Hadoop MapReduce编程 API入门系列之wordcount版本4(八)
这篇博客,给大家,体会不一样的版本编程。
是将map、combiner、shuffle、reduce等分开放一个.java里。则需要实现Tool。
代码
package zhouls.bigdata.myMapReduce.wordcount2; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; //4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型
//map 和 reduce 的数据输入输出都是以 key-value对的形式封装的
//默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
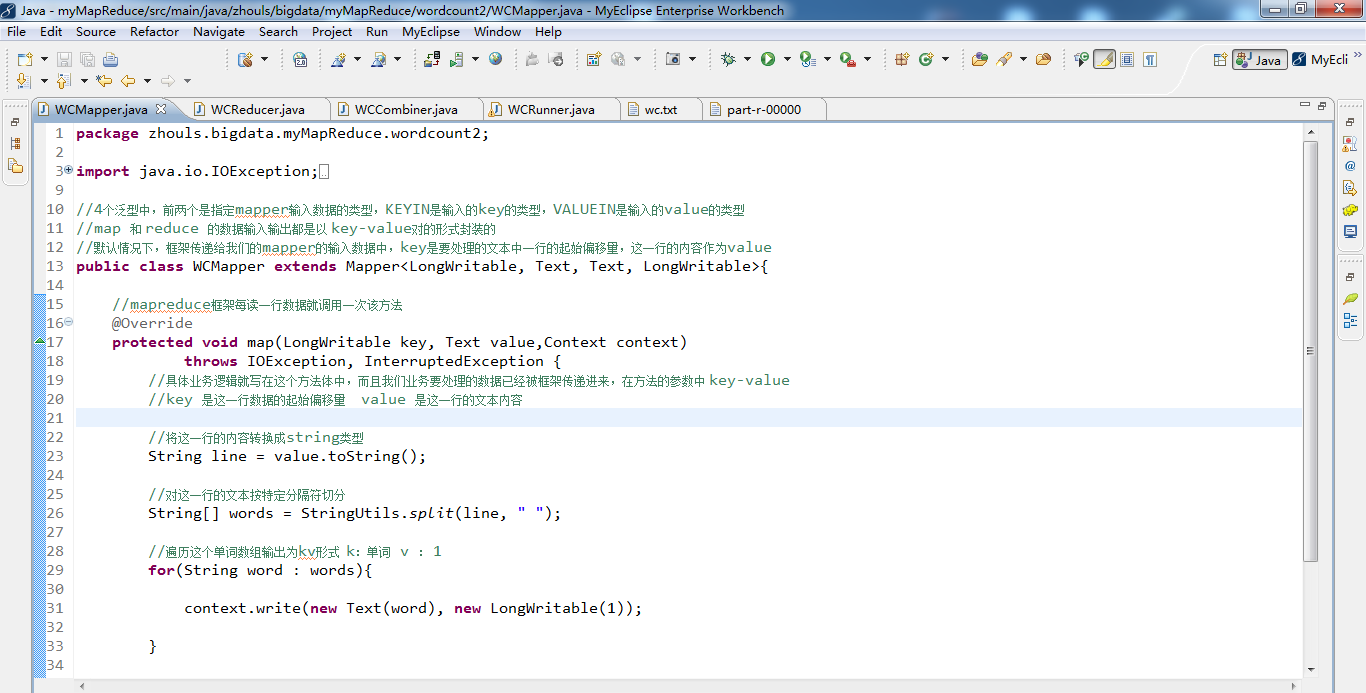
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ //mapreduce框架每读一行数据就调用一次该方法
@Override
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException{
//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中 key-value
//key 是这一行数据的起始偏移量 value 是这一行的文本内容 //将这一行的内容转换成string类型
String line = value.toString(); //对这一行的文本按特定分隔符切分
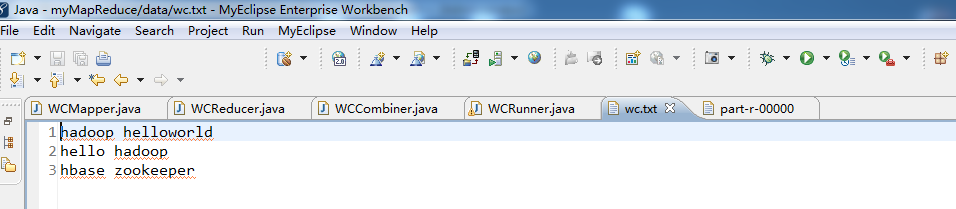
//hadoop helloworld
String[] words = StringUtils.split(line, " "); //遍历这个单词数组输出为kv形式 k:单词 v : 1
for(String word : words){//word是k2
context.write(new Text(word), new LongWritable(1));//写入word是k2,1是v2
// context.write(word,1);等价 } } }
package zhouls.bigdata.myMapReduce.wordcount2; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
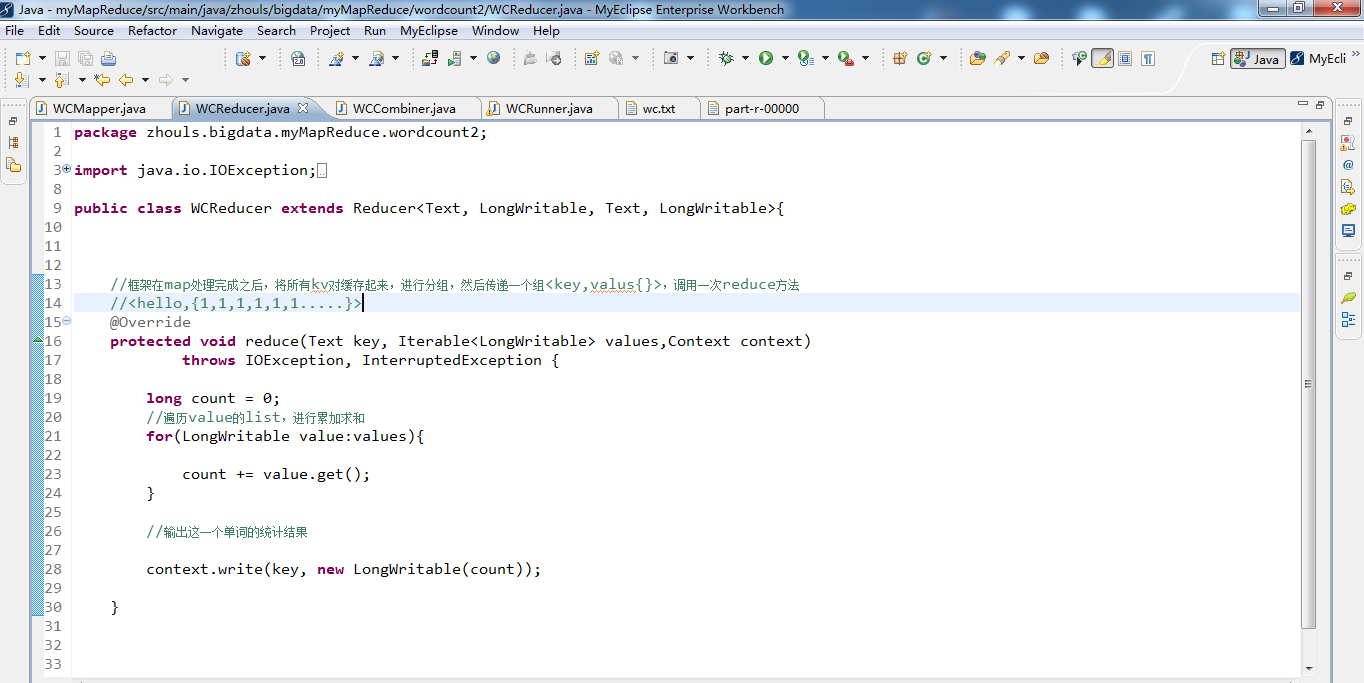
import org.apache.hadoop.mapreduce.Reducer; public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ //框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法
//<hello,{1,1,1,1,1,1.....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)throws IOException, InterruptedException {
long count = 0;
//遍历value的list,进行累加求和
for(LongWritable value:values){//value是v2
count += value.get();
} //输出这一个单词的统计结果 context.write(key,new LongWritable(count));//key是k3,count是v3
// context.write(key,count);
} }
package zhouls.bigdata.myMapReduce.wordcount2; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
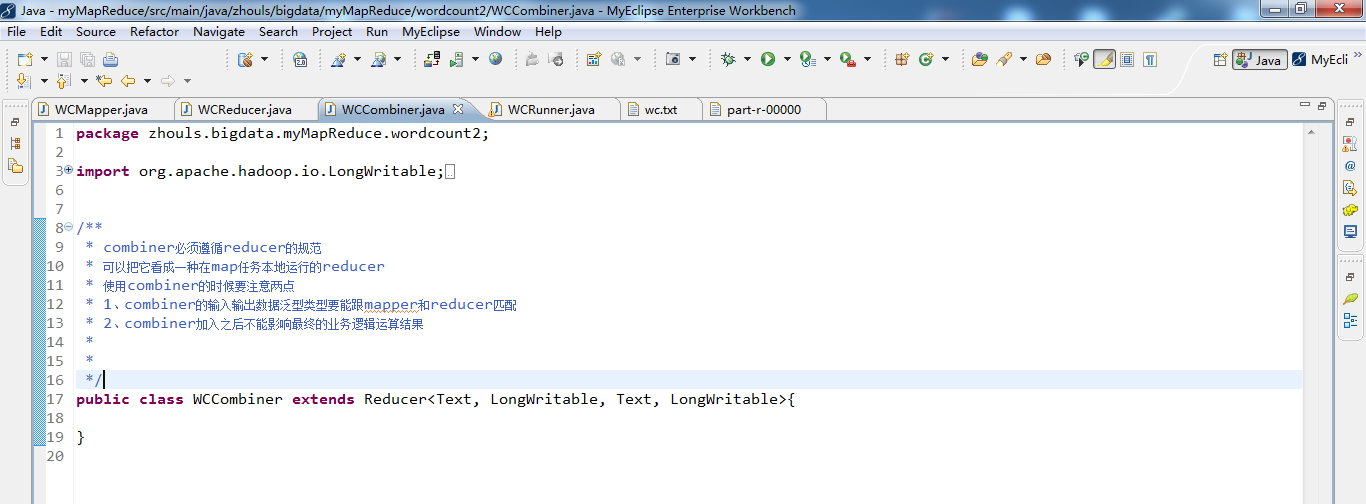
* combiner必须遵循reducer的规范
* 可以把它看成一种在map任务本地运行的reducer
* 使用combiner的时候要注意两点
* 1、combiner的输入输出数据泛型类型要能跟mapper和reducer匹配
* 2、combiner加入之后不能影响最终的业务逻辑运算结果
*
*
*/
public class WCCombiner extends Reducer<Text, LongWritable, Text, LongWritable>{ }
package zhouls.bigdata.myMapReduce.wordcount2; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 用来描述一个特定的作业
* 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce
* 还可以指定该作业要处理的数据所在的路径
* 还可以指定改作业输出的结果放到哪个路径
* ....
* @author duanhaitao@itcast.cn
*
*/
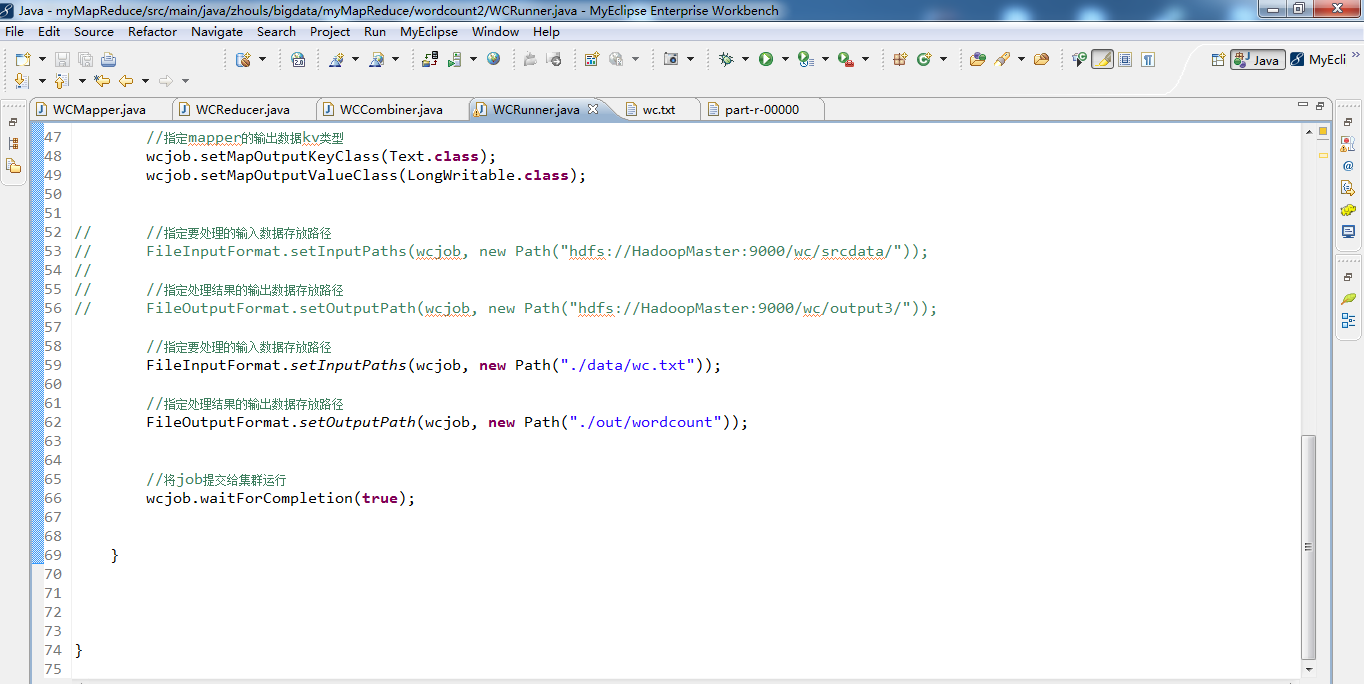
public class WCRunner { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包
wcjob.setJarByClass(WCRunner.class); //本job使用的mapper和reducer的类
wcjob.setMapperClass(WCMapper.class);
wcjob.setReducerClass(WCReducer.class); //指定本job使用combiner组件,组件所用的类为
wcjob.setCombinerClass(WCReducer.class); //指定reduce的输出数据kv类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(LongWritable.class); //指定mapper的输出数据kv类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(LongWritable.class); // //指定要处理的输入数据存放路径
// FileInputFormat.setInputPaths(wcjob, new Path("hdfs://HadoopMaster:9000/wordcount/wc.txt/"));
//
// //指定处理结果的输出数据存放路径
// FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://HadoopMaster:9000/out/wordcount/wc/")); //指定要处理的输入数据存放路径
FileInputFormat.setInputPaths(wcjob, new Path("./data/wordcount/wc.txt")); //指定处理结果的输出数据存放路径
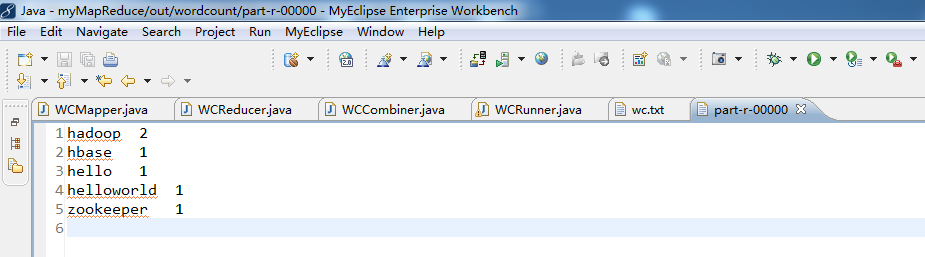
FileOutputFormat.setOutputPath(wcjob, new Path("./out/wordcount/wc/")); //将job提交给集群运行
wcjob.waitForCompletion(true); } }
Hadoop MapReduce编程 API入门系列之wordcount版本4(八)的更多相关文章
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之wordcount版本5(九)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount1; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之wordcount版本3(七)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount3; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之wordcount版本2(六)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount4; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
随机推荐
- c# 读取 XML
XmlDocument xmldoc = new XmlDocument(); string xmlPath = HttpContext.Server.MapPath("~/*****.xm ...
- shell 结合expect实现ssh登录并执行命令
#!/bin/bash ips=( '127.0.0.1' ) ;i<${#ips[*]};i++)) do expect <<EOF #这里的 expect <<EOF ...
- 【转载】Jmeter分布式部署测试-----远程连接多台电脑做压力性能测试
在使用Jmeter进行接口的性能测试时,由于Jmeter 是JAVA应用,对于CPU和内存的消耗比较大,所以,当需要模拟数以万计的并发用户时,使用单台机器模拟所有的并发用户就有些力不从心,甚至会引起J ...
- SSO 单点登录解决方案
转自:http://www.blogjava.net/Jack2007/archive/2014/03/11/191795.html 1 什么是单点登陆 单点登录(Single Sign O ...
- js中call、apply、bind的区别
var Person = { name : 'alice', say : function(txt1,txt2) { console.info(txt1+txt2); console.info(thi ...
- [jzoj 5770]【2018提高组模拟A组8.6】可爱精灵宝贝 (区间dp)
传送门 Description Branimirko是一个对可爱精灵宝贝十分痴迷的玩家.最近,他闲得没事组织了一场捉精灵的游戏.游戏在一条街道上举行,街道上一侧有一排房子,从左到右房子标号由1到n. ...
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- mysql 怎样先排序再分组
权游游牧族:众所周知!一句SqL语句不能先排序再分组.所以这里给出几个案例 --表结构-- create table `shop` ( `id` int (10) PRIMARY KEY, `shop ...
- 获取元素属性中的[x] 标签: javascript 2016-12-24 22:35 105人阅读 评论(0)
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content ...
- jQuery动态效果
1.一号店首页 2.淘宝网购物车