Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf
Main Points:
- Encoder-Decoder Framework: Encoder uses a convolutional neural network to extract a set of feature vectors which the authors refer to as annotation vectors. The extractor produces L vectors, each of which is a D-dimensional representation corresponding to a part of the image. a = { a1, ..., aL }, ai ∈ RD. In order to obtain a correspondence between the feature vectors and portions of the 2-D image, they extract features from a lower convolutional layer unlike previous work which instead used a fully connected layer. This allows the decoder to selectively focus on certain parts of an image by weighting a subset of all the feature vectors. Decoder uses a LSTM network to produce a caption by generating one word at every time step conditioned on a context vector, the previous hidden state and the previously generated words.
- Two attention-based image caption generators under a common framework: a "soft" deterministic attention mechanism trainable by standard back-propagation methods; and a "hard" stochastic attention mechanism trainable by maximizing an approximate variational lower bound or equivalently by Reinforce.
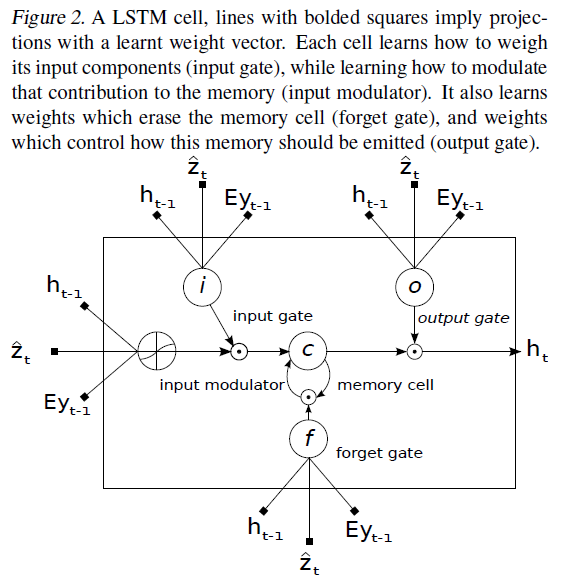
Other Key Points:
- Rather than compress an entire image into a static representation, attention allows for salient features to dynamically come to the forefront as needed. This is especially important when there is a lot of clutter in an image. Using representations ( such as those from the very top layer of a conv net ) that distill information in image down to the most salient objects is one effective solution that has been widely adopted in previous work. Unfortunately, this has one potential drawback of losing information which could be useful for richer, more descriptive captions. Using lower-level representation can help preserve this information.
Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )的更多相关文章
- [Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
论文链接:https://arxiv.org/pdf/1502.03044.pdf 代码链接:https://github.com/kelvinxu/arctic-captions & htt ...
- 论文笔记:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 2018-08-10 10:15:06 Pap ...
- 论文:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention-阅读总结
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention-阅读总结 笔记不能简单的抄写文中的内容,得有自 ...
- Paper Reading - Show and Tell: A Neural Image Caption Generator ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4555 Main Points: A generative model ( NIC, GoogLeNet ...
- [Paper Reading] Show and Tell: A Neural Image Caption Generator
论文链接:https://arxiv.org/pdf/1411.4555.pdf 代码链接:https://github.com/karpathy/neuraltalk & https://g ...
- [Paper Reading] Image Captioning using Deep Neural Architectures (arXiv: 1801.05568v1)
Main Contributions: A brief introduction about two different methods (retrieval based method and gen ...
- Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning
Link of the Paper: https://arxiv.org/abs/1805.09019 Innovations: The authors propose a CNN + CNN fra ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
随机推荐
- 【译】2分钟介绍Rx
原文地址:https://medium.com/@andrestaltz/2-minute-introduction-to-rx-24c8ca793877 翻译去掉了一些口水话(⊙o⊙) 诸位应该已经 ...
- Linux 运维工程师学习成长路线上要经历哪四个阶段?
之前曾看到一篇新闻,Linux之父建议大家找一份基于Linux和开源环境的工作.今天就来聊一聊我的想法,本人8年Linux运维一线经验,呆过很多互联网公司,从一线运维做到运维架构师一职,也见证了中国运 ...
- Java三种代理模式
本文转自:https://mp.weixin.qq.com/s/nBmbNP2mR7ei-lDsuOxjWg 代理模式 代理(Proxy)是一种设计模式,提供了对目标对象另外的访问方式;即通过代理对象 ...
- Delphi Math单元函数
本文转至http://blog.sina.com.cn/s/blog_976ba8a501010vvf.html 这个单元包含高性能的算术.三角.对数.统计和金融方面的计算及FPU程序函数用于补充De ...
- Oracle之基础操作
sqlplus常用命令: 进入sqlplus模式:sqlplus /nolog 管理员登录: conn / as sysdba 登录本机的数据库 conn sys/123456 as sysdba 普 ...
- transform Vs Udf
在鞋厂的第一个任务,拆表.需要把订单表按照开始日期和结束日期拆分成多条记录,挺新鲜的~ transform方式,使用到了python. (1)把hive表的数据传入,通过python按照日期循环处理, ...
- PAT A1060 (Advanced Level) Practice
If a machine can save only 3 significant digits, the float numbers 12300 and 12358.9 are considered ...
- 流程控制之--if。
假如把写程序比做走路,那我们到现在为止,一直走的都是直路,还没遇到过分叉口,想象现实中,你遇到了分叉口,然后你决定往哪拐必然是有所动机的.你要判断那条岔路是你真正要走的路,如果我们想让程序也能处理这样 ...
- c语言程序设计:用strcpy比较数组(银行卡密码程序设计),strcpy(复制数组内容)和getchar()(敲键盘字符,统计不想要的字符的个数)
统计从键盘输入一行字符的个数: 1 //用了getchar() 语句 2 //这里的\n表示回车 #include <stdio.h> #include <stdlib.h> ...
- Python入门 (三)
迭代器与生成器 迭代器 迭代是Python最强大的功能之一,是访问集合元素的一种方式. 迭代器是一个可以记住遍历的位置的对象. 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器 ...