Python中的编码问题(encoding与decode、str与bytes)
1 引言
在文件读写及字符操作时,我们经常会出现下面这几种错误:
- TypeError: write() argument must be str, not bytes
- AttributeError: 'URLError' object has no attribute 'code'
- UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' inposition 5747: illegal multibyte sequence
这些错误一看就是编码问题, 本篇博文总结一下Python3文件读写及字符操作中的编码。
2 编码发展史
(1)ASCII编码
众所周知,计算机只能处理0和1,任何符号都转换为0和1的序列才能处理。计算机中8个位(bit)作为一个字节,所以1个字节能产生2的8次方个0和1的不同组合,也就是说1个字节做多能表示256种字符。ASCII编码就是用1个字节来存储字符,计算机最初是美国人发明的,他们的符号不多,所以还将8个0和1序列中的第一位固定为0,ASCII只能表示127个字符。
(2)GB2312编码
美国佬的符号不多,所以ASCII编码够用,但是其他国家就不行了,每个国家符号数量都不一样,就各自指定了自己的编码。例如我们中国就制定了GB2312编码。GB2312编码用2个字节表示一个字符。
(3)Unicode编码
每个国家都用自己的编码,编码一朵就容易乱套,也没法交流,所以需要一种编码把各个国家的编码都囊括进去,这就是Unicode编码的由来。所以,Unicode也被称为万国码。Unicode编码也用2个字节存储一个字符。
(4)utf-8编码
Unicode编码解决了编码不能通用的问题,但是却容易浪费内存,尤其是在存储英文的时候,例如一个字符“A”,ASCII编码只需要1个字节就够,但是Unicode编码必须要用2个字节。为了解决这一问题,就有了utf-8编码。 utf-8编码把存储英文依旧用一个字节,汉字就3个字节。特别是生僻的编程4-6字节,如果传输大量英文,utf-8作用就很明显了。
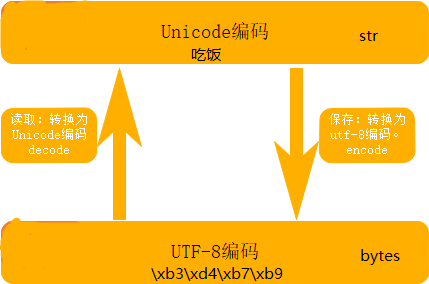
utf-8编码进行存储时有极大地优势,但是当读取到计算机内存时却不大合适,因为utf-8编码是变长的,不方便寻址和索引,所以在计算机内存中,还是转化为Unicode编码合适些。这就可以解释为什么每次读取文本时,要将编码转化为Unicode编码,而将内存中的字符写入文件存储时,要将编码转化为utf-8了。
3 str与bytes
在Python3中,文本总是为Unicode编码,在类型上为str类,也就是说Python编译器只会把Unicode编码下的二进制流显示为我们可识别的符号。二进制流在Python中也有一个专门的类用于表示这种二进制序列,那就是bytes(在Python中这个二进制序列显示为16进制,但本质还是二进制)。一个str在不同的编码下就可以转化为不同的bytes(二进制流),反之,要将bytes转化为可识别的str就必须用对应的编码,否则就会报错。
用人类语言类比一下:我们要表达“吃饭”这件事物(str),翻译为各个国家的文字后有各不相同的表示,中文表示为“吃饭”,英文表示为“eat”,这就是“吃饭”这个str在不同编码写的表示。但官方只认中文(Pythonstr只认Unicode编码),所以就必须把“eat”用英语(编码)的表示方式转化为中文的“吃饭”(Unicode编码),官方才会显示知道是吃饭这件事。
>>> s = '吃饭'
>>> type(s)
<class 'str'>
>>> s1 = s.encode(encoding='utf-8')
>>> type(s1)
<class 'bytes'>
>>> s1
b'\xe5\x90\x83\xe9\xa5\xad'
>>> s2 = s.encode(encoding='gb2312')
>>> type(s2)
<class 'bytes'>
>>> s2
b'\xb3\xd4\xb7\xb9'
>>> s1.decode('utf-8')
'吃饭'
>>> s2.decode('gb2312')
'吃饭'
4 文件编码
在python 3 中字符是以Unicode的形式存储的,当然这里所说的存储是指存储在计算机内存当中,如果是存储在硬盘里,Python 3的字符是以bytes形式存储,也就是说如果要将字符写入硬盘,就必须对字符进行encode。对上面这段话再解释一下,如果要将str写入文件,如果以‘w’模式写入,则要求写入的内容必须是str类型;如果以‘wb’形式写入,则要求写入的内容必须是bytes类型。文章开头出现的几种错误,就是因为写入模式与写入内容的数据类型不匹配造成的。
s1 = '你好'
#如果是以‘w’的方式写入,写入前一定要进行encoding,否则会报错
with open('F:\\1.txt','w',encoding='utf-8') as f1:
f1.write(s1)
s2 = s1.encode("utf-8")#转换为bytes的形式
#这时候写入方式一定要是‘wb’,且一定不能加encoding参数
with open('F:\\2.txt','wb') as f2:
f2.write(s2)
有的人会问,我在系统里面用文本编辑器打开以bytes形式写入的2.txt文件,发现里面显示的是‘你好’,而不是‘b'\xe4\xbd\xa0\xe5\xa5\xbd'’,因为文本文档打开2.txt时,系统会用合适的编码将其显示为对应的符号,然后才给你看到。
5 网页编码
网页编码和文件编码方法差不多,如下urlopen下载下来的网页read()且用decoding(‘utf-8’)解码,那就必须以‘w’的方式写入文件。如果只是read()而不用encoding(‘utf-8’)进行编码,一定要以‘wb’方式写入:
以‘w’方式写入时:
response= url_open('http://blog.csdn.net/gs_zhaoyang/article/details/13768925 ' ,timeout=5 )#自定义的一个网页下载函数
#此处以UTF-8方式进行解码,解码后的数据以unicode的方式存储在html中
html = response.read().decode('UTF-8')
print(type(html))#输出结果:<class 'str'>
#这时写入方式一定要加encoding,以encoding
# 即UTF-8的方式对二进制数据进行编码才能写入
with open('F:\DownloadAppData\html.txt',"w" , encoding='UTF-8') as f:
f.write(html)
以‘wb’方式写入:
response= url_open('http://blog.csdn.net/gs_zhaoyang/article/details/13768925 ' ,timeout=5 )
html = response.read()#此处不需要进行解码,下载下来
print(type(html))#输出结果:<class 'bytes'>
with open('F:\DownloadAppData\html.txt',"wb" ) as f:
f.write(html)
如果要在Python3中,对urlopen下载下来的网页进行字符操作(例如正则匹配、lxml提取),就必须decode成Unicode。
Python中的编码问题(encoding与decode、str与bytes)的更多相关文章
- 【转】【Python】 python中的编码问题报错 'ascii' codec can't decode 及 URL地址获取中文
1.unicode.gbk.gb2312.utf-8的关系 http://www.pythonclub.org/python-basic/encode-detail 这篇文章写的比较好,utf-8是u ...
- python中的编码问题:以ascii和unicode为主线
1.unicode.gbk.gb2312.utf-8的关系 http://www.pythonclub.org/python-basic/encode-detail 这篇文章写的比较好,utf-8 ...
- python中的编码与解码
编码与解码 首先,明确一点,计算机中存储的信息都是二进制的 编码/解码本质上是一种映射(对应关系),比如‘a’用ascii编码则是65,计算机中存储的就是00110101,但是显示的时候不能显 ...
- python基础系列教程——Python中的编码问题,中文乱码问题
python基础系列教程——Python中的编码问题,中文乱码问题 如果不声明编码,则中文会报错,即使是注释也会报错. # -*- coding: UTF-8 -*- 或者 #coding=utf-8 ...
- 深入浅出地,彻彻底底地理解python中的编码
python处理文本的功能非常强大,但是如果是初学者,没有搞清楚python中的编码机制,也经常会遇到乱码或者decode error.本文的目的是简明扼要地说明python的编码机制,并给出一些建议 ...
- python中的编码和解码
计算机中常见的编码方式有多种,英文一般是ascii编码,其他有unicode,utf-8,gbk,utf-16等编码. 常见编码方式: ASCII编码:ASCII是早期的编码,包含英文字母.数字和 ...
- python的str,unicode对象的encode和decode方法, Python中字符编码的总结和对比bytes和str
python_2.x_unicode_to_str.py a = u"中文字符"; a.encode("GBK"); #打印: '\xd6\xd0\xce\xc ...
- python中字符编码及unicode和utf-8区别
ascii和unicode是字符集,utf-8是编码集 字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point) 编码规则:将「码位」转换为字节序列的规则(编码/ ...
- Python中的编码与解码(转)
Python中的字符编码与解码困扰了我很久了,一直没有认真整理过,这次下静下心来整理了一下我对方面知识的理解. 文章中对有些知识没有做深入的探讨,一是我自己也没有去深入的了解,例如各种编码方案的实现方 ...
随机推荐
- ssm框架中Controller层的junit测试_我改
Controller测试和一般其他层的junit测试可以共用一个BaseTest 一.BaseTest如下: @RunWith(SpringJUnit4ClassRunner.class) @WebA ...
- Flink流处理操作符
一.工程创建与准备 使用maven进行工程创建,且采用提供的flink-quickstart模版,便利很多.
- UVALive - 4094 WonderTeam (贪心)
题目大意: 有n支队伍,每两支队伍打两场比赛(主客场各一次),胜得3分,平得1分,输不得分,比赛结束之后会评选出一个梦之队,梦之队满足以下条件:进球总数最多,胜利场数最多,丢求总数最少,三个都不能并列 ...
- c#的事件用法——实现下载时发生的事件
//下载时发出的事件 using System; using System.Collections.Generic; using System.Linq; using System.Text; usi ...
- Kafka 温故(二):Kafka的基本概念和结构
一.Kafka中的核心概念 Producer: 特指消息的生产者Consumer :特指消息的消费者Consumer Group :消费者组,可以并行消费Topic中partition的消息Broke ...
- ASP.Net巧用窗体母版页
背景:每个网页的基本框架结构类似: 浏览网站的时候会发现,好多网站中,每个网页的基本框架都是一样的,比如,最上面都是网站的标题,中间是内容,最下面是网站的版权.开发提供商等信息: 在这些网页中,表头. ...
- HTML5 移动开发(移动设备检测及对HTML5的支持)
1.如何选择要使用的特性以及所面向的浏览器 2.哪些浏览器支持HTML5 3.如何检测是否支持HTML5 4.如何开发贷容错性的Web应用程序 5.CSS3媒体查询如何增强检测脚本 使用HTML5 ...
- assign()函数
tf中assign()函数可用于对变量进行更新包括变量的value和shape. 涉及以下函数: tf.assign(ref, value, validate_shape = None, use_lo ...
- 第10月第13天 xcode ipa
1. xcodebuild -exportArchive -exportFormat ipa -archivePath RongChatRoomDemo\ 17-7-13\ 下午4.04.xcarch ...
- 搭建RabbitMQ集群(通用)
RabbitMQ在Erlang node(节点)上 Erlang天生具有集群特性,非常好搭建集群,每一个节点(node)上具有一个叫erlang.Cookie的东西,也是一个标识符,可以互认. 1). ...