python读取文本文件数据
本文要点刚要:
(一)读文本文件格式的数据函数:read_csv,read_table
1.读不同分隔符的文本文件,用参数sep
2.读无字段名(表头)的文本文件 ,用参数names
3.为文本文件制定索引,用index_col
4.跳行读取文本文件,用skiprows
5.数据太大时需要逐块读取文本数据用chunksize进行分块。
(二)将数据写成文本文件格式函数:to_csv
范例如下:
(一)读取文本文件格式的数据集
1.read_csv和read_table的区别:
#read_csv默认读取用逗号分隔符的文件,不需要用sep来指定分隔符
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.csv')
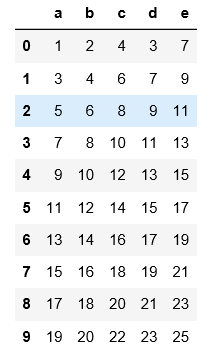
#read_csv如果读的是用非逗号分隔符的文件,必须要用sep指定分割符,不然读出来的是原文件的样子,数据没被分割开
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt')

#与上面的例子可以对比一下区别
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
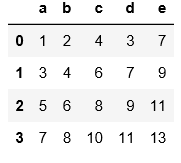
#read_table读取文件时必须要用sep来指定分隔符,否则读出来的数据是原始文件,没有分割开。
import pandas as pd
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.csv')
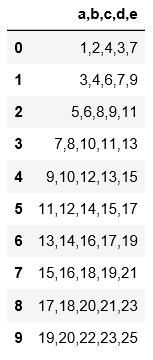
#read_table读取数据必须指定分隔符
import pandas as pd
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
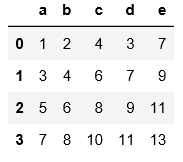
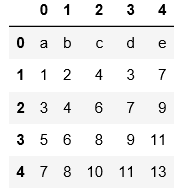
2.读取文本文件时不用header和names指定表头时,默认第一行为表头
#用header=None表示数据集没有表头,会默认用阿拉伯数字填充表头和索引
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',header=None)
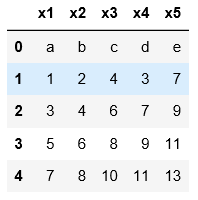
#用names可以自定义表头
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',
names=['x1','x2','x3','x4','x5'])
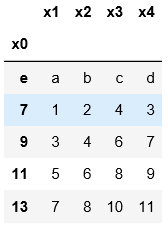
3.默认用阿拉伯数字指定索引;用index_col指定某一列作为索引
names=['x1','x2','x3','x4','x0']
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',
names=names,index_col='x0')
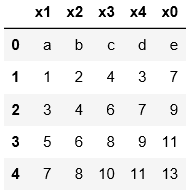
4.以下示例是用skiprows将hello对应的行跳过后读取其他行数据,不管首行是否作为表头,都是将表头作为第0行开始数
可以对比一下三个例子的区别进行理解
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt')

names=['x1','x2','x3','x4','x0']
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',names=names,
skiprows=[0,3,6])
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',
skiprows=[0,3,6])
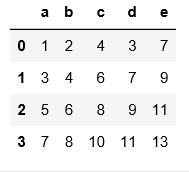
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',header=None,
skiprows=[0,3,6])
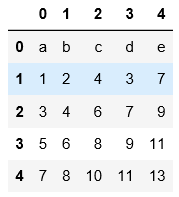
5.分块读取,data1.txt中总共8行数据,按照每块3行来分,会读3次,第一次3行,第二次3行,第三次1行数据进行读取。
注意这里在分块的时候跟跳行读取不同的是,表头没作为第一行进行分块读取,可通过一下两个例子对比进行理解。
chunker = pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',chunksize=3)
for m in chunker:
print(len(m))
print m

chunker = pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',header=None,
chunksize=3)
for m in chunker:
print(len(m))
print m

(二)将数据写入文本格式用to_csv
以data.txt为例,注意写出文件时,将索引也写入了
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
print data

#可以用index=False禁止索引的写入。
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
data.to_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\outdata.txt',sep='!',index=False)

#可以用columns指定写入的列
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
data.to_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\outdata2.txt',sep=',',index=False,
columns=['a','c','d'])

python读取文本文件数据的更多相关文章
- Windows下Python读取GRIB数据
之前写了一篇<基于Python的GRIB数据可视化>的文章,好多博友在评论里问我Windows系统下如何读取GRIB数据,在这里我做一下说明. 一.在Windows下Python为什么无法 ...
- Python读取JSON数据,并解决字符集不匹配问题
今天来谈一谈Python解析JSON数据,并写入到本地文件的一个小例子. – 思路如下 从一个返回JSON天气数据的网站获取到目标JSON数据串 使用Python解析出需要的部分 写入到本地文件,供其 ...
- python 读取excel数据并将测试结果填入Excel
python 读取excel数据并将测试结果填入Excel 读取一个Excel中的一条数据用例,请求接口,然后返回结果并反填到excel中.过程中会生成请求回来的文本,当然还会生成一个xml文件.具体 ...
- python读取文本文件
1. 读取文本文件 代码: f = open('test.txt', 'r') print f.read() f.seek(0) print f.read(14) f.seek(0) print f. ...
- 利用Python读取外部数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素.利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析.数 ...
- Python读取文件数据
1题目要求: 文本文件有这些数据,需要的只有其中的5个属性,如下颜色标记 像以下的数据达到75万组: 1product/productId: B0000UIXZ4 2product/title: Ti ...
- Python读取Excel数据并根据列名取值
一直想将自己接触到的东西梳理一遍,可就是迈不出第一步,希望从这篇总结开始不要再做行动的矮人了. 最近测试过程中需要用到python读取excel用例数据,于是去了解和学习了下xlrd库,这里只记录使用 ...
- python——读取MATLAB数据文件 *.mat
鉴于以后的目标主要是利用现有的Matlab数据(.mat或者.txt),主要考虑python导入Matlab数据的问题.以下代码可以解决python读取.mat文件的问题.主要使用sicpy.io即可 ...
- python 读取二进制数据到可变缓冲区中
想直接读取二进制数据到一个可变缓冲区中,而不需要做任何的中间复制操作.或者你想原地修改数据并将它写回到一个文件中去. 为了读取数据到一个可变数组中,使用文件对象的readinto() 方法.比如 im ...
随机推荐
- 使用 HttpClient3.1 和 HtmlParser2.1 开发Crawler
https://www.ibm.com/developerworks/cn/opensource/os-cn-crawler/
- LDAP是什么
LDAP的英文全称是Lightweight Directory Access Protocol,一般都简称为LDAP.LDAP目录服务是一种特殊的数据库系统,其专门针对读取,浏览和搜索操作进行了特定的 ...
- python中两种方法实现二分法查找,细致分析二分法查找算法
之前分析了好多排序算法,可难理解了呢!!(泣不成声)这次我要把二分查找总结一下,这个算法不算难度特别大,欢迎大家参考借鉴我不喜欢太官方的定义,太晦涩的语言,让人看了就头晕.我希望加入我自己的理解,能帮 ...
- TR069网管协议应用在Android系统开发的前言
随着智能平台的终端设备不断发展,迫切需要我们解决这些终端的管理问题,而现有的终端统一管理平台已经成熟,主要是基于tr069协议网管平台,比如华为的itms等终端管理平台.所以,这篇文章就是为了实现一种 ...
- PHP性能优化利器:生成器 yield理解
如果是做Python或者其他语言的小伙伴,对于生成器应该不陌生.但很多PHP开发者或许都不知道生成器这个功能,可能是因为生成器是PHP 5.5.0才引入的功能,也可以是生成器作用不是很明显.但是,生成 ...
- JS实现数组去重方法总结(六种方法)
方法一: 双层循环,外层循环元素,内层循环时比较值 如果有相同的值则跳过,不相同则push进数组 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Array. ...
- 解决将/etc/passwd文件中1000改为0后只能guest进入系统的问题 ||ubuntu下将普通用户权限升级为root用户权限的方法;
其实我现在才知道linux系统对于用户权限管理比较严,在ubuntu下系统不允许root权限的用户进入图像界面系统.由于之前没弄过权限这个东西瞬间掉坑了了. 我是想修改一下root下的nginx.co ...
- Headless Chrome:服务端渲染JS站点的一个方案【上篇】【翻译】
原文链接:https://developers.google.com/web/tools/puppeteer/articles/ssr 注:由于英文水平有限,没有逐字翻译,可以选择直接阅读原文 tip ...
- servlet学习总结
一.web工程结构 1.HTTP协议(hyper text transfer protocol)(超文本传输协议) 机制:请求/响应 机制(request/response)(HttpServletR ...
- ●BZOJ 1076 [SCOI2008]奖励关
题链: http://www.lydsy.com/JudgeOnline/problem.php?id=1076题解: 期望dp. (模糊的题意,2333) 题中的:"现在决定不吃的宝物以后 ...