Spark学习笔记——读写HDFS
使用Spark读写HDFS中的parquet文件
文件夹中的parquet文件

build.sbt文件
name := "spark-hbase" version := "1.0" scalaVersion := "2.11.8" libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.1.0",
"mysql" % "mysql-connector-java" % "5.1.31",
"org.apache.spark" %% "spark-sql" % "2.1.0",
"org.apache.hbase" % "hbase-common" % "1.3.0",
"org.apache.hbase" % "hbase-client" % "1.3.0",
"org.apache.hbase" % "hbase-server" % "1.3.0",
"org.apache.hbase" % "hbase" % "1.2.1"
)
Scala实现方法
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql._
import java.util.Properties
import com.google.common.collect.Lists
import org.apache.spark.sql.types.{ArrayType, StringType, StructField, StructType}
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
/**
* Created by mi on 17-4-11.
*/
case class resultset(name: String,
info: String,
summary: String)
case class IntroItem(name: String, value: String)
case class BaikeLocation(name: String,
url: String = "",
info: Seq[IntroItem] = Seq(),
summary: Option[String] = None)
case class MewBaikeLocation(name: String,
url: String = "",
info: Option[String] = None,
summary: Option[String] = None)
object MysqlOpt {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//定义数据库和表信息
val url = "jdbc:mysql://localhost:3306/baidubaike?useUnicode=true&characterEncoding=UTF-8"
val table = "baike_pages"
//读取parquetFile,并写入Mysql
val sparkSession = SparkSession.builder()
.master("local")
.appName("spark session example")
.getOrCreate()
val parquetDF = sparkSession.read.parquet("/home/mi/coding/coding/baikeshow_data/baikeshow")
// parquetDF.collect().take(20).foreach(println)
//parquetDF.show()
//BaikeLocation是读取的parquet文件中的case class
val ds = parquetDF.as[BaikeLocation].map { line =>
//把info转换为新的case class中的类型String
val info = line.info.map(item => item.name + ":" + item.value).mkString(",")
//注意需要把字段放在一个case class中,不然会丢失列信息
MewBaikeLocation(name = line.name, url = line.url, info = Some(info), summary = line.summary)
}.cache()
ds.show()
// ds.take(2).foreach(println)
//写入Mysql
// val prop = new Properties()
// prop.setProperty("user", "root")
// prop.setProperty("password", "123456")
// ds.write.mode(SaveMode.Append).jdbc(url, "baike_location", prop)
//写入parquetFile
ds.repartition(10).write.parquet("/home/mi/coding/coding/baikeshow_data/baikeshow1")
}
}
df.show打印出来的信息,如果没放在一个case class中的话,name,url,info,summary这列信息会变成1,2,3,4

使用spark-shell查看写回去的parquet文件的信息
#进入spark-shell
import org.apache.spark.sql.SQLContext
val sqlContext = new SQLContext(sc)
val path = "file:///home/mi/coding/coding/baikeshow_data/baikeshow1"
val df = sqlContext.parquetFile(path)
df.show
df.count

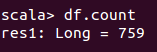
如果只想显示某一列的话,可以这么做
df.select("title").take(100).foreach(println) //只显示title这一列的信息
Spark学习笔记——读写HDFS的更多相关文章
- Spark学习笔记——读写Hbase
1.首先在Hbase中建立一张表,名字为student 参考 Hbase学习笔记——基本CRUD操作 一个cell的值,取决于Row,Column family,Column Qualifier和Ti ...
- Spark学习笔记——读写MySQL
1.使用Spark读取MySQL中某个表中的信息 build.sbt文件 name := "spark-hbase" version := "1.0" scal ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
随机推荐
- tmux使用心得
1,在终端输入tmux命令进入tmux, control+b x,关闭tmux的初始化session 2,创建自己的session,然后进行分屏
- PHP抓取网页内容经验总结
用php 抓取页面的内容在实际的开发当中是非常有用的,如作一个简单的内容采集器,提取网页中的部分内容等等,抓取到的内容在通过正则表达式做一下过滤就得到了你想要的内容,至于如何用正则表达式过滤,在这里就 ...
- filter的dispatcher节点
1.FORWARD (1)a.jsp页面内容如此<jsp:forward page="/b.jsp"></jsp:forward> (2) a.jsp页面内 ...
- 关于ADO.Net SqlConnection的性能优化
Connections Database connections are an expensive and limited resource. Your approach to connection ...
- Delphi的接口委托示例
{ 说明:该事例实现的效果,在单个应用或代码量小的项目中,可以完全不用接口委托来完成. 之所以采用委托接口,主要是应用到:已经实现的接口模块中,在不改变原有代码的情况下, 需要对其进行扩展:原始 ...
- Oracle 11g不同情形下的登录分析
对于Oracle刚開始学习的人.甚至有些经验的Oracle DBA来说,Oracle的账户登录问题往往非常棘手.即便成功登录oracle也是知其然而不知其所以然. 作者经过系统学习和重复实践,本着打破 ...
- MySql之触发器的使用
一:触发器的使用场景 当数据库的记录发生变化时,自动触发某些操作. MySQL的触发器响应三种操作,六种场合: 三种操作:DELETE.INSERT.UPDATE. 六种场合:三种操作的BEFORE. ...
- 下载网易云音乐的MV
网易云音乐有很多经典视频, 但是苦于没有下载按钮...今天就记录下如何保存MV到本地, 又get一项新技能!!! 一. 安装360极速浏览器(非安利) 二. 打开网易云音乐客户端, 点击"等 ...
- IP子系统集成
IP子系统集成 1.Creating External Connections 由此可以看出:block design的设计是可以连接电路板上的CPU的(外挂CPU). 2.生成外部接口 端口生成之后 ...
- Python中的format()函数
普通格式化方法 (%s%d)生成格式化的字符串,其中s是一个格式化字符串,d是一个十进制数; 格式化字符串包含两部分:普通的字符和转换说明符(见下表), 将使用元组或映射中元素的字符串来替换转换说明符 ...