们来看一下如何用python获取网络时间和本地时间,直接上代码吧,代码中都有注释. python获取网络时间 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作 ...
- Python即时网络爬虫:API说明
API说明——下载gsExtractor内容提取器 1,接口名称 下载内容提取器 2,接口说明 如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪 ...
随机推荐
- Eclipse 导入本地 Git 项目
File --> Open Projects From File System 选择项目路径 Finish
- MapReducer
MapReducer 概述 是一个分布式的计算框架(编程模型),最初由由谷歌的工程师开发,基于GFS的分布式计算框架.后来Cutting根据<Google Mapreduce ...
- 10-01 Java 类,抽象类,接口的综合小练习--运动员和教练
运动员和教练的案例分析 运动运和教练的案例 代码实现 /* 教练和运动员案例 乒乓球运动员和篮球运动员. 乒乓球教练和篮球教练. 为了出国交流,跟乒乓球相关的人员都需要学习英语. 请用所学知识: 分析 ...
- 轮播图采用js、jquery实现无缝滚动和非无缝滚动的四种案例实现,兼容ie低版本浏览器
项目源代码下载地址:轮播图 以下为项目实现效果:(由于gif太大,所以只上传一张图片,但效果完全能实现,经测试,在ie各版本浏览器及chrome,firefox等浏览器中均能实现效果,可以实现点击切换 ...
- odoo开发笔记 -- 用户配置界面如何增加模块访问权限
在odoo设置界面,点击用户,进入用户配置界面,会看到: 访问权 | 个人资料菜单 在访问权 page菜单界面,可以看到系统预制的一些模块都会显示在这里, 那么,我们自己开发的模块如何显示在这块呢,从 ...
- MVC3学习:将excel文件导入到sql server数据库
思路: 1.将excel文件导入到服务器中. 2.读取excel文件,转换成dataset. 3.循环将dataset数据插入到数据库中. 本例子使用的表格为一个友情链接表F_Link(LinkId, ...
- HuLu机器学习问题与解答系列(1-8)
声明:本系列文章转载自微信公众号HULU,本人只是搬运工,仅供学习,如有不妥,后续告知删除. 嗨,欢迎回来,希望你能保持定期回顾的好习惯噢!下面是Hulu机器学习问题与解答系列的前8篇内容,点击主题名 ...
- c++中堆、栈、自由存储区和常量存储区(转)
代码段 --text(code segment/text segment)text段在内存中被映射为只读,但.data和.bss是可写的.text段是程序代码段,在AT91库中是表示程序段的大小,它是 ...
- Mac终端配置,DIY你的Terminal (iTerm 2 + Oh My Zsh)
使用mac osx一年以来,自带的Terminal终端一直都是白底黑字,食之无味,越来越缺乏新鲜感,怎么也得想个法子来刺激下眼球. 不然花那么多大洋买你回来是要哪般,难道真是为来学习工作??? 怎么可 ...
- Vue笔记:使用 Yarn 管理依赖包
上年10月份, Facebook 发布了新的 node.js 包管理器 Yarn 用以替代 npm ,它比npm更快.更高效. Yarn VS npm 1.yarn.lock 文件 在 npm 中同样 ...