JDK源码学习笔记——LinkedHashMap
HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。
LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。通过维护一个双向链表实现。
需要在理解HashMap实现原理的基础上学习LinkedHashMap,JDK源码学习笔记——HashMap
一、数据结构
实际上就是在HashMap的基础上加了LinkedList

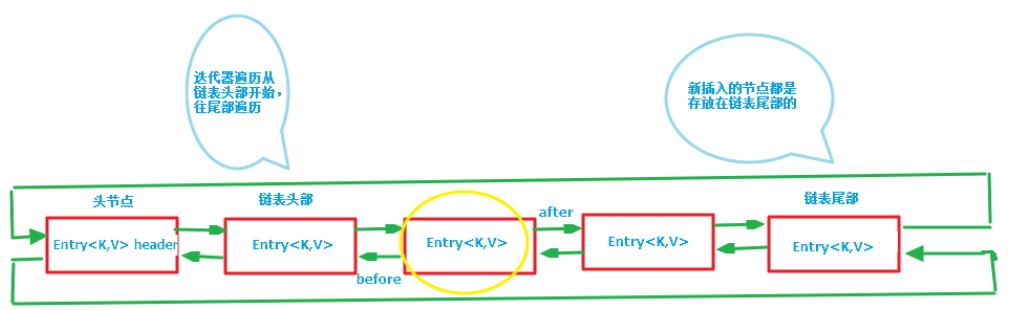
(图片来自Java集合之LinkedHashMap)
LinkedHashMap.Entry继承了HashMap.Node,并扩展了before ,after属性
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
二、类
继承了HashMap
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
三、属性
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
final boolean accessOrder;//true表示按照访问顺序迭代(最近访问在后),false时表示按照插入顺序(先插入在前,默认)
四、主要方法
put
/**
* 直接使用HashMap的put方法
* 重写了newNode()方法:维护双向链表
* 重写了afterNodeAccess(e)方法:如果按访问顺序排序,把node移动到双链表的尾端
*/
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
} void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
get
/**
* 重写了get方法
* 如果按访问顺序排序,把node移动到双链表的尾端
*/
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);// 如果按访问顺序排序,把node移动到双链表的尾端
return e.value;
}
remove
/**
* 直接使用HashMap的remove方法
* 重写了afterNodeRemoval()方法:维护双端链表
*/
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
遍历
/**
* 主要看nextNode()方法
* 直接遍历的双向链表
*/
final class LinkedKeyIterator extends LinkedHashIterator implements Iterator<K> {
public final K next() {
return nextNode().getKey();
}
} final class LinkedValueIterator extends LinkedHashIterator implements Iterator<V> {
public final V next() {
return nextNode().value;
}
} final class LinkedEntryIterator extends LinkedHashIterator implements Iterator<Map.Entry<K, V>> {
public final Map.Entry<K, V> next() {
return nextNode();
}
} abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount; LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
} public final boolean hasNext() {
return next != null;
} final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
} public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
JDK源码学习笔记——LinkedHashMap的更多相关文章
- jdk源码阅读笔记-LinkedHashMap
Map是Java collection framework 中重要的组成部分,特别是HashMap是在我们在日常的开发的过程中使用的最多的一个集合.但是遗憾的是,存放在HashMap中元素都是无序的, ...
- JDK源码学习笔记——String
1.学习jdk源码,从以下几个方面入手: 类定义(继承,实现接口等) 全局变量 方法 内部类 2.hashCode private int hash; public int hashCode() { ...
- JDK源码学习笔记——Integer
一.类定义 public final class Integer extends Number implements Comparable<Integer> 二.属性 private fi ...
- JDK源码学习笔记——Enum枚举使用及原理
一.为什么使用枚举 什么时候应该使用枚举呢?每当需要一组固定的常量的时候,如一周的天数.一年四季等.或者是在我们编译前就知道其包含的所有值的集合. 利用 public final static 完全可 ...
- JDK源码学习笔记——Object
一.源码解析 public class Object { /** * 一个本地方法,具体是用C(C++)在DLL中实现的,然后通过JNI调用 */ private static native void ...
- JDK源码学习笔记——HashMap
Java集合的学习先理清数据结构: 一.属性 //哈希桶,存放链表. 长度是2的N次方,或者初始化时为0. transient Node<K,V>[] table; //最大容量 2的30 ...
- JDK源码学习笔记——HashSet LinkedHashSet TreeSet
你一定听说过HashSet就是通过HashMap实现的 相信我,翻一翻HashSet的源码,秒懂!! 其实很多东西,只是没有静下心来看,只要去看,说不定一下子就明白了…… HashSet 两个属性: ...
- JDK源码学习笔记——TreeMap及红黑树
找了几个分析比较到位的,不再重复写了…… Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例 [Java集合源码剖析]TreeMap源码剖析 java源码分析之TreeMap基础篇 ...
- JDK源码学习笔记——LinkedList
一.类定义 public class LinkedList<E> extends AbstractSequentialList<E> implements List<E& ...
随机推荐
- Linux汇编教程01: 基本知识
在我们开始学习Linux汇编之前,需要简单的了解一下计算机的体系结构.我们不需要特别深入的了解,理解了一些基本概念对与我们理解程序会很有帮助.现在计算机的结构体系都是采用冯诺依曼体系结构的基础上发展过 ...
- 【Android XML】Android XML 转 Java Code 系列之 style(3)
最近一个月把代码重构了一遍, 感觉舒服多了, 但总体开发进度没有变化.. 今天聊聊把style属性转换成Java代码的办法 先说结论: 引用系统style是无法完美的实现的, 我们如果有写成Java代 ...
- 设计模式之笔记--抽象工厂模式(Abstract Factory)
抽象工厂模式(Abstract Factory) 定义 抽象工厂模式(Abstract Factory),提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类. 类图 描述 多个抽象产品 ...
- mongodb循环
var rds = db.REGIPATIENTREC.find({mzh:{$lt:"0"},usrOrg:"石景山中西医结合医院"}); var show ...
- tornado样板
python tornado 样版 (包含出错页面) 2018-02-27 13:07:30 1 # -*- coding:utf-8 -*- 2 3 import tornado.web 4 i ...
- 安装Hadoop2.7和hive2.0以及redis
安装过程很简单,主要记录期间碰到的问题: 安装过程: 下载安装包: hadoop:http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7. ...
- awk处理之案例五:awk匹配字段2包含字段1的文本
编译环境 本系列文章所提供的算法均在以下环境下编译通过. [脚本编译环境]Federa 8,linux 2.6.35.6-45.fc14.i686 [处理器] Intel(R) Core(TM)2 Q ...
- Restore IP Addresses——边界条件判定
Given a string containing only digits, restore it by returning all possible valid IP address combina ...
- 181. Employees Earning More Than Their Managers
The Employee table holds all employees including their managers. Every employee has an Id, and there ...
- Accord.NET入门
0.序 园子里介绍Accord.NET的文章不少,但是具体讲如何使用的反而不多,可能跟.NET在机器学习领域应用不多有关.诚然,如果做项目的话,可能用Python更好一些,但是如果把了解Accord. ...