tensorflow Tensorboard可视化-【老鱼学tensorflow】
tensorflow自带了可视化的工具:Tensorboard。有了这个可视化工具,可以让我们在调整各项参数时有了可视化的依据。
本次我们先用Tensorboard来可视化Tensorflow的结构。
在输出tensorflow结构的关键步骤是:
writer = tf.summary.FileWriter("E:/todel/data/tensorflow", sess.graph)
这个函数中把当前的tensorflow的结构图输出到指定的目录下。
而为了能够使输出的结构能够有一定的分组,可以使用:
with tf.name_scope("xxx"):
只要用tf.name_scope()包含起来的代码就会分在一组中显示。
因此全部的示例代码如下:
import tensorflow as tf
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function=None):
"""
添加层
:param inputs: 输入数据
:param in_size: 输入数据的列数
:param out_size: 输出数据的列数
:param activation_function: 激励函数
:return:
"""
# 定义权重,初始时使用随机变量,可以简单理解为在进行梯度下降时的随机初始点,这个随机初始点要比0值好,因为如果是0值的话,反复计算就一直是固定在0中,导致可能下降不到其它位置去。
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
with tf.name_scope('biases'):
# 偏置shape为1行out_size列
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
with tf.name_scope("Wx_plus_b"):
# 建立神经网络线性公式:inputs * Weights + biases,我们大脑中的神经元的传递基本上也是类似这样的线性公式,这里的权重就是每个神经元传递某信号的强弱系数,偏置值是指这个神经元的原先所拥有的电位高低值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
# 如果没有设置激活函数,则直接就把当前信号原封不动地传递出去
outputs = Wx_plus_b
else:
# 如果设置了激活函数,则会由此激活函数来对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
import numpy as np
# 创建一列(相当于只有一个属性值),300行的x值,这里np.newaxis用于新建出列数据,使其shape为(300, 1)
x_data = np.linspace(-1, 1, 300)[:,np.newaxis]
# 增加噪点,噪点的均值为0,标准差为0.05,形状跟x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
# 定义y的函数为二次曲线的函数,但同时增加了一些噪点数据
y_data = np.square(x_data) - 0.5 + noise
# 定义输入值,这里定义输入值的目的是为了能够使程序比较灵活,可以在神经网络启动时接收不同的实际输入值,这里输入的结构为输入的行数不国定,但列就是1列的值
with tf.name_scope("inputs"):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# 定义一个隐藏层,输入为xs,输入size为1列,因为x_data就只有1个属性值,输出size我们假定输出的神经元有10个神经元的隐藏层,激励函数用relu
l1 = add_layer(xs, 1, 10, tf.nn.relu)
# 定义输出层,输入为l1,输入size为10列,也就是l1的列数,输出size为1,因为这里直接输出为类似y_data了,因此为1列,假定没有激励函数,也就是输出是啥就直接传递出去了。
predition = add_layer(l1, 10, 1, activation_function=None)
with tf.name_scope("loss"):
# 定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - predition), axis=1))
with tf.name_scope("train"):
# 进行逐步优化的梯度下降优化器,学习效率为0.1,以最小化损失函数的方式进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 初始化所有定义的变量
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
writer = tf.summary.FileWriter("E:/todel/data/tensorflow", sess.graph)
# 学习1000次
for i in range(1000):
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
# 打印期间的误差值,看这个误差值是否在减少
if i % 50 == 0:
# print(sess.run(loss, feed_dict={xs:x_data, ys:y_data}))
prediction_value = sess.run(predition, feed_dict={xs:x_data, ys:y_data})
执行以上代码后,会在指定的目录下生成相应的结构文件,而为了能够查看此文件,可以在命令行中输入:
tensorboard --logdir tensorflow
当然,上面的logdir根据读者自己设置的目录结构名来确定。
执行上面的命令后,会打印一个可以在浏览器中输入的URL,输入这个URL就会显示相应的tensorflow结构图:
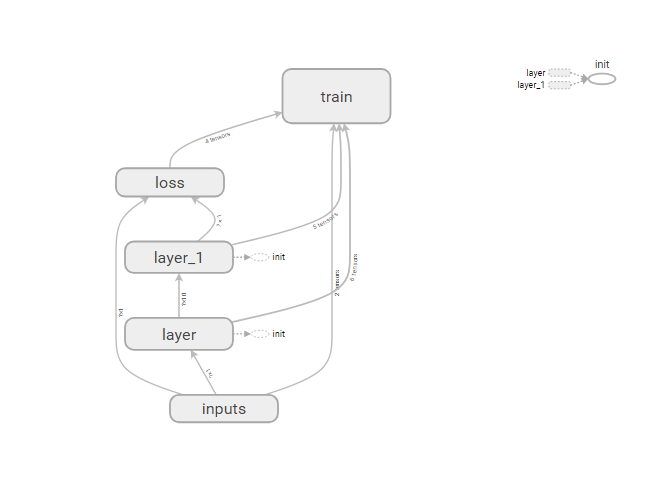
大家也可以自己尝试一下如果不输入那些烦人的tf.name_scope()进行分组而直接用 tf.summary.FileWriter进行输出其结构图是长啥样的。
tensorflow Tensorboard可视化-【老鱼学tensorflow】的更多相关文章
- tensorflow分类-【老鱼学tensorflow】
前面我们学习过回归问题,比如对于房价的预测,因为其预测值是个连续的值,因此属于回归问题. 但还有一类问题属于分类的问题,比如我们根据一张图片来辨别它是一只猫还是一只狗.某篇文章的内容是属于体育新闻还是 ...
- tensorflow安装-【老鱼学tensorflow】
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理.Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,Tensor ...
- tensorflow例子-【老鱼学tensorflow】
本节主要用一个例子来讲述一下基本的tensorflow用法. 在这个例子中,我们首先伪造一些线性数据点,其实这些数据中本身就隐藏了一些规律,但我们假装不知道是什么规律,然后想通过神经网络来揭示这个规律 ...
- tensorflow变量-【老鱼学tensorflow】
在程序中定义变量很简单,只要定义一个变量名就可以,但是tensorflow有点类似在另外一个世界,因此需要通过当前的世界中跟tensorlfow的世界中进行通讯,来告诉tensorflow的世界中定义 ...
- tensorflow激励函数-【老鱼学tensorflow】
当我们回到家,如果家里有异样,我们能够很快就会发现家中的异样,那是因为这些异常的摆设在我们的大脑中会产生较强的脑电波. 当我们听到某个单词,我们大脑中跟这个单词相关的神经元会异常兴奋,而同这个单词无关 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- tensorflow结果可视化-【老鱼学tensorflow】
这次我们把上次的结果进行可视化显示,我们会把神经网络的优化过程以图像的方式展示出来,方便我们了解神经网络是如何进行优化的. 首先,我们把测试数据显示出来: # 显示测试数据 fig = plt.fig ...
- tensorflow用dropout解决over fitting-【老鱼学tensorflow】
在机器学习中可能会存在过拟合的问题,表现为在训练集上表现很好,但在测试集中表现不如训练集中的那么好. 图中黑色曲线是正常模型,绿色曲线就是overfitting模型.尽管绿色曲线很精确的区分了所有的训 ...
- tensorflow Tensorboard2-【老鱼学tensorflow】
前面我们用Tensorboard显示了tensorflow的程序结构,本节主要用Tensorboard显示各个参数值的变化以及损失函数的值的变化. 这里的核心函数有: histogram 例如: tf ...
随机推荐
- 关于 redis 的 数据类型 和 内存模型
该文章 是在读了 公众号 : java 后端技术 之后 做的一个小记录 原文网址 : https://mp.weixin.qq.com/s/mI3nDtQdlVlLv2uUTxJegA 作者文章写的 ...
- Zabbix 监控触发器设置
简述 在生产环境中,有一台mysql的备份服务器,上面运行着三个数据库实例的从库,也在做日志的同步工作,为了实现对该备份服务器的监控,当出现从库实例不为3或者日志同步进程不为3的时候,产生告警通知,生 ...
- DB(1):SQLAPI catch [Bind variable/parameter 'pay_acc_id' not found] !!!
SQLAPI catch [Bind variable/parameter 'pay_acc_id' not found] !!! 出现这种报错,先检查命令类后面的参数是否混淆(SACommand s ...
- Linux系统下rm删除文件后空间没有释放问题解决办法
一.问题描述 今日收到zabbix监控报警,发现生产环境一台服务器的磁盘空间不足,需要进行处理,登录后发现可利用率不足20%,进行相关查看和处理工作:但是操作删除了一些备份文件和日志信息后,查看空间仍 ...
- Exp5 MSF基础应用
一.实践内容 1.主动攻击实践 [1]MS08-067 MS08-067 漏洞是2008 年年底爆出的一个特大漏洞,存在于当时的所有微软系统,杀伤力超强.其原理是攻击者利用受害主机默认开放的SMB 服 ...
- django环境部署 crm和路飞学城
环境依赖 yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-de ...
- [NLP] 酒店名归类
目标: 我们内部系统里记录的酒店名字是由很多人输入的,每个人输入的可能不完全一样,比如,‘成都凯宾斯基大酒店’, ‘凯宾斯基酒店’, ‘凯宾斯基’, 我们的初步想法是能不能把大量的记录归类,把很多相似 ...
- jQuery手机触屏拖动滑块验证跳转插件
HTML: <!DOCTYPE html> <html lang="en"> <head> <title>jQuery手机触屏拖动滑 ...
- windows下搭建Kafka,并通过命令窗口收发消息
参考网址: https://blog.csdn.net/ydc321/article/details/70154278 前提条件:windows环境需要安装jdk 1.下载Kafka,可以通过官网下载 ...
- linux oops调试
参考文章: arm 指令定位错误 https://blog.csdn.net/songcdut/article/details/41383483 linux mips指令学习 https://www. ...