linux运维、架构之路-Hadoop完全分布式集群搭建
一、介绍
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
二、部署环境规划
1、服务器地址规划
|
序号 |
IP地址 |
机器名 |
类型 |
用户名 |
|
1 |
10.0.0.67 |
Master.Hadoop |
Namenode |
Hadoop/root |
|
2 |
10.0.0.68 |
Slave1.Hadoop |
Datanode |
Hadoop/root |
|
3 |
10.0.0.69 |
Slave2.Hadoop |
Datanode |
Hadoop/root |
2、部署环境
[root@Master ~]# cat /etc/redhat-release
CentOS release 6.9 (Final)
[root@Master ~]# uname -r
2.6.-.el6.x86_64
[root@Master ~]# /etc/init.d/iptables status
iptables: Firewall is not running.
[root@Master ~]# getenforce
Disabled
3、统一/etc/hosts解析
10.0.0.67 Master.Hadoop
10.0.0.68 Slave1.Hadoop
10.0.0.69 Slave2.Hadoop
三、SSH无密码验证配置
1、Master操作
[root@Master ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
d9::b7:b1:f9:aa::6e::b9:0a:::b9::e8 root@Master.Hadoop
The key's randomart image is:
+--[ DSA ]----+
| o. . o |
| ... . . = |
|.... . + |
|o o. + . |
|. .. S.. . |
| E . + . |
| . . + . |
| . + .. |
| .+. .. |
+-----------------+
[root@Master ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
2、分发公钥到两个Slave上面
①Slave1
[root@Slave1 ~]# scp root@Master.Hadoop:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
The authenticity of host 'master.hadoop (10.0.0.67)' can't be established.
RSA key fingerprint is b4::ea:5f:aa::3b:7c:::b9::4c:::.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master.hadoop,10.0.0.67' (RSA) to the list of known hosts.
root@master.hadoop's password:
id_dsa.pub % .6KB/s :
[root@Slave1 ~]# cat ~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys
②Slave2
[root@Slave2 ~]# scp root@Master.Hadoop:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
The authenticity of host 'master.hadoop (10.0.0.67)' can't be established.
RSA key fingerprint is b4::ea:5f:aa::3b:7c:::b9::4c:::.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master.hadoop,10.0.0.67' (RSA) to the list of known hosts.
root@master.hadoop's password:
id_dsa.pub % .6KB/s :
[root@Slave2 ~]# cat ~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys
③Master测试连接slave
[root@Master ~]# ssh Slave1.Hadoop
Last login: Tue Aug :: from 10.0.0.67
[root@Slave1 ~]# exit
logout
Connection to Slave1.Hadoop closed.
[root@Master ~]# ssh Slave2.Hadoop
Last login: Tue Aug :: from 10.0.0.67
四、Hadoop安装及环境配置
1、Master操作
①安装JAVA环境
tar xf jdk-8u121-linux-x64.tar.gz -C /usr/local/
ln -s /usr/local/jdk1..0_121/ /usr/local/jdk
配置环境变量
[root@Master ~]# tail - /etc/profile
export JAVA_HOME=/usr/local/jdk1..0_181
export JRE_HOME=/usr/local/jdk1..0_181/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
[root@Master ~]# source /etc/profile
[root@Master ~]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) -Bit Server VM (build 25.181-b13, mixed mode)
2、Hadoop安装及其环境配置
①安装
tar -xf hadoop-2.8..tar.gz -C /usr/
mv /usr/hadoop-2.8./ /usr/hadoop
###配置Hadoop环境变量###
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
②配置hadoop-env.sh生效
vim /usr/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1..0_181
source /usr/hadoop/etc/hadoop/hadoop-env.sh
[root@Master usr]# hadoop version #查看Hadoop版本
Hadoop 2.8.
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 91f2b7a13d1e97be65db92ddabc627cc29ac0009
Compiled by jdu on --17T04:12Z
Compiled with protoc 2.5.
From source with checksum 60125541c2b3e266cbf3becc5bda666
This command was run using /usr/hadoop/share/hadoop/common/hadoop-common-2.8..jar
③创建Hadoop所需的子目录
mkdir /usr/hadoop/{tmp,hdfs}
mkdir /usr/hadoop/hdfs/{name,tmp,data} -p
④修改Hadoop核心配置文件core-site.xml,配置是HDFS master(即namenode)的地址和端口号
vim /usr/hadoop/etc/hadoop/core-site.xml <configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<final>true</final>
<!--(备注:请先在 /usr/hadoop 目录下建立 tmp 文件夹) -->
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://10.0.0.67:9000</value>
<!-- hdfs://Master.Hadoop:22-->
<final>true</final>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property> </configuration>
⑤配置hdfs-site.xml文件
vim /usr/hadoop/etc/hadoop/hdfs-site.xml <configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
⑥配置mapred-site.xml文件
vim /usr/hadoop/etc/hadoop/mapred-site.xml <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑦配置yarn-site.xml文件
vim /usr/hadoop/etc/hadoop/yarn-site.xml <configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master.Hadoop:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master.Hadoop:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master.Hadoop:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master.Hadoop:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master.Hadoop:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
⑧配置masters、slaves文件
echo "10.0.0.67" >/usr/hadoop/etc/hadoop/masters
echo -e "10.0.0.68\n10.0.0.69" >/usr/hadoop/etc/hadoop/slaves
查看
[root@Master hadoop]# cat /usr/hadoop/etc/hadoop/masters
10.0.0.67
[root@Master hadoop]# cat /usr/hadoop/etc/hadoop/slaves
10.0.0.68
10.0.0.69
3、Slave服务器安装及配置
①拷贝jdk到Slave
scp -rp /usr/local/jdk1..0_181 root@Slave1.Hadoop:/usr/local/
scp -rp /usr/local/jdk1..0_181 root@Slave2.Hadoop:/usr/local/
②拷贝环境变量/etc/profile
scp -rp /etc/profile root@Slave1.Hadoop:/etc/
scp -rp /etc/profile root@Slave2.Hadoop:/etc/
③拷贝/usr/hadoop
scp -rp /usr/hadoop root@Slave1.Hadoop:/usr/
scp -rp /usr/hadoop root@Slave2.Hadoop:/usr/
到此环境搭建完毕
五、启动及验证Hadoop集群
1、启动
①格式化HDFS文件系统
/usr/hadoop/sbin/hadoop namenode –format
②启动Hadoop集群所有节点
sh /usr/hadoop/sbin/start-all.sh
查看hadoop进程
[root@Master sbin]# ps -ef|grep hadoop
root : ? :: /usr/local/jdk1..0_181/bin/java -Dproc_secondarynamenode -Xmx1000m -Djava.library.path=/usr/hadoop/lib -Dhadoop.log.dir=/usr/hadoop/logs -Dhadoop.log.file=hadoop-root-secondarynamenode-Master.Hadoop.log -Dhadoop.home.dir=/usr/hadoop -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/usr/hadoop/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
root : pts/ :: /usr/local/jdk1..0_181/bin/java -Dproc_resourcemanager -Xmx1000m -Dhadoop.log.dir=/usr/hadoop/logs -Dyarn.log.dir=/usr/hadoop/logs -Dhadoop.log.file=yarn-root-resourcemanager-Master.Hadoop.log -Dyarn.log.file=yarn-root-resourcemanager-Master.Hadoop.log -Dyarn.home.dir= -Dyarn.id.str=root -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/usr/hadoop/lib/native -Dyarn.policy.file=hadoop-policy.xml -Dhadoop.log.dir=/usr/hadoop/logs -Dyarn.log.dir=/usr/hadoop/logs -Dhadoop.log.file=yarn-root-resourcemanager-Master.Hadoop.log -Dyarn.log.file=yarn-root-resourcemanager-Master.Hadoop.log -Dyarn.home.dir=/usr/hadoop -Dhadoop.home.dir=/usr/hadoop -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/usr/hadoop/lib/native -classpath /usr/hadoop/etc/hadoop:/usr/hadoop/etc/hadoop:/usr/hadoop/etc/hadoop:/usr/hadoop/share/hadoop/common/lib/*:/usr/hadoop/share/hadoop/common/*:/usr/hadoop/share/hadoop/hdfs:/usr/hadoop/share/hadoop/hdfs/lib/*:/usr/hadoop/share/hadoop/hdfs/*:/usr/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/share/hadoop/yarn/*:/usr/hadoop/share/hadoop/mapreduce/lib/*:/usr/hadoop/share/hadoop/mapreduce/*:/usr/hadoop/contrib/capacity-scheduler/*.jar:/usr/hadoop/contrib/capacity-scheduler/*.jar:/usr/hadoop/contrib/capacity-scheduler/*.jar:/usr/hadoop/contrib/capacity-scheduler/*.jar:/usr/hadoop/share/hadoop/yarn/*:/usr/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/etc/hadoop/rm-config/log4j.properties org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
root 1941 1235 0 16:40 pts/0 00:00:00 grep --color=auto hadoop
③关闭Hadoop集群所有节点
sh /usr/hadoop/sbin/stop-all.sh
Slave1.Hadoop Slave2.Hadoop查看hadoop进程
[root@Slave1 ~]# ps -ef|grep hadoop
root : ? :: /usr/local/jdk1..0_181/bin/java -Dproc_datanode -Xmx1000m -Djava.library.path=/usr/hadoop/lib -Dhadoop.log.dir=/usr/hadoop/logs -Dhadoop.log.file=hadoop-root-datanode-Slave1.Hadoop.log -Dhadoop.home.dir=/usr/hadoop -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/usr/hadoop/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -server -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.datanode.DataNode
root : ? :: /usr/local/jdk1..0_181/bin/java -Dproc_nodemanager -Xmx1000m -Dhadoop.log.dir=/usr/hadoop/logs -Dyarn.log.dir=/usr/hadoop/logs -Dhadoop.log.file=yarn-root-nodemanager-Slave1.Hadoop.log -Dyarn.log.file=yarn-root-nodemanager-Slave1.Hadoop.log -Dyarn.home.dir= -Dyarn.id.str=root -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/usr/hadoop/lib/native -Dyarn.policy.file=hadoop-policy.xml -server -Dhadoop.log.dir=/usr/hadoop/logs -Dyarn.log.dir=/usr/hadoop/logs -Dhadoop.log.file=yarn-root-nodemanager-Slave1.Hadoop.log -Dyarn.log.file=yarn-root-nodemanager-Slave1.Hadoop.log -Dyarn.home.dir=/usr/hadoop -Dhadoop.home.dir=/usr/hadoop -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/usr/hadoop/lib/native -classpath /usr/hadoop/etc/hadoop:/usr/hadoop/etc/hadoop:/usr/hadoop/etc/hadoop:/usr/hadoop/share/hadoop/common/lib/*:/usrhadoop/share/hadoop/common/*:/usr/hadoop/share/hadoop/hdfs:/usr/hadoop/share/hadoop/hdfs/lib/*:/usr/hadoop/share/hadoop/hdfs/*:/usr/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/share/hadoop/yarn/*:/usr/hadoop/share/hadoop/mapreduce/lib/*:/usr/hadoop/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/usr/hadoop/share/hadoop/yarn/*:/usr/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/etc/hadoop/nm-config/log4j.properties org.apache.hadoop.yarn.server.nodemanager.NodeManager
root 1499 1238 0 16:45 pts/0 00:00:00 grep --color=auto hadoop
2、使用jps命令测试
①Master
[root@Master ~]# jps
NameNode
SecondaryNameNode
Jps
ResourceManager
②Slave
[root@Slave1 ~]# jps
Jps
NodeManager
DataNode
3、Master上面查看集群状态
[root@Master ~]# hadoop dfsadmin -report
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it. // :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: (35.41 GB)
Present Capacity: (25.59 GB)
DFS Remaining: (25.59 GB)
DFS Used: ( KB)
DFS Used%: 0.00%
Under replicated blocks:
Blocks with corrupt replicas:
Missing blocks:
Missing blocks (with replication factor ):
Pending deletion blocks: -------------------------------------------------
Live datanodes (): Name: 10.0.0.68: (Slave1.Hadoop)
Hostname: Slave1.Hadoop
Decommission Status : Normal
Configured Capacity: (17.70 GB)
DFS Used: ( KB)
Non DFS Used: (3.98 GB)
DFS Remaining: (12.82 GB)
DFS Used%: 0.00%
DFS Remaining%: 72.42%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Wed Aug :: CST Name: 10.0.0.69: (Slave2.Hadoop)
Hostname: Slave2.Hadoop
Decommission Status : Normal
Configured Capacity: (17.70 GB)
DFS Used: ( KB)
Non DFS Used: (4.03 GB)
DFS Remaining: (12.77 GB)
DFS Used%: 0.00%
DFS Remaining%: 72.11%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Wed Aug :: CST
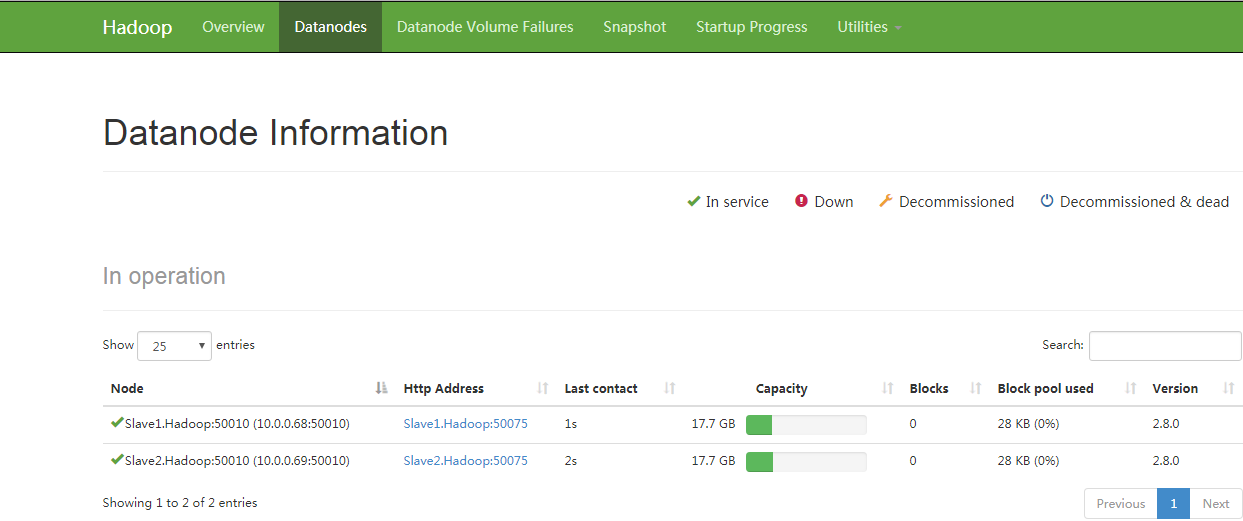
4、通过web页面查看集群状态
http://10.0.0.67:50070

linux运维、架构之路-Hadoop完全分布式集群搭建的更多相关文章
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
- 1、hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
- centos7+hadoop完全分布式集群搭建
Hadoop集群部署,就是以Cluster mode方式进行部署.本文是基于JDK1.7.0_79,hadoop2.7.5. 1.Hadoop的节点构成如下: HDFS daemon: NameN ...
随机推荐
- laradock 部署 php 环境 和 laravel/lumen 框架
环境是windows 10 版本1809,docker 版本18.09.0 首先是下载docker.git, 具体可以参考 http://laradock.io/ 要求 Docker >= 17 ...
- 6.824 Lab 2: Raft 2A
6.824 Lab 2: Raft Part 2A Due: Feb 23 at 11:59pm Part 2B Due: Mar 2 at 11:59pm Part 2C Due: Mar 9 at ...
- Java——LinkedHashMap源码解析
以下针对JDK 1.8版本中的LinkedHashMap进行分析. 对于HashMap的源码解析,可阅读Java--HashMap源码解析 概述 哈希表和链表基于Map接口的实现,其具有可预测的迭 ...
- kafka学习(四)
集群成员关系 kafka使用Zookeeper 来维护集群成员的信息.每个broker都有一个唯一标识符,这个标识符可以在配置里指定,也可以自动生成.在broker启动的时候,它通过创建临时节点把自己 ...
- 解决172.17 或者172.18 机房环境下harbor服务器不通的问题
直接改docker-compose.yml文件: 把原来的network选项注释掉,自定义 #networks: # harbor: # external: false networks: harbo ...
- 为什么存储过程比sql语句效率高?
存储过程经过预编译处理 而SQL查询没有 SQL语句需要先被数据库引擎处理成低级的指令 然后才执行 -------------------------------------------------- ...
- 初涉Java
一.学习内容总结 1.程序入口 但如果类的定义使用了public class声明,那么文件名必须与类名保持一致,使用了class定义的类,文件名称可以和类名称不同. 2.输出语句 3.print与pr ...
- Docker最详细入门教程
Docker原理.详细入门教程 https://blog.csdn.net/deng624796905/article/details/86493330 阮一峰Docker入门讲解 http://ww ...
- Java中字符编码和字符串所占字节数 .
首 先,java中的一个char是2个字节.java采用unicode,2个字节来表示一个字符,这点与C语言中不同,C语言中采用ASCII,在大多数 系统中,一个char通常占1个字节,但是在0~12 ...
- [2019上海网络赛J题]Stone game
题目链接 CSLnb! 题意是求出给定集合中有多少个合法子集,合法子集的定义为,子集和>=总和-子集和$\& \&$子集和-(子集的子集和)<=总和-子集和. 其实就是很简 ...