Python——初识网络爬虫(网页爬取)
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。爬虫实在是计算机从业者的福音,它大大的缩减了我们的工作量。今天,我们就来尝试一下网页的爬取。
首先,我们需要安装两个基本的库,requests和beautifulsoup4。
requests:requests是Python中一个第三方库,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
beautifulsoup4:Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
我们安装这两个库的最简单的方法当然是通过pip指令。首先打开控制台,输入cmd,然后输入指令:
pip install requests/beautifulsoup4
即可自动安装。(关于pip的基本用法请见上一篇博客:https://www.cnblogs.com/Chen-K/p/11785161.html)
接下来,我们尝试着爬取一个网页的代码:
import requests
r=requests.get("https://httpbin.org")
print(type(r))
print(r.status_code)
print(r.encoding)
print(r.text)
print(r.cookies)
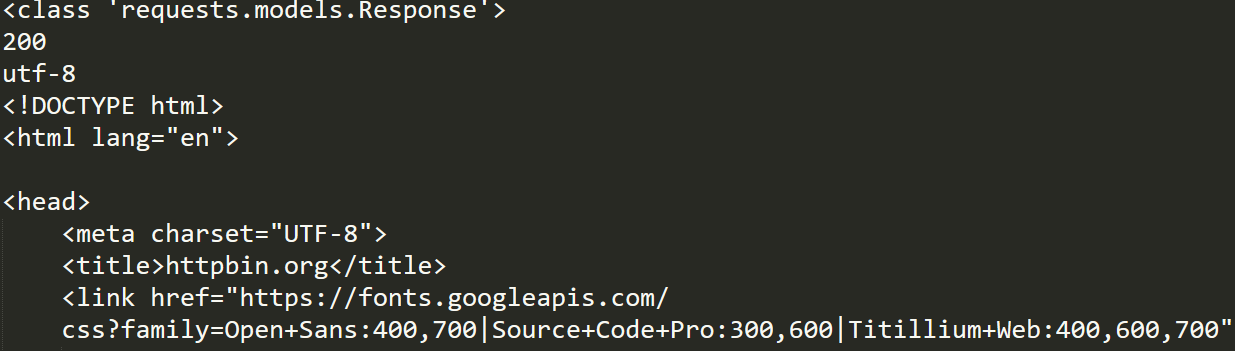
那么,当我们只想爬取网页上的某一个标签时,又该如何操作呢?
import requests
from bs4 import BeautifulSoup
r=requests.get("https://www.baidu.com")
r.encoding='utf-8'
result=r.text
# print(result)
soup=BeautifulSoup(result,'html.parser')
name=soup.find_all('head')
for i in name:
print(i.text)

Python——初识网络爬虫(网页爬取)的更多相关文章
- Python和BeautifulSoup进行网页爬取
在大数据.人工智能时代,我们通常需要从网站中收集我们所需的数据,网络信息的爬取技术已经成为多个行业所需的技能之一.而Python则是目前数据科学项目中最常用的编程语言之一.使用Python与Beaut ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
- python3编写网络爬虫19-app爬取
一.app爬取 前面都是介绍爬取Web网页的内容,随着移动互联网的发展,越来越多的企业并没有提供Web页面端的服务,而是直接开发了App,更多信息都是通过App展示的 App爬取相比Web端更加容易 ...
- python学习之爬虫(一) ——————爬取网易云歌词
接触python也有一段时间了,一提到python,可能大部分pythoner都会想到爬虫,没错,今天我们的话题就是爬虫!作为一个小学生,关于爬虫其实本人也只是略懂,怀着"Done is b ...
随机推荐
- Docs-.NET-C#-指南-语言参考-预处理器指令:#pragma(C# 参考)
ylbtech-Docs-.NET-C#-指南-语言参考-预处理器指令:#pragma(C# 参考) 1.返回顶部 1. #pragma(C# 参考) 2015/07/20 #pragma 为编译器给 ...
- typescript属性类型接口
/* typeScript中的接口 - 1.属性类接口 */ /* 接口的作用:在面向对象的编程中,接口是一种规范的定义,它定义了行为和动作的规范,在程序设计里面,接口起到一种限制和规范的作用.接口定 ...
- Python的collections之defaultdict的使用及其优势
user_dict = {} users = ["baoshan1", "baoshan2", "baoshan3","baosh ...
- 使用java移位运算符进行转化
import java.util.Scanner; public class Main { public static void main(String[] args) { new Main().sy ...
- 【mysql】添加删除权限
https://www.cnblogs.com/wuxunyan/p/9095016.html
- Swift编码总结2
1.swift如何隐藏在 iPad 上的 quicktype 键盘工具栏? let item = textField.inputAssistantItem item.leadingBarButtonG ...
- LODOP判断没成功发送任务-重打一下
一般情况下打印执行了PRINT()或PRINTA(),就会加入打印机队列,如果打印机脱机,就会在队列里排队,当打印机连上并取消脱机的时候,正在排队的任务就会打出,所以一般建议用是否加入队列来判断打印成 ...
- HTML布局排版1清除body的margin
观察可发现,一般的HTML页面分为上中下三部分,上边是导航一栏,中间是内容,下方是页面的下部分.注意html里body本身自带8px的上下左右外边距,如图,在qq浏览器和ie里可以看到body本身是8 ...
- vue 组件传值$attrs $listeners $bus provide/inject $parent/$children
$attrs 包含了父作用域中不作为prop被识别的特性绑定,当一个组件没有声明props时,这里会包含所有父作用域的绑定, $listeneers 包含了父作用域中的v-on事件监听器,它可以通过v ...
- iOS-UITableView的性能优化10个小技巧
通常你会发现一个图片类的app会在一个imageView上做下面这些事情: 1 下载图片(主要的内容图片+用户头像图片)2 更新时间戳3 展示评论4 计算动态的cell的高度 Tip#1 学习 ...