入门大数据---Map/Reduce,Yarn是什么?
简单概括:Map/Reduce是分布式离线处理的一个框架。 Yarn是Map/Reduce中的一个资源管理器。
一.图形说明下Map/Reduce结构:
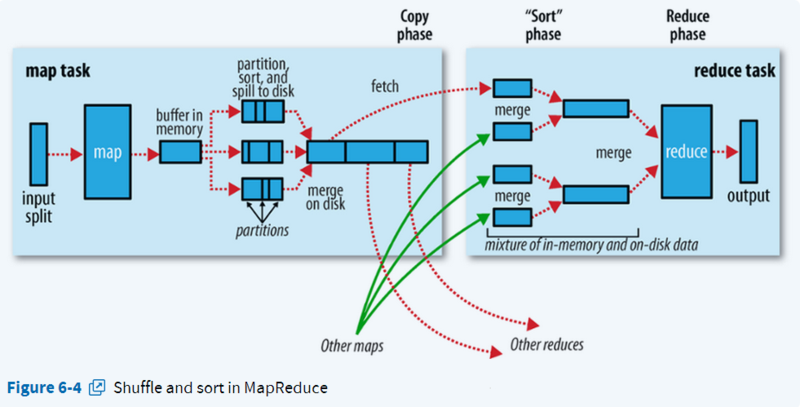
官方示意图:
另外还可以参考这个:
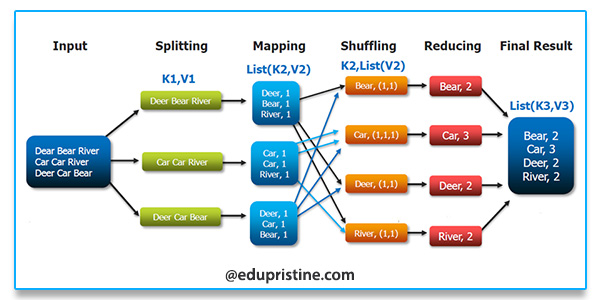
流程介绍:
HDFS首先会把块进行逻辑上切片处理,然后进行Map映射。一个切片对应一个Map映射。
因为文件内容有可能一个单词被切到两个文件里面,这样计算就会有问题,所以Map映射时除了第一个切片完全映射,其余的映射都会从第二行开始映射,而第一行传递给上一个Map处理。
Map程序初始化会设定一个阈值,比如80%,当超过这个值的时候就会就会进行内存溢出。溢出前会进行一个【快速排序】,排完后写入硬盘分区。(不设置阈值,当内存满后,就会阻塞数据继续写入。设定的阈值根据实际情况设定,太小了会增加读写压力,太大了会产生阻塞。)
程序可以设置合并操作,当分区数超过设定值后就进行合并(combiner)。(比如分区>3后)(合并后,相同key的数据就压缩了,拉取的时候就会减少IO)
Reduce会检查是否Map完,有一个Map完后就能拉取一次。
Reduce拉取的时候会有一个真迭代器和一个假迭代器进行嵌套,比如一组数据 A 1 A 1 A 1 B 1,假迭代器会进行循环然后取下一条数据进行比较看是否相同,相同的话进行累加值,再取下一条,这样下一条下一条的取,直到key不相同时候,结束本组循环,进行下一组循环。 这样A就统计出3,B就统计出1来了。
二.图形说明下Yarn的结构:
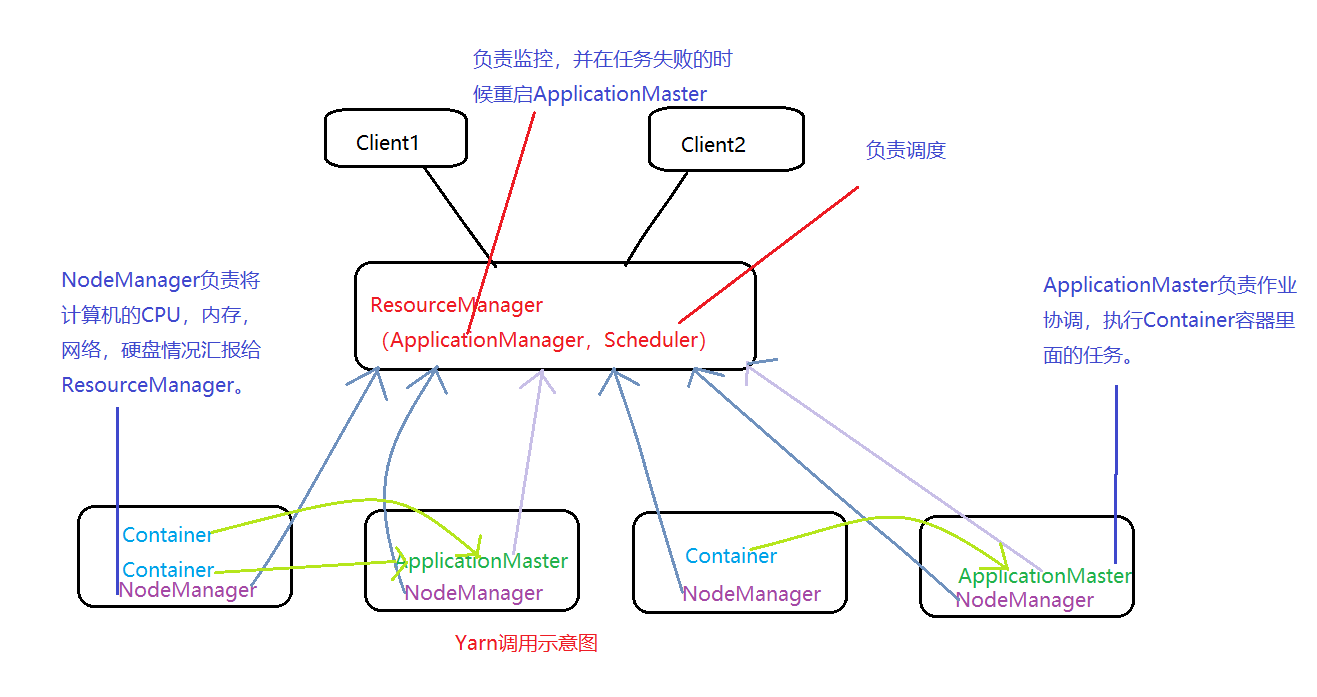
流程介绍:首先Client请求ResourceManager,然后ResourceManager分配一个Container启动ApplicationMaster,ApplicatoinMaster向ResourceManager请求分配更多Container。Container一部分执行Map任务,一部分执行Reduce任务。
三.图形说明下Map/Reduce和Yarn在整个Hadoop系统中的位置以及为什么产生Yarn:
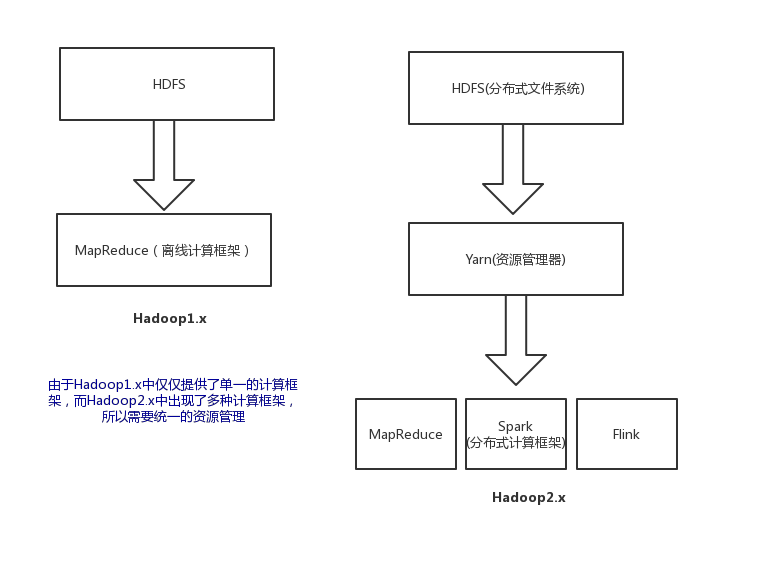
由于产生了多种计算框架,所以需要一个资源管理器来对资源进行分配使用。
系列传送门 学习官网: http://hadoop.apache.org/
入门大数据---Map/Reduce,Yarn是什么?的更多相关文章
- 大数据篇:YARN
YARN YARN是什么? YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率.资源统一管理和数据共享等方面带来了巨大 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Hive数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件 emp.txt 和 dept.txt 可以从本仓库的resources 目录下载. 1.1 员工表 -- 建表语句 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---通过Flume、Sqoop分析日志
一.Flume安装 参考:Flume 简介及基本使用 二.Sqoop安装 参考:Sqoop简介与安装 三.Flume和Sqoop结合使用案例 日志分析系统整体架构图: 3.1配置nginx环境 请参考 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
随机推荐
- jchdl - GSL Port
https://mp.weixin.qq.com/s/DVmMrCFgNLuZDtssQ85w7A org.jchdl.model.gsl.core.meta.Port.java gen ...
- Chisel3 - util - Pipe
https://mp.weixin.qq.com/s/WeFesE8k0ORxlaNfLvDzgg 流水线,用于添加延迟. 参考链接: https://github.com/freechips ...
- 万字超强图文讲解AQS以及ReentrantLock应用(建议收藏)
| 好看请赞,养成习惯 你有一个思想,我有一个思想,我们交换后,一个人就有两个思想 If you can NOT explain it simply, you do NOT understand it ...
- Mysql查询语句,select,inner/left/right join on,group by.....[例题及答案]
创建如下表格,命名为stu_info, course_i, score_table. 题目: 有如图所示的三张表结构,学生信息表(stu_info),课程信息表(course_i),分数信息表(sco ...
- Java实现 LeetCode 429 N叉树的层序遍历
429. N叉树的层序遍历 给定一个 N 叉树,返回其节点值的层序遍历. (即从左到右,逐层遍历). 例如,给定一个 3叉树 : 返回其层序遍历: [ [1], [3,2,4], [5,6] ] 说明 ...
- Java实现 LeetCode 357 计算各个位数不同的数字个数
357. 计算各个位数不同的数字个数 给定一个非负整数 n,计算各位数字都不同的数字 x 的个数,其中 0 ≤ x < 10n . 示例: 输入: 2 输出: 91 解释: 答案应为除去 11, ...
- Java实现 LeetCode70 爬楼梯
70. 爬楼梯 假设你正在爬楼梯.需要 n 阶你才能到达楼顶. 每次你可以爬 1 或 2 个台阶.你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数. 示例 1: 输入: 2 输出: ...
- Java实现第九届蓝桥杯缩位求和
缩位求和 题目描述 在电子计算机普及以前,人们经常用一个粗略的方法来验算四则运算是否正确. 比如:248 * 15 = 3720 把乘数和被乘数分别逐位求和,如果是多位数再逐位求和,直到是1位数,得 ...
- Linux 源码包安装过程
安装准备 安装gcc编译器 下载源码包 源代码保存位置:/usr/local/src/ 软件安装位置:/usr/local/ 解压缩下载的源码包 进入解压缩目录 软件配置与检查:./configure ...
- 【Nodejs】HTML 实时同步(类似Vue实时同步刷新文件->浏览器)
1. 安装 Node.js BrowserSync是基于Node.js的, 是一个Node模块, 如果您想要快速使用它,也许您需要先安装一下Node.js安装适用于Mac OS,Windows和Lin ...