python之爬取练习
练习要求爬取http://yuedu.anyv.net/网址的最大页码数和文章标题和链接
网址页面截图:
代码截图:
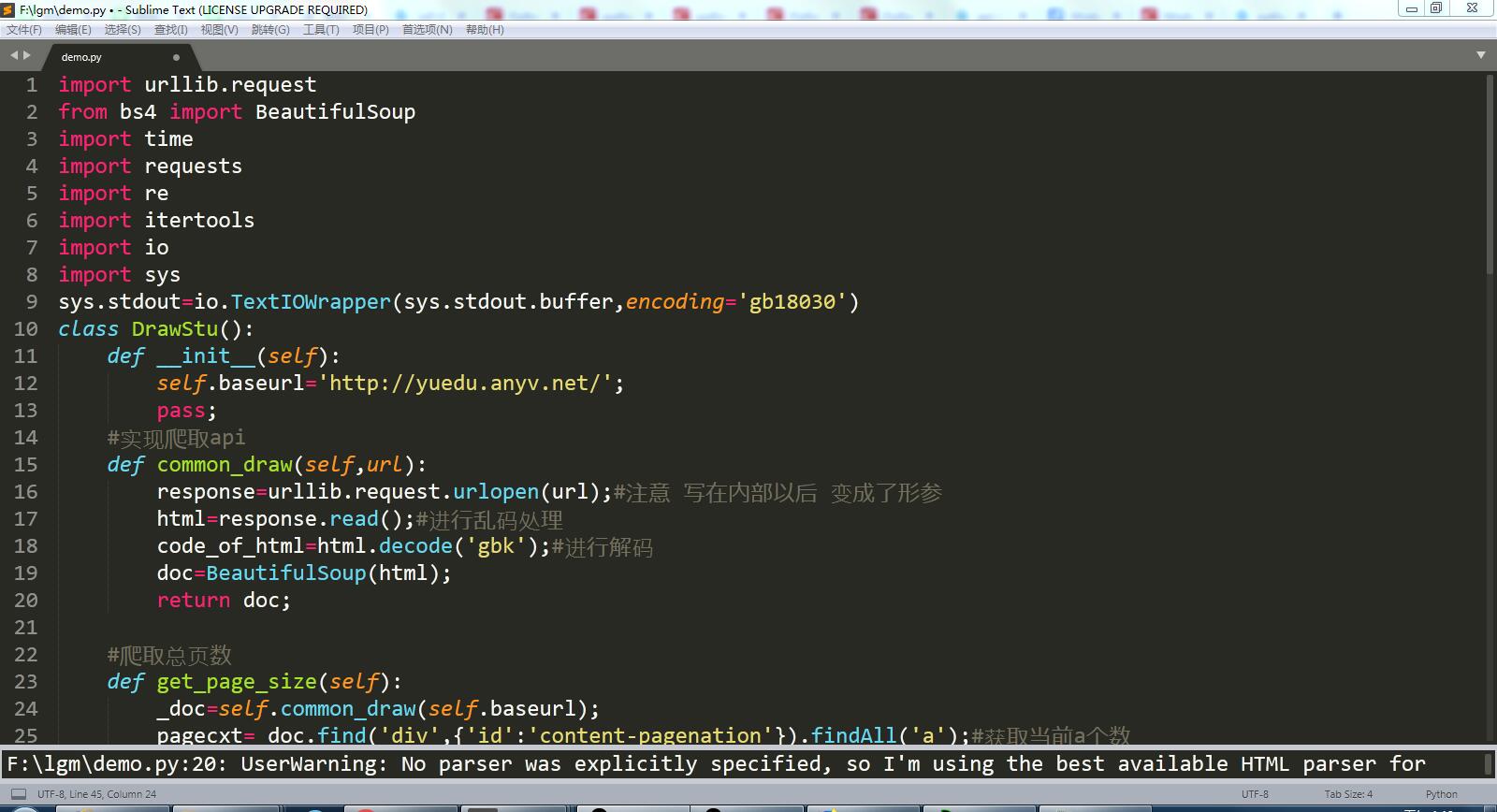

完整代码:
根据网页显示页码的方式,爬取的所有页码中倒数第二个页码是最大页码。
import urllib.request
from bs4 import BeautifulSoup
import time
import requests
import re
import itertools
import io
import sys
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
class DrawStu():
def __init__(self):
self.baseurl='http://yuedu.anyv.net/';
pass;
#实现爬取api
def common_draw(self,url):
response=urllib.request.urlopen(url);#注意 写在内部以后 变成了形参
html=response.read();#进行乱码处理
code_of_html=html.decode('gbk');#进行解码
doc=BeautifulSoup(html);
return doc; #爬取总页数
def get_page_size(self):
_doc=self.common_draw(self.baseurl);
pagecxt=_doc.find('div',{'id':'content-pagenation'}).findAll('a');#获取当前a个数
size=len(pagecxt);
maxsize=pagecxt[size-].text;#获取倒数第二个进行获取里面值就是最大值
maxsize=int(maxsize)
return maxsize; #爬取文章标题和链接
def get_title(self):
r=requests.get("http://yuedu.anyv.net/")
r.encoding=r.apparent_encoding
result=r.text
bs=BeautifulSoup(result,'html.parser')
pagecxt=bs.find('div',{'class':'content'}).findAll('div',{'class':'image group'});
for x in pagecxt:
pageinfo=x.find('div',{'class':'grid news_desc'});
title=pageinfo.find('h3').find('a').text;
print("文章标题:")
print(title)
link=pageinfo.find('h3').find('a').get('href');
print("文章链接:")
print(link) D=DrawStu();
if __name__ == '__main__':
size=D.get_page_size();
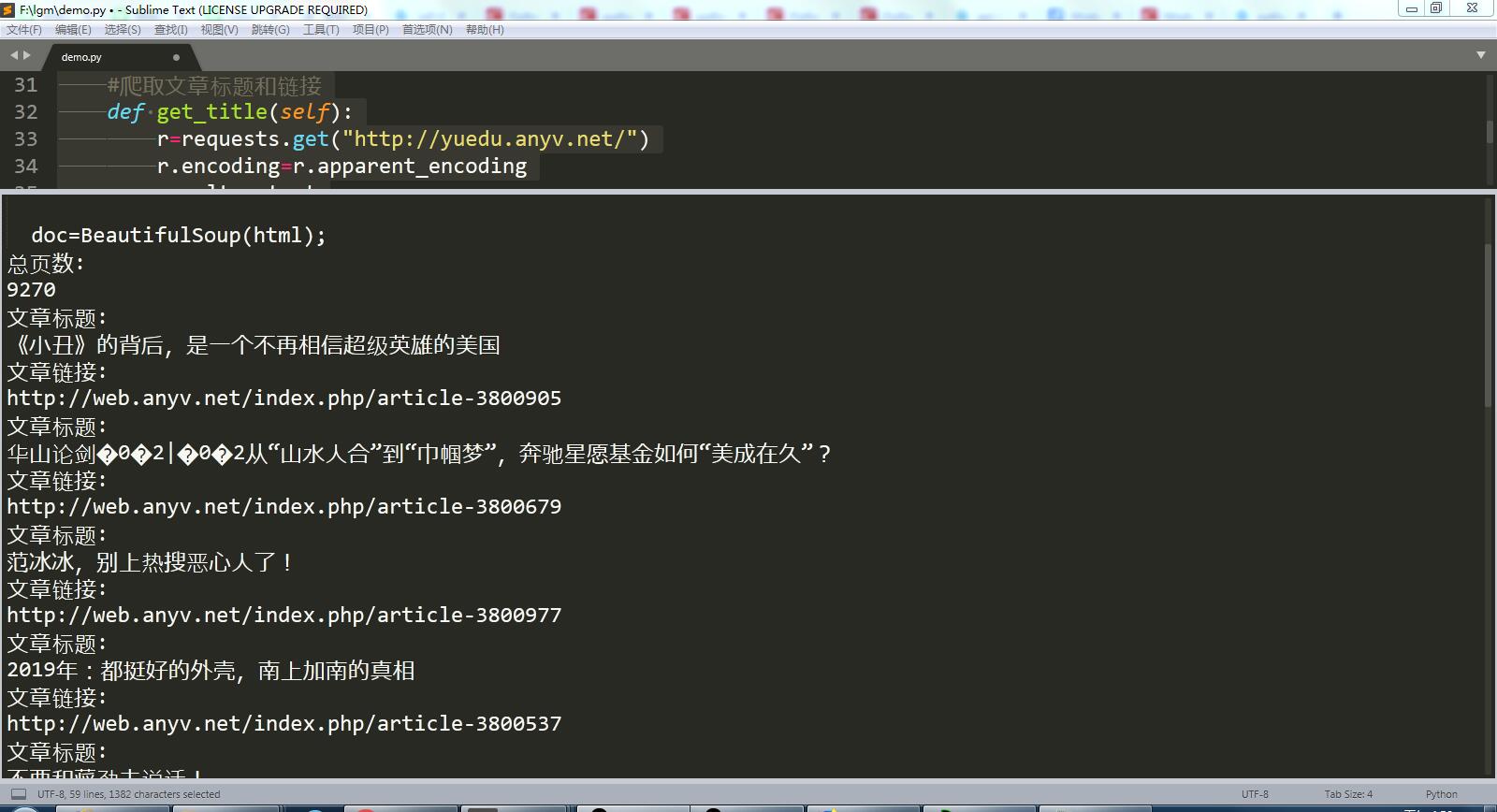
print("总页数:")
print(size)
title=D.get_title();
print(title)
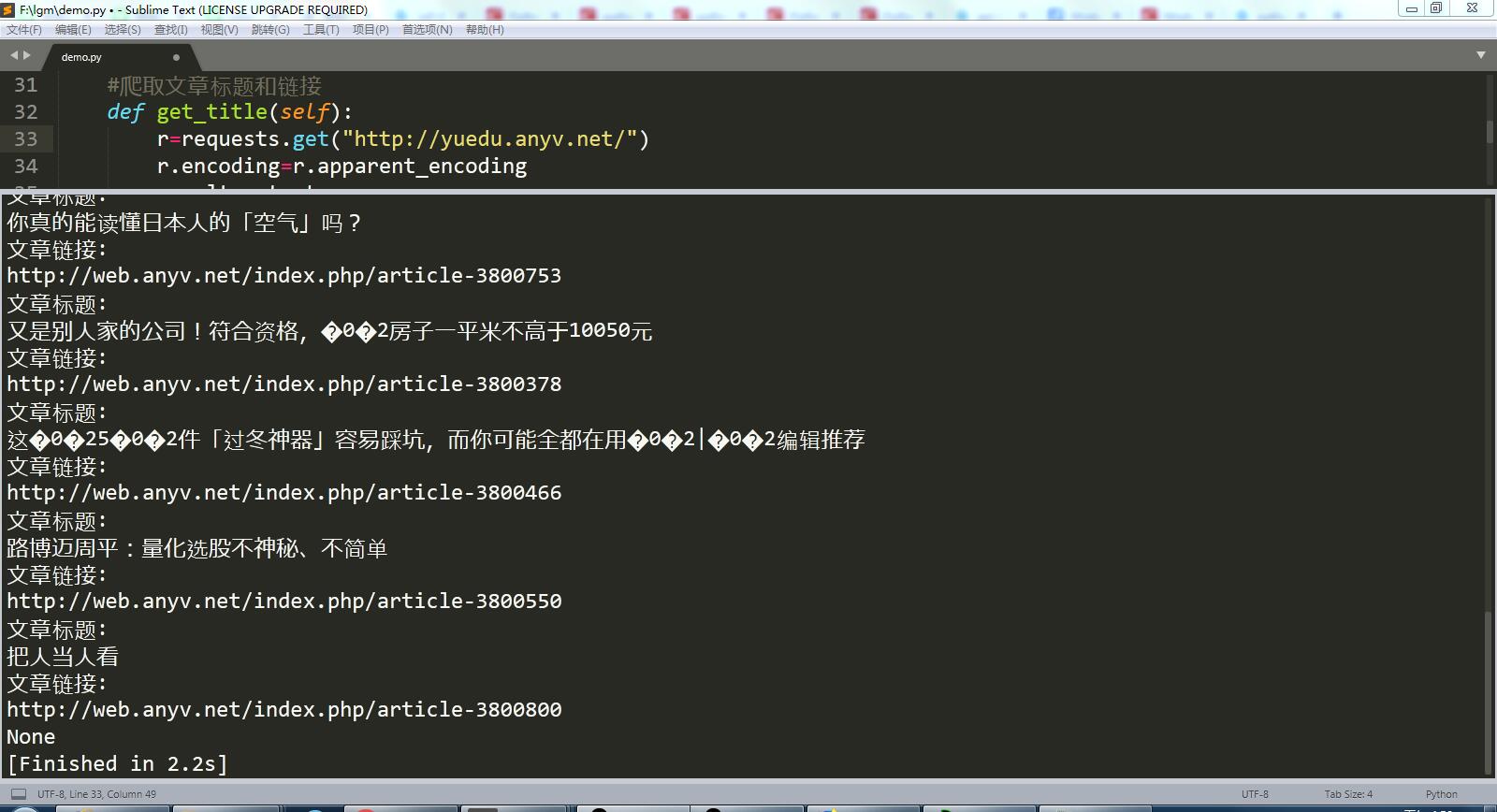
运行结果截图:
python之爬取练习的更多相关文章
- 大神:python怎么爬取js的页面
大神:python怎么爬取js的页面 可以试试抓包看看它请求了哪些东西, 很多时候可以绕过网页直接请求后面的API 实在不行就上 selenium (selenium大法好) selenium和pha ...
- python连续爬取多个网页的图片分别保存到不同的文件夹
python连续爬取多个网页的图片分别保存到不同的文件夹 作者:vpoet mail:vpoet_sir@163.com #coding:utf-8 import urllib import ur ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
- python大规模爬取京东
python大规模爬取京东 主要工具 scrapy BeautifulSoup requests 分析步骤 打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点 我们可以看到这个页面 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
随机推荐
- 3.java基础之关键字instanceof
1. instanceof 使用:对象引用名 instanceof 类名 作用:来判读引用的对象和类名是否兼容(是否继承该类,或爷爷辈的类) 例子: Team team = new Team(); t ...
- Spring基础——配置文件pom.xml,web.xml,ApplicationContext.xml
Spring配置文件——复制粘贴即用 为了以后兼容SSM框架,直接创建Maven Project,包结构如下图. pom.xml <project xmlns="http://mave ...
- report for PA2
目录 说明 Report for PA 2(writed with vim) Part i - pa2.1 Steps: instr(seperately) Part ii - 2.2 Part ii ...
- 学习之Redis(二)
Redis的对象和数据结构 一.字符串对象(请参考学习之Redis(一):https://www.cnblogs.com/wbq1994/p/12029516.html) 二.列表对象 列表对象的编码 ...
- Kafka 的No kafka server to stop报错处理
使用kafka-server-stop.sh命令关闭kafka服务,发现无法删除,报错如下图No kafka server to stop 下面修改kafka-server-stop.sh将 PIDS ...
- 「Shimo使用指南」mac支持pptp协议的小软件
Mac的好多小伙伴在访问网络设备时觉得远程连接不方便,例如ssh,***登陆都不是很方便,后来又安装了open*** forMac.ISSH等客户端,使用后发现不是很稳定,断线后很久都无法连接等缺点, ...
- 手机投屏工具与HOSTS切换工具
ApowerMirror windows -->switchhosts
- 【朝花夕拾】Android自定义View篇之(七)Android事件分发机制(下)滑动冲突解决方案总结
前言 转载请声明,转自[https://www.cnblogs.com/andy-songwei/p/11072989.html],谢谢! 前面两篇文章,花了很大篇幅讲解了Android的事件分发机制 ...
- HttpModules配置事项
前沿:还是那句话 ASP.NET管道,浏览器 - isAPI32.dll - HttpModules - HttpHandler - 返回客户端Web.Config:<httpModules&g ...
- 【TencentOS tiny】深度源码分析(5)——信号量
信号量 信号量(sem)在操作系统中是一种实现系统中任务与任务.任务与中断间同步或者临界资源互斥保护的机制.在多任务系统中,各任务之间常需要同步或互斥,信号量就可以为用户提供这方面的支持. 抽象来说, ...