Scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
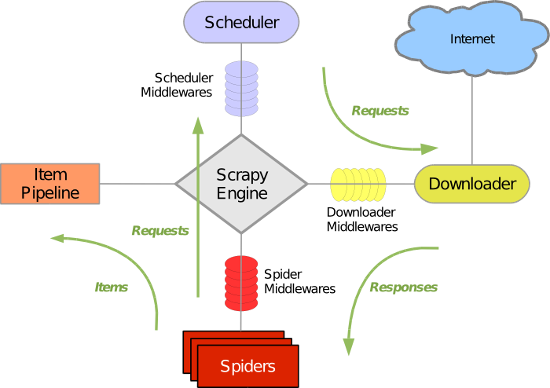
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
Scrapy框架给我们提供了一套完整的运行机制,我们只需要自己去编写部分代码,就可以运行Scrapy框架
关于Requests库与Scrapy框架的比较可以参考:http://www.cnblogs.com/wupeiqi/articles/5354900.html
Scrapy框架的更多相关文章
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
随机推荐
- MySQL默认储存引擎修改
1.输入以下SQL语句查看当前储存引擎支持: SHOW ENGINES; 如图所示本机默认引擎为MyISAM: 2.若要修改引擎执行: ALTER TABLE 表名 ENGINE = 储存引擎名: 3 ...
- HttpWebRequest,HttpWebResponse C# 代码调用webservice,参数为xml
先上调用代码 public static string PostMoths(string url, string Json) { System.Net.HttpWebRequest request; ...
- netty : NioEventLoopGroup 源码分析
NioEventLoopGroup 源码分析 1. 在阅读源码时做了一定的注释,并且做了一些测试分析源码内的执行流程,由于博客篇幅有限.为了方便 IDE 查看.跟踪.调试 代码,所以在 github ...
- Spark入门(1-5)Spark统一了TableView和GraphView
下面我们看一下图计算的简单示例: 从图我们可以看出, 拿到Wikipedia的文档后,我们可以: 1.Wikipedia的文档 -- > table视图 -- >分析Hyperlinks超 ...
- SiteMesh入门(1-1)SiteMesh是什么?
1.问题的提出 在开发Web 应用时,Web页面可能由不同的人参与开发,因此开发出来的界面通常千奇百怪.五花八门,风格难以保持一致. 为了统一界面的风格,Struts 框架提供了一个标签库Tiles ...
- 超简单的jQuery前台分页,不需导包
今天我们介绍一个不需要导分页包的,非常容易上手的分页+模糊查询功能.接下来先介绍分页功能: 首先第一步,你要有个要去分页的列表.我这里敲了个简单的图书管理,作为展示的基础,它的列表为异步提交,由两部分 ...
- Lintcode373 Partition Array by Odd and Even solution 题解
[题目描述] Partition an integers array into odd number first and even number second. 分割一个整数数组,使得奇数在前偶数在后 ...
- Spring Cloud学习笔记-006
服务容错保护:Spring Cloud Hystrix 在微服务架构中,我们将系统拆分成了很多服务单元,各单元的应用间通过服务注册与订阅的方式互相依赖.由于每个单元都在不同的进程中运行,依赖通过远程调 ...
- 【转载】C++基本功和 Design Pattern系列 ctor & dtor
最近实在是太忙了,无工夫写呀.只能慢慢来了.呵呵,今天Aear讲的是class.ctor 也就是constructor, 和 class.dtor, destructor. 相信大家都知道const ...
- 机器学习:scipy和sklearn中普通最小二乘法与多项式回归的使用对
相关内容连接: 机器学习:Python中如何使用最小二乘法(以下简称文一) 机器学习:形如抛物线的散点图在python和R中的非线性回归拟合方法(以下简称文二) 有些内容已经在上面两篇博文中提到了,所 ...