Bert不完全手册5. 推理提速?训练提速!内存压缩!Albert
Albert是A Lite Bert的缩写,确实Albert通过词向量矩阵分解,以及transformer block的参数共享,大大降低了Bert的参数量级。在我读Albert论文之前,因为Albert和蒸馏,剪枝一起被归在模型压缩方案,导致我一直以为Albert也是为了优化Bert的推理速度,但其实Albert更多用在模型参数(内存)压缩,以及训练速度优化,在推理速度上并没有提升。如果说蒸馏任务是把Bert变矮瘦,那Albert就是把Bert变得矮胖。最近写的文本分类库里加入了Albert预训练模型,有在chinanews上已经微调好可以开箱即用的模型,感兴趣戳这里SimpleClassification
Albert主要有以下三点创新
- 参数共享:降低Transfromer Block的整体参数量级
- 词向量分解:有效降低词向量层参数量级
- Sentence-Order-Prediction任务:比NSP更加有效的学习句间关系
下面我们分别介绍这三个部分
词向量分解
其实与其说是分解,个人觉得词向量重映射的叫法更合适一些。在之前BERT等预训练模型中,词向量的维度E和之后隐藏层的维度H是相同的,因为在Self-Attention的过程中Embedding维度是一直保持不变的,所以要增加隐藏层维度,词向量维度也需要变大。但是从包含的信息量来看,词向量本身只包含上下文无关的信息,并不需要像隐藏层一样存储大量的上下文语义,所以相同维度的限制在词向量部分存在一定的参数冗余。所以作者对词向量做了一层映射,词向量本身的参数变成Vocab * E,映射层是E* H,这样本身的复杂度O(Vocab * H),就降低成了O(Vocab * E + E*H ),相当于把隐藏层大小和词向量部分的参数做了解耦。
这个Trick其实之前在之前的NER系列中出现过多次,比如用在词表增强时,不同词表Embeeding维度的对齐,以及针对维度太高/太低的词表输入,进行适当的降维/升维等等~
以下作者分别对比了在参数共享/不共享的情况下,词向量维度E对模型效果的影响,从768压缩到64,非共享参数下有1个点的下降,共享参数时影响较小。这个在下面参数共享处会再提到,和模型整体能处理的信息量级有一定关系,整体上在共享参数的设定下词向量压缩影响有限~
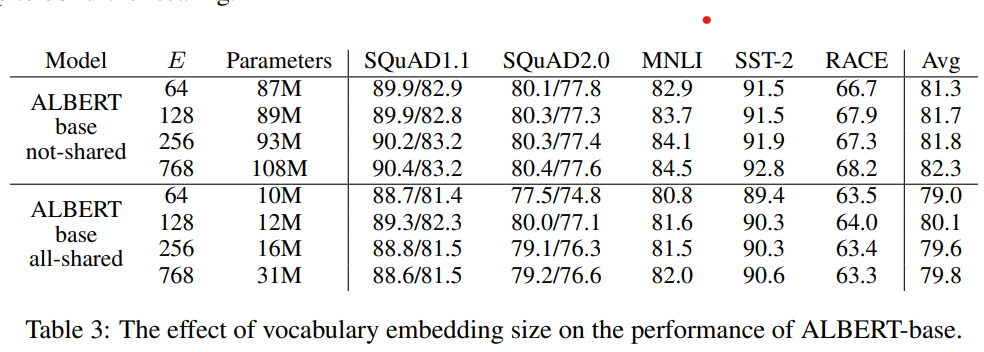
参数共享
参数共享是ALbert提高参数利用率的核心。作者对比了各个block只共享Attention,只共享FFN,和共享所有参数,结果如下~
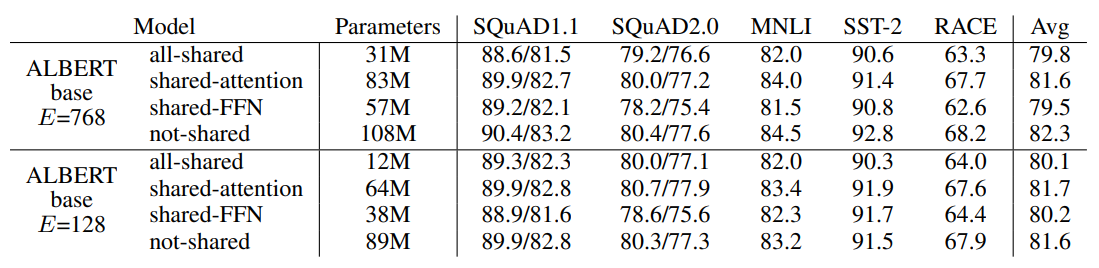
共享参数多少都会影响模型表现,其中效果损失主要来自共享FFN参数。以及在压缩词向量之后,共享参数带来的影响会降低。这里感觉和之前在做词表增强时观察到的现象有些相似,也就是模型的天花板受到输入层整体信息量的影响,因为压缩了词向量维度,限制了输入侧的信息量,模型需要处理的信息降低,从而参数共享带来的损失影响也被降低了
最终作者的选择更多是for最大程度压缩参数量级,share attenion缩减的参数有限,索性就共享了全部的参数。
SOP
在第三章讲到Roberta的时候,提到过Roberta在优化Bert的训练策略时,提出NSP任务没啥用在预训练中只使用了MLM目标。当时就提到NSP没有用一定程度上是它构造负样本的方式过于easy,NSP中连续上下文为正样本,从任意其他文档中采样的句子为负样本,所以模型可以简单通过topic信息来判断,而这部分信息基本已经被MLM任务学到。Albert改良了NSP中的负样本生成方式,AB为正样本,BA为负样本,模型需要判别论述的逻辑顺序和前后句子的合理语序。
作者也进行了对比,在预训练任务上,加入NSP训练的模型在SOP目标上和只使用MLM没啥区别,这里进一步证明了NSP并没有学到预期中的句子关联和逻辑顺序,而加入SOP训练的模型在NSP上表现要超过只使用MLM。在下游依赖上下文推理的几个任务上,加入SOP的模型整体表现略好。不过差异没有想象中的明显,感觉在如何构建负样本上应该还有优化的空间。个人感觉只是AB,BA的构造方式可能有些过于局部了

整体效果
Albert在以上三点改良之外,在训练中也进行了一些优化,例如使用了SpanBert的MASK策略,用了LAMB optimizer来加速训练等等,Albert总共放出了以下几种参数的模型,和BERT之间的效果对比如下~
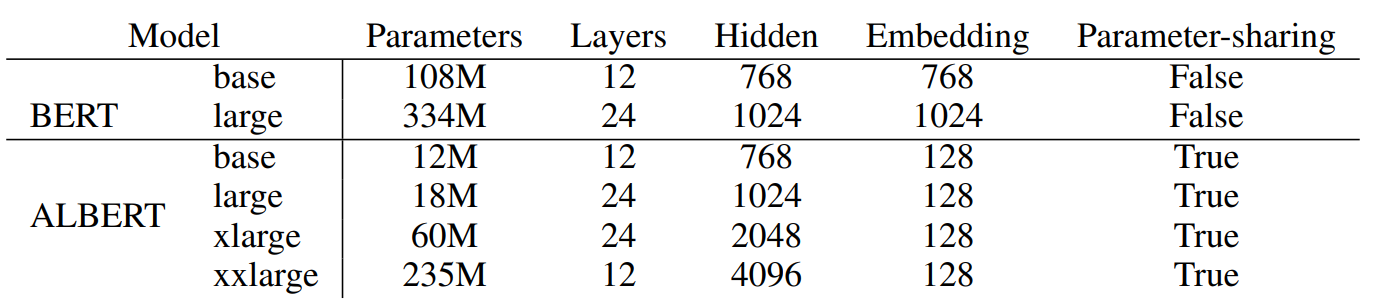
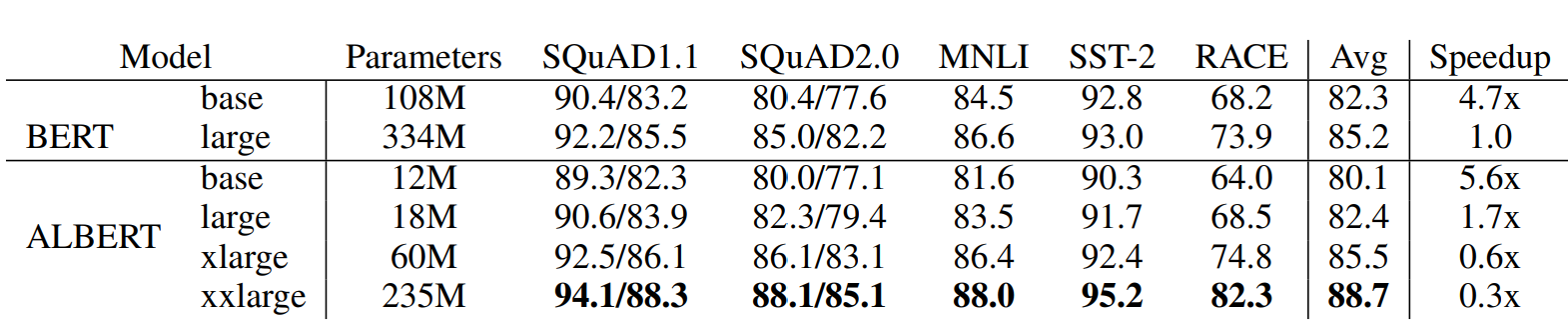
需要注意最后一列是训练速度的对比哈,哈哈之前看paper没带脑子,想都没想就给当成了推理速度,琢磨半天也没明白这为啥就快了???
- 直接base和base比,large和large比:参数可以压缩到1/10,适合大家自己跑来玩玩,整体模型大小甚至比一些词表大的词向量模型还要小,训练速度上也有提升但是模型效果都有2个点以上的损失,以及因为层数没变,所以推理速度不会更快,以及因为词向量分解的原因多了一层,所以还会略慢些
- 相似表现对比:ALbert xlarge和Bertlarge对比,都是24层,xlarge的隐藏层是bert的两倍,这里也是为啥说albert是矮胖,因为参数共享所以加层数效果有限,只能增加隐藏层维度。虽然albert xlarge参数压缩到1/5,但是训练更慢,推理也更慢
- 超越Bert:Albert xxlarge虽然只有12层,但是4倍的隐藏层还是让它的表现全面超越了Bert large,参数压缩到2/3,但是训练速度更更慢,以及超大隐藏层会导致计算中中间变量的存储过大,一般机子跑不动。。。
所以整体感觉albert的实际应用价值比较有限的,但是提出的两个点还有进一步深挖的价值,其一NSP任务负样本是否有进一步改造的空间,其二如何更有效地利用Bert的参数?
Reference
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- https://zhuanlan.zhihu.com/p/84273154
- https://zhuanlan.zhihu.com/p/343729067
Bert不完全手册5. 推理提速?训练提速!内存压缩!Albert的更多相关文章
- Bert不完全手册1. 推理太慢?模型蒸馏
模型蒸馏的目标主要用于模型的线上部署,解决Bert太大,推理太慢的问题.因此用一个小模型去逼近大模型的效果,实现的方式一般是Teacher-Stuent框架,先用大模型(Teacher)去对样本进行拟 ...
- Bert不完全手册6. Bert在中文领域的尝试 Bert-WWM & MacBert & ChineseBert
一章我们来聊聊在中文领域都有哪些预训练模型的改良方案.Bert-WWM,MacBert,ChineseBert主要从3个方向在预训练中补充中文文本的信息:词粒度信息,中文笔画信息,拼音信息.与其说是推 ...
- 如何借助 JuiceFS 为 AI 模型训练提速 7 倍
背景 海量且优质的数据集是一个好的 AI 模型的基石之一,如何存储.管理这些数据集,以及在模型训练时提升 I/O 效率一直都是 AI 平台工程师和算法科学家特别关注的事情.不论是单机训练还是分布式训练 ...
- Bert不完全手册3. Bert训练策略优化!RoBERTa & SpanBERT
之前看过一条评论说Bert提出了很好的双向语言模型的预训练以及下游迁移的框架,但是它提出的各种训练方式槽点较多,或多或少都有优化的空间.这一章就训练方案的改良,我们来聊聊RoBERTa和SpanBER ...
- Bert不完全手册8. 预训练不要停!Continue Pretraining
paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks GitHub: https://github.com ...
- Bert不完全手册2. Bert不能做NLG?MASS/UNILM/BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场 ...
- Bert不完全手册7. 为Bert注入知识的力量 Baidu-ERNIE & THU-ERNIE & KBert
借着ACL2022一篇知识增强Tutorial的东风,我们来聊聊如何在预训练模型中融入知识.Tutorial分别针对NLU和NLG方向对一些经典方案进行了分类汇总,感兴趣的可以去细看下.这一章我们只针 ...
- Bert不完全手册9. 长文本建模 BigBird & Longformer & Reformer & Performer
这一章我们来唠唠如何优化BERT对文本长度的限制.BERT使用的Transformer结构核心在于注意力机制强大的交互和记忆能力.不过Attention本身O(n^2)的计算和内存复杂度,也限制了Tr ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
随机推荐
- ACL 权限控制机制?
UGO(User/Group/Others) 目前在 Linux/Unix 文件系统中使用,也是使用最广泛的权限控制方式.是一种粗 粒度的文件系统权限控制模式. ACL(Access Control ...
- TCP(三)
1.三次握手 置位概念:根据TCP的包头字段,存在3个重要的标识ACK.SYN.FIN ACK:表示验证字段 SYN:位数置1,表示建立TCP连接 FIN:位数置1,表示断开TCP连接 三次握手过程说 ...
- 学习saltstack (六)
Slatstack 介绍 官网:https://saltstack.com/ 官方源:http://repo.saltstack.com/ (介绍各操作系统安装方法) centos 6源 ? 1 y ...
- 学习Kvm(四)
安装KVM虚拟化 1.系统基础环境: [root@linux-node1 ~]# ip addr | grep inet | awk '{ print $2; }' | sed 's/\/.*$//' ...
- java的API
一.前端 1.jsp展示数据 (1)展示在前端控制台 console.table(参数); (2)弹窗 alert(参数); (3)JSLT的<c:if>标签 <c:if test= ...
- 从 输入网址(URL)到页面展示的过程
1.用户输入url网址(URL) 用户输入url(也就是我们说的网址,也是统一资源定义符,用于定义互联网资源) 比如输入https://www.baidu.com 其中https为协议 baidu.c ...
- nginx开启gzip和缓存配置
# 开启gzip gzip on; # 启用gzip压缩的最小文件,小于设置值的文件将不会压缩 gzip_min_length 1k; # gzip 压缩级别,1-10,数字越大压缩的越好,也越占用C ...
- python计算项目净现值和内部回报率
代码: import numpy as np from numpy import irr import warnings def project(number, period_list): rate ...
- java1.7之后的比较器特别之处
在jdk1.7环境下使用Collectons.sort()方法: 比如:Collections.sort(list, new Comparator<Integer>()); 就可能会出现异 ...
- 数据库查询中where和having的用法
1.类型: "baiWhere"是一个约束声明,在查询数据库du的结果返回之前对数据库中zhi的查询条件进行约束dao,即在结果返回之前起作用,且where后面不能使用" ...