Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一、集群规划
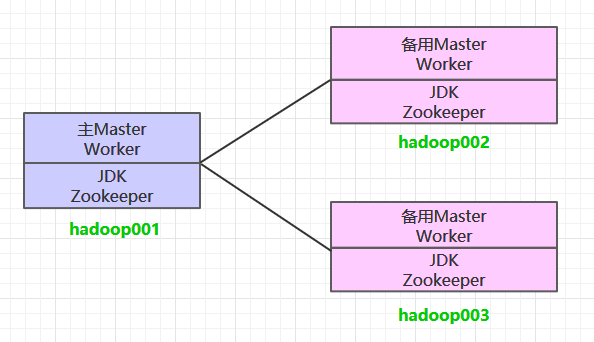
这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 和 hadoop003 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。
二、前置条件
搭建 Spark 集群前,需要保证 JDK 环境、Zookeeper 集群和 Hadoop 集群已经搭建,相关步骤可以参阅:
三、Spark集群搭建
3.1 下载解压
下载所需版本的 Spark,官网下载地址:http://spark.apache.org/downloads.html
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz3.2 配置环境变量
# vim /etc/profile添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH使得配置的环境变量立即生效:
# source /etc/profile3.3 集群配置
进入 ${SPARK_HOME}/conf 目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh# 配置JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"2. slaves
cp slaves.template slaves配置所有 Woker 节点的位置:
hadoop001
hadoop002
hadoop0033.4 安装包分发
将 Spark 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Spark 的环境变量。
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh4.3 启动Spark集群
进入 hadoop001 的 ${SPARK_HOME}/sbin 目录下,执行下面命令启动集群。执行命令后,会在 hadoop001 上启动 Maser 服务,会在 slaves 配置文件中配置的所有节点上启动 Worker 服务。
start-all.sh分别在 hadoop002 和 hadoop003 上执行下面的命令,启动备用的 Master 服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh4.4 查看服务
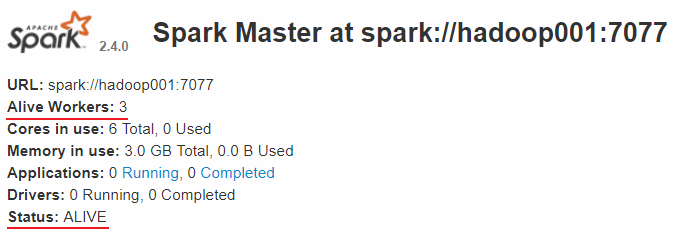
查看 Spark 的 Web-UI 页面,端口为 8080。此时可以看到 hadoop001 上的 Master 节点处于 ALIVE 状态,并有 3 个可用的 Worker 节点。
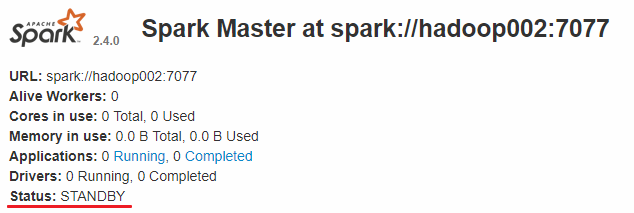
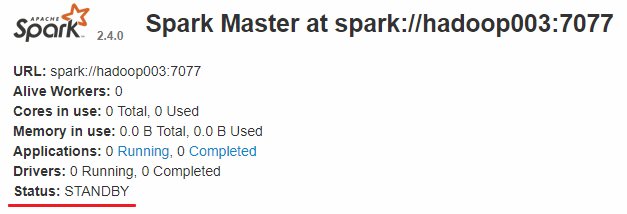
而 hadoop002 和 hadoop003 上的 Master 节点均处于 STANDBY 状态,没有可用的 Worker 节点。
五、验证集群高可用
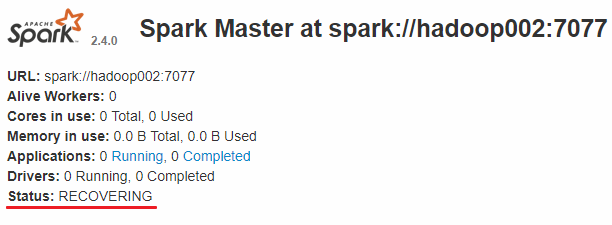
此时可以使用 kill 命令杀死 hadoop001 上的 Master 进程,此时备用 Master 会中会有一个再次成为 主 Master,我这里是 hadoop002,可以看到 hadoop2 上的 Master 经过 RECOVERING 后成为了新的主 Master,并且获得了全部可以用的 Workers。
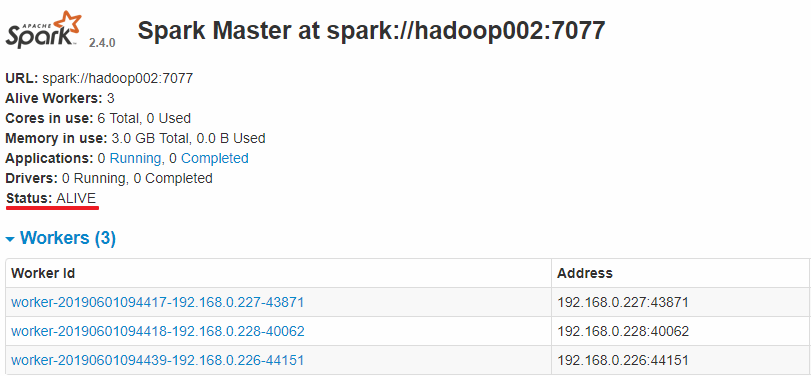
Hadoop002 上的 Master 成为主 Master,并获得了全部可以用的 Workers。
此时如果你再在 hadoop001 上使用 start-master.sh 启动 Master 服务,那么其会作为备用 Master 存在。
六、提交作业
和单机环境下的提交到 Yarn 上的命令完全一致,这里以 Spark 内置的计算 Pi 的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群的更多相关文章
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于Docker-compose搭建Redis高可用集群-哨兵模式(Redis-Sentinel)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_110 我们知道,Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3) ...
- 基于docker实现redis高可用集群
基于docker实现redis高可用集群 yls 2019-9-20 简介 基于docker和docker-compose 使用redis集群和sentinel集群,达到redis高可用,为缓存做铺垫 ...
随机推荐
- kubernetes实战之consul简单测试环境搭建及填坑
这一节内容有点长,我们将介绍如何基于docker搭建一client一server的consul测试环境,以及如何搭建多server consul测试集群.在基于docker搭建多server的cons ...
- Shiro中@RequiresAuthentication等等注解介绍
使用前请先开启Shiro的controller层注解,如果已经设置请下滑绕过 要在spring-mvc.xml中写. <!--下面的用于开启shiro的权限注解--> <bean c ...
- flink window实例分析
window是处理数据的核心.按需选择你需要的窗口类型后,它会将传入的原始数据流切分成多个buckets,所有计算都在window中进行. flink本身提供的实例程序TopSpeedWindowin ...
- 托管堆和垃圾回收(GC)
一.基础 首先,为了深入了解垃圾回收(GC),我们要了解一些基础知识: CLR:Common Language Runtime,即公共语言运行时,是一个可由多种面向CLR的编程语言使用的"运 ...
- mysql+mybatis存储超大json
1. 场景描述 因前端界面需存储元素较多,切割后再组装存储的话比较麻烦,就采用大对象直接存储到mysql字段中,根据mysql的介绍可以存放65535个字节,算了算差不多,后来存的时候发现: 一是基本 ...
- 20131221-Dom练习-第二十六天(未完)
[1] //总结,写代码,一要动脑,理解用脑 //二要练,要动手,要有用身体记忆代码的觉悟,记忆用手 //三学编程最快的方法是,直接接触代码,用脑,用手接触代码 //面向对象的编码方式,对象还是对象, ...
- 【基础算法-模拟-例题-金币】-C++
原题链接:P2669 金币 这道题目完全是一道模拟题,只要按照题目中的加金币的算法和sum累加就可以很轻易得出最终答案. 说一下有一些点需要注意: 1.用i来计每天发的金币数,n来计已经拿了金币的天数 ...
- Python 爬虫:煎蛋网妹子图
使用 Headless Chrome 替代了 PhatomJS. 图片保存到指定文件夹中. import requests from bs4 import BeautifulSoup from sel ...
- CSharp初级篇 1-4 this、索引器、静态、常量以及只读
.NET Core CSharp初级篇 1-4 本节内容为this.索引器.静态.常量以及只读 简介 在之前的课程中,我们谈论过了静态函数和字段的一小部分知识,本节内容中,我们将详细的讲解关于对象操作 ...
- ybc云计算思维
YBC的云计算思维 计算机基础 一 计算机由5大单元组成 输入单元(鼠标 键盘) 存储单元(硬盘 内存) 逻辑单元(CPU) 控制单元(主板) 输出单元(显示器 音响 打印机) CPU CPU主要 ...