elastic-job详解(一):数据分片
数据分片的目的在于把一个任务分散到不同的机器上运行,既可以解决单机计算能力上限的问题,也能降低部分任务失败对整体系统的影响。elastic-job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器(其实是Job实例,部署在一台机器上的多个Job实例也能分片),开发者需要自行处理分片项与真实数据的对应关系。框架也预置了一些分片策略:平均分配算法策略,作业名哈希值奇偶数算法策略,轮转分片策略。同时也提供了自定义分片策略的接口。
分片原理
elastic-job的分片是通过zookeeper来实现的。分片的分片由主节点分配,如下三种情况都会触发主节点上的分片算法执行:
- 新的Job实例加入集群
- 现有的Job实例下线(如果下线的是leader节点,那么先选举然后触发分片算法的执行)
- 主节点选举
上述三种情况,会让zookeeper上leader节点的sharding节点上多出来一个necessary的临时节点,主节点每次执行Job前,都会去看一下这个节点,如果有则执行分片算法。
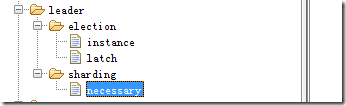
分片的执行结果会存储在zookeeper上,如下图,5个分片,每个分片应该由哪个Job实例来运行都已经分配好。分配的过程就是上面触发分片算法之后的操作。分配完成之后,各个Job实例就会在下次执行的时候使用上这个分配结果。
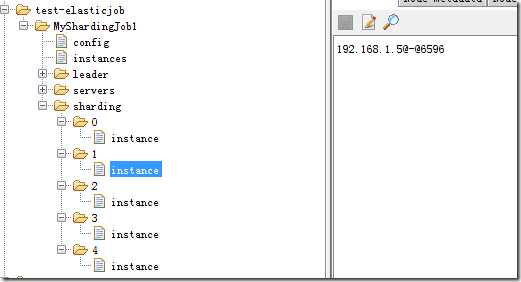
每个job实例任务触发前都会获取本任务在本实例上的分片情况(直接和上图zookeeper上instance节点比对某一个分片是否该有这个Job实例执行),然后封装成shardingContext,传递给调用任务的实际执行方法:
/**
* 执行作业.
*
* @param shardingContext 分片上下文
*/
void execute(ShardingContext shardingContext);
分片算法
所有的分片策略都继承JobShardingStrategy接口。根据当前注册到ZK的实例列表和在客户端配置的分片数量来进行数据分片。最终将每个Job实例应该获得的分片数字返回出去。 方法签名如下:
/**
* 作业分片.
*
* @param jobInstances 所有参与分片的单元列表
* @param jobName 作业名称
* @param shardingTotalCount 分片总数
* @return 分片结果
*/
Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount);
分片函数的触发,只会在leader选举的时候触发,也就是说只会在刚启动和leader节点离开的时候触发,并且是在leader节点上触发,而其他节点不会触发。
1. 基于平均分配算法的分片策略
基于平均分配算法的分片策略对应的类是:AverageAllocationJobShardingStrategy。它是默认的分片策略。它的分片效果如下:
- 如果有3个Job实例, 分成9片, 则每个Job实例分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
- 如果有3个Job实例, 分成8片, 则每个Job实例分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
- 如果有3个Job实例, 分成10片, 则个Job实例分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
2. 作业名的哈希值奇偶数决定IP升降序算法的分片策略
这个策略的对应的类是:OdevitySortByNameJobShardingStrategy,它内部其实也是使用AverageAllocationJobShardingStrategy实现,只是在传入的节点实例顺序不一样,也就是上面接口参数的List<JobInstance>。AverageAllocationJobShardingStrategy的缺点是一旦分片数小于Job实例数,作业将永远分配至IP地址靠前的Job实例上,导致IP地址靠后的Job实例空闲。而OdevitySortByNameJobShardingStrategy则可以根据作业名称重新分配Job实例负载。如:
- 如果有3个Job实例,分成2片,作业名称的哈希值为奇数,则每个Job实例分到的分片是:1=[0], 2=[1], 3=[]
- 如果有3个Job实例,分成2片,作业名称的哈希值为偶数,则每个Job实例分到的分片是:3=[0], 2=[1], 1=[]
实现比较简单:
long jobNameHash = jobName.hashCode();
if (0 == jobNameHash % 2) {
Collections.reverse(jobInstances);
}
return averageAllocationJobShardingStrategy.sharding(jobInstances, jobName, shardingTotalCount);
3. 根据作业名的哈希值对Job实例列表进行轮转的分片策略
这个策略的对应的类是:RotateServerByNameJobShardingStrategy,和上面介绍的策略一样,内部同样是用AverageAllocationJobShardingStrategy实现,也是在传入的List<JobInstance>列表顺序上做文章。
4. 自定义分片策略
除了可以使用上述分片策略之外,elastic-job还允许自定义分片策略。我们可以自己实现JobShardingStrategy接口,并且配置到分片方法上去,整个过程比较简单,下面仅仅列出通过配置spring来切换自定义的分片算法的例子:
<job:simple id="MyShardingJob1" class="nick.test.elasticjob.MyShardingJob1" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="5" sharding-item-parameters="0=A,1=B,2=C,3=D,4=E" job-sharding-strategy-class="nick.test.elasticjob.MyJobShardingStrategy"/>

elastic-job详解(一):数据分片的更多相关文章
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- hadoop2.7作业提交详解之文件分片
在前面一篇文章中(hadoop2.7之作业提交详解(上))中涉及到文件的分片. JobSubmitter.submitJobInternal方法中调用了int maps = writeSplits(j ...
- 百度大脑UNIT3.0详解之数据生产工具DataKit
在智能对话项目搭建的过程中,高效筛选.处理对话日志并将其转化为新的训练数据,是对话系统效果持续提升的重要环节,也是当前开发者面临的难题之一.为此百度大脑UNIT推出学习反馈闭环机制,提供数据获取.辅助 ...
- 不看就亏了:DELL EqualLogic PS6100详解及数据恢办法
DELL EqualLogic PS6100采用虚拟ISCSI SAN阵列,为远程或分支办公室.部门和中小企业存储部署带来企业级功能.智能化.自动化和可靠性,支持VMware.Solaris.Linu ...
- 详解Tensorflow数据读取有三种方式(next_batch)
转自:https://blog.csdn.net/lujiandong1/article/details/53376802 Tensorflow数据读取有三种方式: Preloaded data: 预 ...
- Mycat 分片规则详解--一致性hash分片
实现方式:基于hash算法的分片中,算法内部是把记录分片到一种叫做"bucket"(hash桶)的内部算法结构中的,然后hash桶与实际的分片节点一一对应,从此实现了分片.路由的功 ...
- Mycat 分片规则详解--单月小时分片
实现方式:单月内按照小时拆分,最小粒度是小时,一天最多可以有24个分片,最少1个分片,下个月从头开始循环 优点:使数据按照小时来进行分时存储,颗粒度比日期(天)分片要小,适用于数据采集类存储分片 缺点 ...
- Mycat 分片规则详解--自然月分片
实现方式:按照月份列分片,每个自然月一个分片 优点:使数据按照每月来进行分时存储 缺点:由于数据是连续的,所以该方案不能有效的利用资源 配置示例: <tableRule name="s ...
- Mycat 分片规则详解--固定 hash 分片
实现方式:该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行 & 运算 优点:这种策略比较灵活,可以均匀分配也可以非均匀分配 ...
- Mycat 分片规则详解--取模分片
实现方式:切分规则根据配置中输入的数值n.此种分片规则将数据分成n份(通常dn节点也为n),从而将数据均匀的分布于各节点上. 优点:这种策略可以很好的分散数据库写的压力.比较适合于单点查询的情景 缺点 ...
随机推荐
- module.exports与exports的区别
引言 每一个node.js执行文件,都自动创建一个module对象,同时,module对象会创建一个叫exports的属性,初始化的值是 {} 例子 foo.js exports.a = functi ...
- 山寨版 WP8.1 Cortana 启动 PC
8.1 dev preview 发布以来 Cortana 很受关注 前一段看到有视频演示用 Cortana 来启动 PC 看视频也是启动第三方应用实现的,简单来弄其实就是个语音启动应用 + 网络唤醒么 ...
- thinkphp5分页传参
$name = input('get.searchKey/s'); if($name != ""){ $this->assign('searchKey', $name); $ ...
- HDU 1384 Intervals【差分约束-SPFA】
类型:给出一些形如a−b<=k的不等式(或a−b>=k或a−b<k或a−b>k等),问是否有解[是否有负环]或求差的极值[最短/长路径].例子:b−a<=k1,c−b&l ...
- (2).NET CORE微服务 Micro-Service ---- .NetCore启动配置 和 .NetCoreWebApi
什么是.Net Core?.Net Core是微软开发的另外一个可以跨Linux.Windows.mac等平台的.Net.Net Core相关知识看文章地步dotnet dllname.dll 运行P ...
- Linux(CentOS7)安装Tomcat
概述 Tomcat是运行Jsp文件的容器服务,能够处理URL请求,类似于IIS.相对于IIS,Tomcat可以部署到Linux.Windows.IOS等操作系统.这里主要整理将Tomcat部署到Lin ...
- jenkins X实践系列(3) —— jenkins X 安装拾遗
jx是云原生CICD,devops的一个最佳实践之一,目前在快速的发展成熟中.最近调研了JX,这里为第3篇,介绍下如何安装jenkins x. 前置条件 安装K8S 安装ceph集群(jx需要stor ...
- Windows下80端口被进程System占用的解决方法
最近电脑时不时就发生了80端口被占用的情况,简单百度解决后,当重启电脑的时候又发生被占用的情况.今天非常幸运的是,发生了80端口和8080端口都被占用了情况,忍无可忍决定下定决心解决这个坑爹的问题,经 ...
- 如何在不使用try语句的情况下查看文件是否存在
如果你要确定文件存在的话然后做些什么,那么使用try是最好不过的 如果您不打算立即打开文件,则可以使用os.path.isfile检查文件 如果path是现有常规文件,则返回true.对于相同的路径, ...
- Python交互图表可视化Bokeh:5 柱状图| 堆叠图| 直方图
柱状图/堆叠图/直方图 ① 单系列柱状图② 多系列柱状图③ 堆叠图④ 直方图 1.单系列柱状图 import numpy as np import pandas as pd import matplo ...