Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中《Memory usage of state in Spark Structured Streaming》讲解Spark内存分配情况,以及提到了HDFSBackedStateStoreProvider存储多个版本的影响;从stackoverflow上也可以看到别人遇到了structured streaming中内存问题,同时也对问题做了分析《Memory issue with spark structured streaming》;另外可以从spark的官网问题修复列表中查看到如下内容:
1)在流聚合中从值中删除冗余密钥数据(Split out min retain version of state for memory in HDFSBackedStateStoreProvider)
问题描述:
HDFSBackedStateStoreProvider has only one configuration for minimum versions to retain of state which applies to both memory cache and files. As default version of "spark.sql.streaming.minBatchesToRetain" is set to high (100), which doesn't require strictly 100x of memory, but I'm seeing 10x ~ 80x of memory consumption for various workloads. In addition, in some cases, requiring 2x of memory is even unacceptable, so we should split out configuration for memory and let users adjust to trade-off memory usage vs cache miss.
In normal case, default value '2' would cover both cases: success and restoring failure with less than or around 2x of memory usage, and '1' would only cover success case but no longer require more than 1x of memory. In extreme case, user can set the value to '0' to completely disable the map cache to maximize executor memory.
修复情况:
对应官网bug情况概述《[SPARK-24717][SS] Split out max retain version of state for memory in HDFSBackedStateStoreProvider #21700》、《Split out min retain version of state for memory in HDFSBackedStateStoreProvider》
相关知识:
《Spark Structrued Streaming源码分析--(三)Aggreation聚合状态存储与更新》
HDFSBackedStateStoreProvider存储state的目录结构在该文章中介绍的,另外这些文件是一个系列,建议可以多读读,下边借用作者文章中的图展示下state存储目录结构:
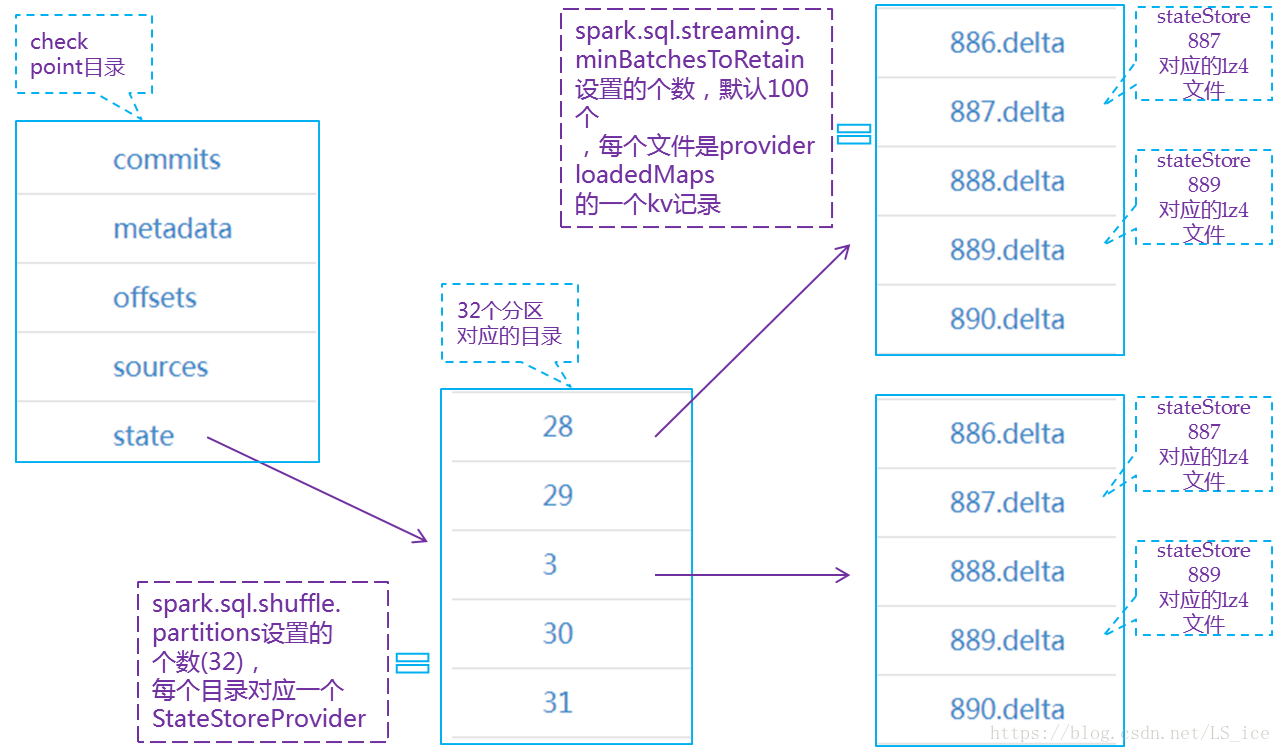
2)在HDFSBackedStateStoreProvider中为内存分配最大保留版本的状态(Remove redundant key data from value in streaming aggregation)
问题描述:
Key/Value of state in streaming aggregation is formatted as below:
- key: UnsafeRow containing group-by fields
- value: UnsafeRow containing key fields and another fields for aggregation results
which data for key is stored to both key and value.
This is to avoid doing projection row to value while storing, and joining key and value to restore origin row to boost performance, but while doing a simple benchmark test, I found it not much helpful compared to "project and join". (will paste test result in comment)
So I would propose a new option: remove redundant in stateful aggregation. I'm avoiding to modify default behavior of stateful aggregation, because state value will not be compatible between current and option enabled.
修复情况:
对应官网bug情况概述《[SPARK-24763][SS] Remove redundant key data from value in streaming aggregation #21733》、《Remove redundant key data from value in streaming aggregation》
可能能解决问题的另外办法:在spark2.3版本下自定义StateStoreProviver《https://github.com/chermenin/spark-states》
Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研的更多相关文章
- NeHe OpenGL教程 第三十八课:资源文件
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- Java进阶(三十八)快速排序
Java进阶(三十八)快速排序 前言 有没有既不浪费空间又可以快一点的排序算法呢?那就是"快速排序"啦!光听这个名字是不是就觉得很高端呢. 假设我们现在对"6 1 2 7 ...
- SQL注入之Sqli-labs系列第三十八关、第三十九关,第四十关(堆叠注入)
0x1 堆叠注入讲解 (1)前言 国内有的称为堆查询注入,也有称之为堆叠注入.个人认为称之为堆叠注入更为准确.堆叠注入为攻击者提供了很多的攻击手段,通过添加一个新 的查询或者终止查询,可以达到修改数据 ...
- 微信小程序把玩(三十八)获取设备信息 API
原文:微信小程序把玩(三十八)获取设备信息 API 获取设备信息这里分为四种, 主要属性: 网络信息wx.getNetWorkType, 系统信息wx.getSystemInfo, 重力感应数据wx. ...
- 《手把手教你》系列技巧篇(三十八)-java+ selenium自动化测试-日历时间控件-下篇(详解教程)
1.简介 理想很丰满现实很骨感,在应用selenium实现web自动化时,经常会遇到处理日期控件点击问题,手工很简单,可以一个个点击日期控件选择需要的日期,但自动化执行过程中,完全复制手工这样的操作就 ...
- bp(net core)+easyui+efcore实现仓储管理系统——入库管理之二(三十八)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统——ABP总体介绍(一) abp(net core)+ ...
- Deep learning:三十八(Stacked CNN简单介绍)
http://www.cnblogs.com/tornadomeet/archive/2013/05/05/3061457.html 前言: 本节主要是来简单介绍下stacked CNN(深度卷积网络 ...
- 【FastDev4Android框架开发】打造QQ6.X最新版本号側滑界面效果(三十八)
转载请标明出处: http://blog.csdn.net/developer_jiangqq/article/details/50253925 本文出自:[江清清的博客] (一).前言: [好消息] ...
- Spark2.2(三十九):如何根据appName监控spark任务,当任务不存在则启动(任务存在当超过多久没有活动状态则kill,等待下次启动)
业务需求 实现一个根据spark任务的appName来监控任务是否存在,及任务是否卡死的监控. 1)给定一个appName,根据appName从yarn application -list中验证任务是 ...
随机推荐
- 分布式任务调度系统xxl-job搭建(基于docker)
一.简介 XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并接入多家公司线上产品线,开箱即用. 更多介绍,请访问官网: http://w ...
- 存储过程+Jquery+WebService实现三级联动:
首先看一下数据库的设计:
- JQuery编写自己的插件(七)
一:jQuery插件的编写基础1.插件的种类编写插件的目的是给一系列已经方法或函数做一个封装,以便在其他地方重复使用,方便后期维护和提高开发效率.常见的种类有以下三种:封装对象方法的插件
- Ext.js入门:TreePanel(九)
一:最简单的树 二:通过TreeNode自定义静态树 三:用TreeLoader加载数据生成树 四:解决IE下非正常加载节点问题 五:使用TreeNodeUI 六:带有checkbox的树 七:编辑树 ...
- icomet研究
官方文档https://github.com/ideawu/icomet/wiki 如何实现的长连接:noop: 心跳消息+HTTP endless chunk 以班级ID为主键,进行班级通道的创建: ...
- python第三方包安装方法(两种方法)
具体有以下两种方法: 第一种方法(不使用pip或者easy_install): Step1:在网上找到的需要的包,下载下来.eg. rsa-3.1.4.tar.gz Step2:解压缩该文件. Ste ...
- 037 关于pom.xml的一些问题的理解
最近在pom上出了一些问题,搞了一天才理解了一些问题,记录一下. 当在覆盖本地repository包之后,pom.xml上面出现了一个x. 当mvn->update project之后,还是有许 ...
- Word 如何设置空白页不编码,其他页码连续
或许 不是最简单的方法: 先假设 空白页前的那部分为“第一部分”,空白页后的那部分为“第二部分”. 首先插入2个“分节符”, 将第一部分.空白页.第二部分分成三节(记得取消每一节的“链接到前一条页眉 ...
- 由自定义事件到vue数据响应
前言 除了大家经常提到的自定义事件之外,浏览器本身也支持我们自定义事件,我们常说的自定义事件一般用于项目中的一些通知机制.最近正好看到了这部分,就一起看了下自定义事件不同的实现,以及vue数据响应的基 ...
- Ubuntu18.10&Ubuntu18.04安装Python虚拟环境
Ubuntu18.04版本里面自带了最新的Python3.6.5版本,在安装Python虚拟环境时需注意: 1.首先是安装两个包 pip3 install virtualenv # python虚拟环 ...