Python爬虫爬取豆瓣读书
一,准备工作。
工具:win10+Python3.6
爬取目标:爬取图中红色方框的内容。
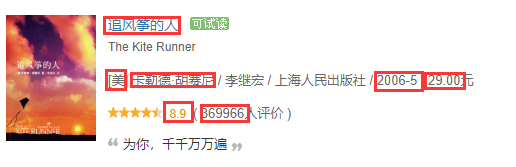
原则:能在源码中看到的信息都能爬取出来。
信息表现方式:CSV转Excel。
二,具体步骤。
先给出具体代码吧:
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd def gethtml(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "It is failed to get html!" def getcontent(url):
html = gethtml(url)
soup = BeautifulSoup(html,"html.parser")
# print(soup.prettify())
div = soup.find("div",class_="indent")
tables = div.find_all("table") price = []
date = []
nationality = []
nation = [] #standard
bookname=[]
link = []
score = []
comment = []
people = []
peo = [] #standard
author = []
for table in tables:
bookname.append(table.find_all("a")[1]['title']) #bookname
link.append(table.find_all("a")[1]['href']) #link
score.append(table.find("span",class_="rating_nums").string) #score
comment.append(table.find_all("span")[-1].string) #comment in a word people_info = table.find_all("span")[-2].text
people.append(re.findall(r'\d+', people_info)) #How many people comment on this book? Note:But there are sublist in the list. navistr = (table.find("p").string) #nationality,author,translator,press,date,price
infos = str(navistr.split("/")) #Note this info:The string has been interrupted.
infostr = str(navistr) #Note this info:The string has not been interrupted.
s = infostr.split("/")
if re.findall(r'\[', s[0]): # If the first character is "[",match the author.
w = re.findall(r'\s\D+', s[0])
author.append(w[0])
else:
author.append(s[0]) #Find all infomations from infos.Just like price,nationality,author,translator,press,date
price_info = re.findall(r'\d+\.\d+', infos)
price.append((price_info[0])) #We can get price.
date.append(s[-2]) #We can get date.
nationality_info = re.findall(r'[[](\D)[]]', infos)
nationality.append(nationality_info) #We can get nationality.Note:But there are sublist in the list.
for i in nationality:
if len(i) == 1:
nation.append(i[0])
else:
nation.append("中") for i in people:
if len(i) == 1:
peo.append(i[0]) print(bookname)
print(author)
print(nation)
print(score)
print(peo)
print(date)
print(price)
print(link) # 字典中的key值即为csv中列名
dataframe = pd.DataFrame({'书名': bookname, '作者': author,'国籍': nation,'评分': score,'评分人数': peo,'出版时间': date,'价格': price,'链接': link,}) # 将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv("C:/Users/zhengyong/Desktop/test.csv", index=False, encoding='utf-8-sig',sep=',') if __name__ == '__main__':
url = "https://book.douban.com/top250?start=0" #If you want to add next pages,you have to alter the code.
getcontent(url)
1,爬取大致信息。
选用如下轮子:
import requests
import re
from bs4 import BeautifulSoup def gethtml(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "It is failed to get html!" def getcontent(url):
html = gethtml(url)
bsObj = BeautifulSoup(html,"html.parser") if __name__ == '__main__':
url = "https://book.douban.com/top250?icn=index-book250-all"
getcontent(url)
这样就能从bsObj获取我们想要的信息。
2,信息具体提取。
所有信息都在一个div中,这个div下有25个table,其中每个table都是独立的信息单元,我们只用造出提取一个table的轮子(前提是确保这个轮子的兼容性)。我们发现:一个div父节点下有25个table子节点,用如下方式提取:
div = soup.find("div",class_="indent")
tables = div.find_all("table")
书名可以直接在节点中的title中提取(原始代码确实这么丑,但不影响):
<a href="https://book.douban.com/subject/1770782/" onclick=""moreurl(this,{i:'0'})"" title="追风筝的人">
追风筝的人
</a>
据如下代码提取:
bookname.append(table.find_all("a")[1]['title']) #bookname
相似的不赘述。
评价人数打算用正则表达式提取:
people.append(re.findall(r'\d+', people_info)) #How many people comment on this book? Note:But there are sublist in the list.
people_info = 13456人评价。
在看其余信息:
<p class="pl">[美] 卡勒德·胡赛尼 / 李继宏 / 上海人民出版社 / 2006-5 / 29.00元</p>
其中国籍有个“【】”符号,如何去掉?第一行给出回答。
nationality_info = re.findall(r'[[](\D)[]]', infos)
nationality.append(nationality_info) #We can get nationality.Note:But there are sublist in the list.
for i in nationality:
if len(i) == 1:
nation.append(i[0])
else:
nation.append("中")
其中有国籍的都写出了,但是没写出的我们发现都是中国,所以我们把国籍为空白的改写为“中”:
for i in nationality:
if len(i) == 1:
nation.append(i[0])
else:
nation.append("中")
还有list中存在list的问题也很好解决:
for i in people:
if len(i) == 1:
peo.append(i[0])
长度为1证明不是空序列,就加上序号填写处具体值,使变为一个没有子序列的序列。
打印结果如下图:

基本是我们想要的了。
然后写入csv:
dataframe = pd.DataFrame({'书名': bookname, '作者': author,'国籍': nation,'评分': score,'评分人数': peo,'出版时间': date,'价格': price,'链接': link,})
# 将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv("C:/Users/zhengyong/Desktop/test.csv", index=False, encoding='utf-8-sig',sep=',')
注意:如果没有加上encoding='utf-8-sig'会存在乱码问题,所以这里必须得加,当然你用其他方法也可。
最后一个翻页的问题,这里由于我没做好兼容性问题,所以后面的页码中提取信息老是出问题,但是这里还是写一下方法:
for i in range(10):
url = "https://book.douban.com/top250?start=" + str(i*25)
getcontent(url)
注意要加上str。
效果图:
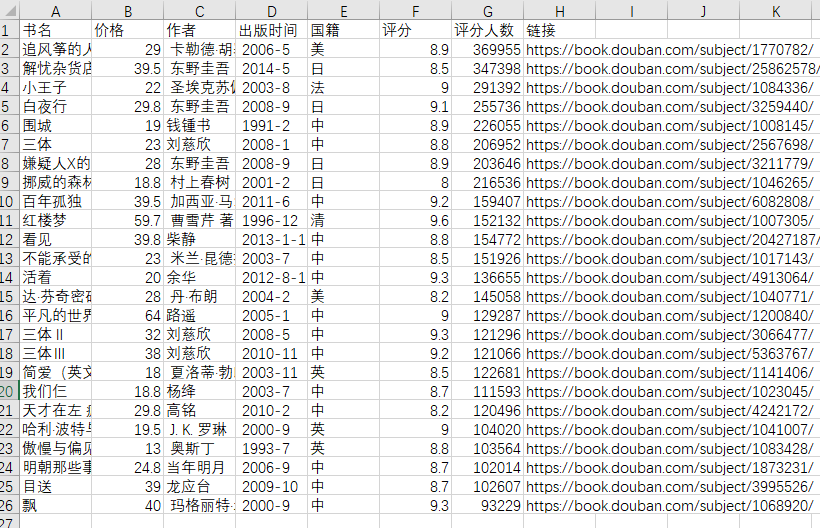
其实这里的效果图与我写入csv的传人顺序不一致,后期我会看看原因。
三,总结。
大胆细心,这里一定要细心,很多细节不好好深究后面会有很多东西修改。
Python爬虫爬取豆瓣读书的更多相关文章
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP.但也不要太频繁爬取. 涉及知识点:requests.html.xpath.csv 一.准备工作 需要安装reques ...
- 2019-02-01 Python爬虫爬取豆瓣Top250
这几天学了一点爬虫后写了个爬取电影top250的代码,分别用requests库和urllib库,想看看自己能不能搞出个啥东西,虽然很简单但还是小开心. import requests import r ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- Python爬虫爬取豆瓣电影名称和链接,分别存入txt,excel和数据库
前提条件是python操作excel和数据库的环境配置是完整的,这个需要在python中安装导入相关依赖包: 实现的具体代码如下: #!/usr/bin/python# -*- coding: utf ...
- Python爬虫-爬取豆瓣电影Top250
#!usr/bin/env python3 # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import re ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
随机推荐
- GDB程序调试工具
GDB程序调试工具 GDB主要完成下面三个方面的功能: 启动被调试程序 让被调试程序在指定的位置停住 当程序被停住时,可以检查程序状态 GDB快速入门 编译生成可执行文件 gcc -g test.c ...
- typescript + echarts-for-react 制作渐变柱状图, 提示[ts] 类型“Graphic”上不存在属性“LinearGradient”
更新: 2019/03 无意间发现Graphic上已有 LinearGradient属性
- 【模板】最长公共子序列(LCS)。
看过好多人的博客,感觉要么是太复杂要么就是太不容易理解. 那就亲自动手写一个通俗易懂的. 先定义两个数组,第一个数组为主,用第二个数组来匹配第一个,看能有多少可以对应上的. 所以,其实第一个数组的内容 ...
- [Kubernetes]容器日志的收集与管理
在开始这篇文章之前,首先要明确一点: Kubernetes 中对容器日志的处理方式,都叫做 cluster-level-logging ,也就是说,这个日志处理系统,与容器, Pod 以及 Node ...
- 将mysql中的一张表中的一个字段数据根据条件导入另一张表中
添加字段:alter table matInformation add facid varchar(99) default ''; 导入数据:update matInformation m set ...
- F - JDG HDU - 2112 (最短路)&& E - IGNB HDU - 1242 (dfs)
经过锦囊相助,海东集团终于度过了危机,从此,HDU的发展就一直顺风顺水,到了2050年,集团已经相当规模了,据说进入了钱江肉丝经济开发区500强.这时候,XHD夫妇也退居了二线,并在风景秀美的诸暨市浬 ...
- vue中展示数据
1.v-bind,直接把数据绑定进去了.*100是因为传过来的数据为数字0.3这样子,要转换成百分比 2.整个的数据再data中定义之后,就能在页面直接绑定,v-for,v-if等单独再设置.
- 文件上传的一个坑 Apache上传组件和SpringMVC自带上传冲突
List list = upload.parseRequest(request); 接受不到数据,size=0; 原因就是下面这货造成的 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ bean id=&qu ...
- Bootstrap-datepicker3官方文档中文翻译---Options/选项(原文链接 http://bootstrap-datepicker.readthedocs.io/en/latest/index.html)
Options/选项 带“Date”的所有选项都可以处理 Date 对象; 字符串格式化根据 给定的 format 而定; 相对于今天的时间变量, 如 “-1d”, “+6m +1y”等等, 其中有效 ...
- WPF使用CefSharp嵌入网页
1.点击项目应用下的管理NuGet程序包 2.在浏览中输入cefsharp-->查找 CefSharp.Wpf-->点击安装,等待安装完成 3.如果遇到一下问题将解决方案和项目都改成64位 ...