MapReduce Shuffle And Sort
引言
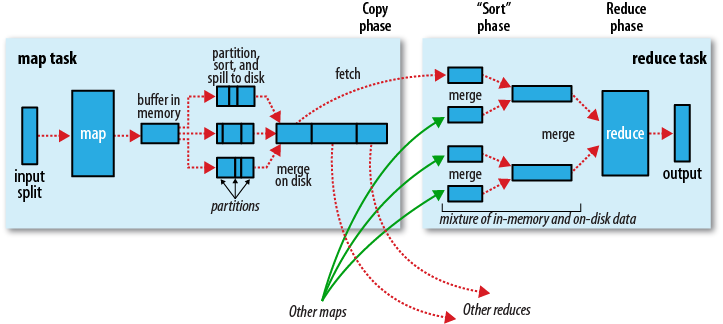
如果溢写文件个数超过3(通过属性min.num.spills.for.combine设置),会对合并且分区排序后的结果执行Combine过程(如果MapReduce有设置Combiner),而且combine过程在不影响最终结果的前提下可能会被执行多次;否则不会执行Combine过程(相对而言,Combine开销过大)。
@Override
public void write(K key, V value) throws IOException,
InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
public int compare(int i, int j) {
final int ii = kvoffsets[i % kvoffsets.length];
final int ij = kvoffsets[j % kvoffsets.length];
// sort by partition
if (kvindices[ii + PARTITION] != kvindices[ij + PARTITION]) {
return kvindices[ii + PARTITION] - kvindices[ij + PARTITION];
}
// sort by key
return comparator.compare(kvbuffer, kvindices[ii + KEYSTART],
kvindices[ii + VALSTART] - kvindices[ii + KEYSTART],
kvbuffer, kvindices[ij + KEYSTART],
kvindices[ij + VALSTART] - kvindices[ij + KEYSTART]);
}
public RawComparator getOutputKeyComparator() {
Class<? extends RawComparator> theClass = getClass(
"mapred.output.key.comparator.class", null, RawComparator.class);
if (theClass != null) {
return ReflectionUtils.newInstance(theClass, this);
}
return WritableComparator.get(getMapOutputKeyClass().asSubclass(
WritableComparable.class));
}
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
public class WritableComparator implements RawComparator {
private static HashMap<Class, WritableComparator> comparators = new HashMap<Class, WritableComparator>();
public static synchronized WritableComparator get(
Class<? extends WritableComparable> c) {
WritableComparator comparator = comparators.get(c);
if (comparator == null) {
comparator = new WritableComparator(c, true);
}
return comparator;
}
public static synchronized void define(Class c,
WritableComparator comparator) {
comparators.put(c, comparator);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
// parse key1
buffer.reset(b1, s1, l1);
key1.readFields(buffer);
// parse key2
buffer.reset(b2, s2, l2);
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
// compare them
return compare(key1, key2);
}
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}
public int compare(Object a, Object b) {
return compare((WritableComparable) a, (WritableComparable) b);
}
}
public abstract class Partitioner<KEY, VALUE> {
public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context)
throws IOException, InterruptedException {
......
}
MapReduce Shuffle And Sort的更多相关文章
- mapreduce shuffle 和sort 详解
MapReduce 框架的核心步骤主要分两部分:Map 和Reduce.当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执 ...
- Hadoop-2.2.0中文文档—— MapReduce下一代- 可插入的 Shuffle 和 Sort
简单介绍 可插入的 shuffle 和 sort 功能,同意在shuffle 和 sort 逻辑中用可选择的实现类替换.这个情况的样例是:用一个不是HTTP的应用协议,如RDMA来 shuffle 从 ...
- MapReduce中的Shuffle和Sort分析
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Scheme ...
- 【Hadoop】MapReduce笔记(三):MapReduce的Shuffle和Sort阶段详解
一.MapReduce 总体架构 整体的Shuffle过程包含以下几个部分:Map端Shuffle.Sort阶段.Reduce端Shuffle.即是说:Shuffle 过程横跨 map 和 reduc ...
- Hadoop : MapReduce中的Shuffle和Sort分析
地址 MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Sch ...
- MapReduce Shuffle过程
MapReduce Shuffle 过程详解 一.MapReduce Shuffle过程 1. Map Shuffle过程 2. Reduce Shuffle过程 二.Map Shuffle过程 1. ...
- MapReduce Shuffle原理 与 Spark Shuffle原理
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- shuffle和sort分析
MapReduce中的Shuffle和Sort分析 MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的 ...
随机推荐
- 【iOS】3D Touch
文章内容来源于Apple的开发者文档:https://developer.apple.com/library/content/documentation/UserExperience/Conceptu ...
- iOS 短信验证码倒计时按钮的实现
验证码倒计时按钮的应用是非常普遍的,本文介绍了IOS实现验证码倒计时功能,点击获取验证码,进入时间倒计时,感兴趣的小伙伴们可以参考一下: 实现思路: 创建按钮,添加点击方法: 用NSTimer定时器, ...
- 进阶篇,第二章:MC与Forge的Event系统
<基于1.8 Forge的Minecraft mod制作经验分享> 这一章其实才应该是第一章,矿物生成里面用到了Event的一些内容.如果你对之前矿物生成那一章的将算法插入ORE_GEN_ ...
- redis 中文手册
https://redis.readthedocs.org/en/latest/ http://www.cnblogs.com/ikodota/archive/2012/03/05/php_redis ...
- Apache MINA 框架之Handler介绍
IoHandler 具备以下几个功能: sessionCreated sessionOpened sessionClosed sessionIdle exceptionCaught messageRe ...
- codeforces 251A Points on Line(二分or单调队列)
Description Little Petya likes points a lot. Recently his mom has presented him n points lying on th ...
- HDU5317
题意:定义一个数K,最小质因数形式为K = a*b*c形式(如12 = 2*2*3),相同只取一个(所以12只能取2,3两个,既F[12]=2)给L,R区间,找出区间内最大的F[x](L<=x& ...
- servlet+jdbc+javabean其实跟ssh差不多
我给的这个架构可以代替ssh的架构进行项目的开发 common中放的是一些公用类 dao中放的是一些对数据的处理 entity其实也就是javabean service中放的是一些抽象类,简单来说抽象 ...
- 系统spt_values表--生成时间方便left join
时间处理我给你提供一个思路 系统有个spt_values表,可以构造一整个月的日期,然后左连接你统计好的数据,用CTE表构造多次查询 spt_values的超级经典的应用 http://www. ...
- Mac 安装maven3.3.9
只记录一部分自己出错的内容 maven 3 与 jdk 版本的关系 之前安装的jdk是1.8 安装完maven(包括配置环境变量)之后,输入mvn -version 显示版本错误 ,百度之后发现是ma ...