[转载]hashmap hashtable 的区别
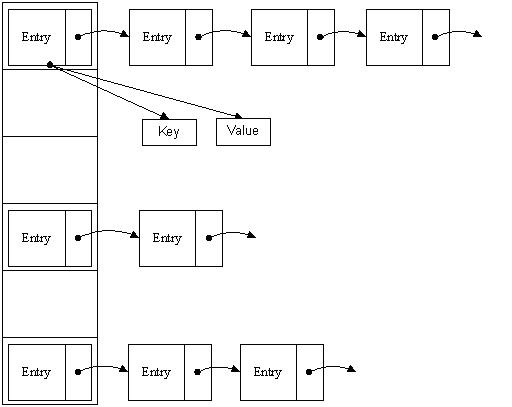
|
|
Hashtable
|
HashMap
|
|
并发操作
|
使用同步机制,
实际应用程序中,仅仅是Hashtable本身的同步并不能保证程序在并发操作下的正确性,需要高层次的并发保护。
下面的代码试图在key所对应的value值等于x的情况下修改value为x+1
{
value = hashTable.get(key);
if(value.intValue()== x){
hashTable.put(key, new Integer(value.intValue()+1));
}
}
如2个线程同时执行以上代码,可能放入不是x+1,而是x+2.
|
没有同步机制,需要使用者自己进行并发访问控制
|
|
数据遍历的方式
|
Iterator 和 Enumeration
|
Iterator
|
|
是否支持fast-fail
|
用Iterator遍历,支持fast-fail
用Enumeration不支持fast-fail.
|
支持fast-fail
|
|
是否接受值为null的Key 或Value?
|
不接受
|
接受
|
|
根据hash值计算数组下标的算法
|
当数组长度较小,并且Key的hash值低位数值分散不均匀时,不同的hash值计算得到相同下标值的几率较高
hash = key.hashCode();
index=(hash&0x7FFFFFFF) % tab.length;
|
优于hashtable,通过对Key的hash做移位运算和位的与运算,使其能更广泛地分散到数组的不同位置
hash = hash (k);
index = indexFor(hash, table.length);
static int hash(Object x) {
int h = x.hashCode();
h += ~(h << 9);
h ^= (h >>> 14);
h += (h << 4);
h ^= (h >>> 10);
return h;
}
static int indexFor(int h, int length) {
return h & (length-1);
}
|
|
Entry数组的长度
|
Ø 缺省初始长度为11,
Ø 初始化时可以指定initial capacity
|
Ø 缺省初始长度为16,
Ø 长度始终保持2的n次方
Ø 初始化时可以指定initial capacity,若不是2的次方,HashMap将选取第一个大于initial capacity 的2n次方值作为其初始长度
|
|
LoadFactor负荷因子
|
0.75
|
|
|
负荷超过(loadFactor * 数组长度)时,内部数据的调整方式
|
扩展数组:2*原数组长度+1
|
扩展数组: 原数组长度 * 2
|
|
两者都会重新根据Key的hash值计算其在数组中的新位置,重新放置。算法相似,时间、空间效率相同
|
||
[转载]hashmap hashtable 的区别的更多相关文章
- HashMap & HashTable的区别
HashMap & HashTable的区别主要有以下: 1.HashMap是线程不安全的,HashTable是线程安全的.由这点区别可以知道,不考虑线程安全的情况下使用HashMap的效率明 ...
- HashMap,HashTable,TreeMap区别和用法
开始学HashTable,HashMap和TreeMap的时候比较晕,觉得作用差不多,但是到实际运用的时候又发现有许多差别的.需要大家注意,在实际开发中以需求而定. java为数据结构中的映射定义了一 ...
- ConcurrentHashMap以及HashMap,HashTable的区别
ConcurrentHashMap与HashMap,和HashTable 的区别? ConcurrentHashMap是一个线程安全的key-value数据结构,而HashMap不是.Concurre ...
- 六.HashMap HashTable HashSet区别剖析总结
HashMap.HashSet.HashTable之间的区别是Java程序员的一个常见面试题目,在此仅以此博客记录,并深入源代码进行分析: 在分析之前,先将其区别列于下面: 1.HashSet底层采用 ...
- (转)hashmap hashtable 的区别 Hash table 内部的数据结构
转自:http://www.cnblogs.com/carbs/archive/2012/07/04/2576995.html Hashtable 和 HashMap 做为 Map 的基本特性 两者都 ...
- [置顶] HashMap HashTable HashSet区别剖析
HashMap.HashSet.HashTable之间的区别是Java程序员的一个常见面试题目,在此仅以此博客记录,并深入源代码进行分析: 在分析之前,先将其区别列于下面 1:HashSet底层采用的 ...
- HashMap HashTable HashSet区别剖析
HashMap.HashSet.HashTable之间的区别是Java程序员的一个常见面试题目,在此仅以此博客记录,并深入源代码进行分析: 在分析之前,先将其区别列于下面 1:HashSet底层采用的 ...
- arrayList LinkedList HashMap HashTable的区别
ArrayList 采用的是数组形式来保存对象的,这种方式将对象放在连续的位置中,所以最大的缺点就是插入删除时非常麻烦 LinkedList 采用的将对象存放在独立的空间中,而且在每个空间中还保存下一 ...
- Java集合——HashMap,HashTable,ConcurrentHashMap区别
Map:“键值”对映射的抽象接口.该映射不包括重复的键,一个键对应一个值. SortedMap:有序的键值对接口,继承Map接口. NavigableMap:继承SortedMap,具有了针对给定搜索 ...
随机推荐
- JVM内存溢出及合理配置
Tomcat本身不能直接在计算机上运行,需要依赖于硬件基础之上的操作系统和一个Java虚拟机.Tomcat的内存溢出本质就是JVM内存溢出,所以在本文开始时,应该先对Java JVM有关内存方面的知识 ...
- MMS关键指标意义&各数值区间意义
MMS关键指标意义&各数值区间意义 What's MMS MongoDB Management Service (MMS) is a suite of services for managin ...
- 设置zookeeper jvm内存
看了你的问题, 我还特意的查看了ZooKeeper的启动脚本代码.ZooKeeper启动脚本没有加任何参数,也就是使用jvm默认的. 如果想要加大ZooKeeper的JVM使用内存.可以在更改{ZK_ ...
- 130 个你需要了解的 vim 命令
基础 :e filename Open filename for edition :w Save file :q Exit Vim :q! Quit without saving :x Write f ...
- Windows下gvim的快捷键--“冒号+w+回车”真的很累人
发现Windows下的gvim支持Ctrl+S保存,Ctrl+A全选,Ctrl+C复制,Ctrl+V粘贴,Ctrl+Z撤销 不过Ctrl+X貌似不太正常(可以剪切,但是不能粘贴) 可能要在安装目录下的 ...
- SQL Server 2008 R2 开启数据库远程连接
今天要测试一个.net系统~因为配置的数据库是SQL Server~我就不得不安装SQL Server 2008 R2~现在我们就一起来看看SQL Server 2008 R2是如何打开远程连接端口1 ...
- Codeforces Round #184 (Div. 2) E. Playing with String(博弈)
题目大意 两个人轮流在一个字符串上删掉一个字符,没有字符可删的人输掉游戏 删字符的规则如下: 1. 每次从一个字符串中选取一个字符,它是一个长度至少为 3 的奇回文串的中心 2. 删掉该字符,同时,他 ...
- nginx后的tomcat获取真实用户ip
目前大部分获取ip的方式:beat.getRequest().getRemoteAddr()但是,如果通过nginx反向代理的话,就获取不到真实ip,是获取的nginx的ip 需要:添加 pro ...
- 用户无法进入SDSF,报NO GROUP ASSIGNMENT错误
注:命令行小写部分表出需要根据自己的情况改变!! a)激活SDSF资源类 SETROPTS CLASSACT(SDSF) b)查看SDSF资源类的PROFILE RLIST SDSF * c)如果不存 ...
- STL中的map/multimap小结
(1)使用map/multimap之前必须包含头文件<map>:#include<map> 并且和所有的关联式容器一样,map/multimap通常以平衡二叉树来完成 (2)n ...