CUDA软件架构—网格(Grid)、线程块(Block)和线程(Thread)的组织关系以及线程索引的计算公式
网格(Grid)、线程块(Block)和线程(Thread)的组织关系
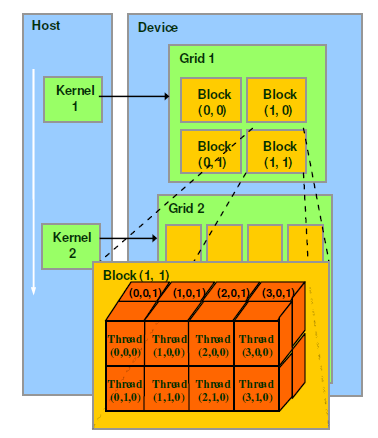
Thread,block,grid是CUDA编程上的概念,为了方便程序员软件设计,组织线程。
- thread:一个CUDA的并行程序会被以许多个threads来执行。
- block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
- grid:多个blocks则会再构成grid。
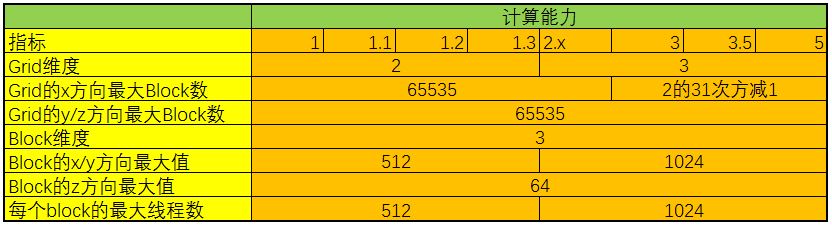
网格(Grid)、线程块(Block)和线程(Thread)的最大数量
线程索引的计算公式
int threadId = blockIdx.x *blockDim.x + threadIdx.x;
2、 grid划分成1维,block划分为2维
int threadId = blockIdx.x * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x;
3、 grid划分成1维,block划分为3维
int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z
+ threadIdx.z * blockDim.y * blockDim.x
+ threadIdx.y * blockDim.x + threadIdx.x;
4、 grid划分成2维,block划分为1维
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int threadId = blockId * blockDim.x + threadIdx.x;
5、 grid划分成2维,block划分为2维
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x) + threadIdx.x;
6、 grid划分成2维,block划分为3维
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
7、 grid划分成3维,block划分为1维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * blockDim.x + threadIdx.x;
8、 grid划分成3维,block划分为2维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x) + threadIdx.x;
9、 grid划分成3维,block划分为3维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
CUDA软件架构—网格(Grid)、线程块(Block)和线程(Thread)的组织关系以及线程索引的计算公式的更多相关文章
- CUDA学习(六)之使用共享内存(shared memory)进行归约求和(M个包含N个线程的线程块)
在https://www.cnblogs.com/xiaoxiaoyibu/p/11402607.html中介绍了使用一个包含N个线程的线程块和共享内存进行数组归约求和, 基本思路: 定义M个包含N个 ...
- 【并行计算-CUDA开发】CUDA线程、线程块、线程束、流多处理器、流处理器、网格概念的深入理解
GPU的硬件结构,也不是具体的硬件结构,就是与CUDA相关的几个概念:thread,block,grid,warp,sp,sm. sp: 最基本的处理单元,streaming processor 最 ...
- cuda线程/线程块索引小结
内建变量: threadIdx(.x/.y/.z代表几维索引):线程所在block中各个维度上的线程号 blockIdx(.x/.y/.z代表几维索引):块所在grid中各个维度上的块号 blockD ...
- 《GPU高性能编程CUDA实战》第四章 简单的线程块并行
▶ 本章介绍了线程块并行,并给出两个例子:长向量加法和绘制julia集. ● 长向量加法,中规中矩的GPU加法,包含申请内存和显存,赋值,显存传入,计算,显存传出,处理结果,清理内存和显存.用到了 t ...
- CUDA学习(四)之使用全局内存进行归约求和(一个包含N个线程的线程块)
问题:使用CUDA进行数组元素归约求和,归约求和的思想是每次循环取半. 详细过程如下: 假设有一个包含8个元素的数组,索引下标从0到7,现通过3次循环相加得到这8个元素的和,使用一个间隔变量,该间隔变 ...
- CUDA学习(五)之使用共享内存(shared memory)进行归约求和(一个包含N个线程的线程块)
共享内存(shared memory)是位于SM上的on-chip(片上)一块内存,每个SM都有,就是内存比较小,早期的GPU只有16K(16384),现在生产的GPU一般都是48K(49152). ...
- CUDA 关于 BLOCK数目与Thread数目设置
GPU的计算核心是以一定数量的Streaming Processor(SP)组成的处理器阵列,NV称之为Texture Processing Clusters(TPC),每个TPC中又包含一定数量的S ...
- Objective-C-----协议protocol,代码块block,分类category
概述 ObjC的语法主要基于smalltalk进行设计的,除了提供常规的面向对象特性外,还增加了很多其他特性,本文将重点介绍objective-C中一些常用的语法特性. 当然这些内容虽然和其他高级语言 ...
- Django---MTV和MVC的了解,Django的模版语言变量和逻辑,常见的模板语言过滤器,自定义过滤器,CSRF了解,Django的母版(继承extends,块block,组件include,静态文件的加载load static),自定义simple_tag和inclusion_tag
Django---MTV和MVC的了解,Django的模版语言变量和逻辑,常见的模板语言过滤器,自定义过滤器,CSRF了解,Django的母版(继承extends,块block,组件include,静 ...
随机推荐
- javascript进阶课程--第三章--匿名函数和闭包
javascript进阶课程--第三章--匿名函数和闭包 一.总结 二.学习要点 掌握匿名函数和闭包的应用 三.匿名函数和闭包 匿名函数 没有函数名字的函数 单独的匿名函数是无法运行和调用的 可以把匿 ...
- WSL(Windows上的Linux子系统)
WSL(Windows上的Linux子系统) WSL,Windows Subsystem for Linux,就是之前的Bash on [Ubuntu on] Windows(嗯,微软改名部KPI++ ...
- UVA 11280 - Flying to Fredericton SPFA变形
http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&c ...
- UITextField用法
.创建 .UITextField* textField = [[UITextField alloc]initWithFrame:CGRectMake(, , , )]; .设置委托 //委托类需要遵守 ...
- 17、网卡驱动程序-DM9000举例
(参考:cs89x0.c可以参考) DM9000 芯片实现网络功能的基础,在接收数据时采用中断方式,即当有数据到来并在 DM9000 内部 CRC 校验通过后会产生一个接收中断: 网卡驱动程序框架: ...
- python中有关字符串的处理
原文 Python 字符串操作(string替换.删除.截取.复制.连接.比较.查找.包含.大小写转换.分割等) 去空格及特殊符号 s.strip().lstrip().rstrip(',') 复制字 ...
- [AngularFire2] Auth with Firebase auth -- email
First, you need to enable the email auth in Firebase console. Then implement the auth service: login ...
- h5 video 点击自动全屏
加上如下属性 https://blog.csdn.net/weixin_40974504/article/details/79639478 可阻止自动全屏播放,感谢 https://blog.csdn ...
- 《SPA设计与架构》之MV*框架
原文 简书原文:https://www.jianshu.com/p/39f8f0aefdc2 大纲 1.认识MV*框架 2.传统UI设计模式 3.对框架的本质认识——框架有效性和框架分类 4.MV*基 ...
- text输入框改变事件
前端页面开发的很多情况下都需要实时监听文本框输入,比如腾讯微博编写140字的微博时输入框hu9i动态显示还可以输入的字数.过去一般都使用onchange/onkeyup/onkeypress/onke ...