spark 先groupby 再从每个group里面选top n
import spark.implicits._
val simpleData = Seq(("James","Sales","NY",90000,34,10000),
("Michael","Sales","NY",86000,56,20000),
("Robert","Sales","CA",81000,30,23000),
("Maria","Finance","CA",90000,24,23000),
("Raman","Finance","CA",99000,40,24000),
("Scott","Finance","NY",83000,36,19000),
("Jen","Finance","NY",79000,53,15000),
("Jeff","Marketing","CA",80000,25,18000),
("Kumar","Marketing","NY",91000,50,21000)
)
val df = simpleData.toDF("employee_name","department","state","salary","age","bonus")
df.show()
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window // Window definition
val w = Window.partitionBy($"department").orderBy(desc("bonus")) // Filter
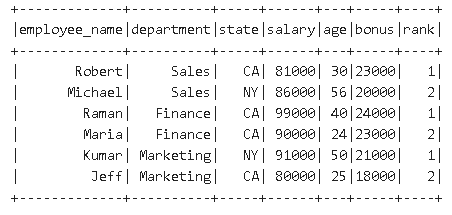
var df_1 = df.withColumn("rank", rank.over(w)).where($"rank" <= 2) df_1.show()
spark 先groupby 再从每个group里面选top n的更多相关文章
- 点击div全选中再点击取消全选div里面的文字
想做一个就是点击一个div然后实现的功能是div里面的文字都成选中状态,然后就可以利用浏览器的自带的复制功能,任意复制在哪里去了 在网上百度了一下 然后网上的答案感觉很大的范围 然后一些搜索 然后就锁 ...
- radio点击一下选中,再点击恢复未选状态
radio点击一下选中,再点击恢复未选状态 实现方式1: <input type="radio" id="cat" name="ca ...
- Spark中groupBy groupByKey reduceByKey的区别
groupBy 和SQL中groupby一样,只是后面必须结合聚合函数使用才可以. 例如: hour.filter($"version".isin(version: _*)).gr ...
- Spark算子 - groupBy
释义 根据RDD中的某个属性进行分组,分组后形式为(k, [(k, v1), (k, v2), ...]),即groupBy 后组内元素会保留key值 方法签名如下: def groupBy[K](f ...
- spark 笔记 13: 再看DAGScheduler,stage状态更新流程
当某个task完成后,某个shuffle Stage X可能已完成,那么就可能会一些仅依赖Stage X的Stage现在可以执行了,所以要有响应task完成的状态更新流程. ============= ...
- flex 4 写皮肤
皮肤容器:s:SparkSkin 主机组件: [HostComponent("spark.components.Panel")] 绘制: <s:Group left=&qu ...
- Spark在处理数据的时候,会将数据都加载到内存再做处理吗?
对于Spark的初学者,往往会有一个疑问:Spark(如SparkRDD.SparkSQL)在处理数据的时候,会将数据都加载到内存再做处理吗? 很显然,答案是否定的! 对该问题产生疑问的根源还是对Sp ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- Spark迷思
眼下在媒体上有非常大的关于Apache Spark框架的声音,渐渐的它成为了大数据领域的下一个大的东西. 证明这件事的最简单的方式就是看google的趋势图: 上图展示的过去两年Hadoop和Spar ...
- spark HelloWorld程序(scala版)
使用本地模式,不需要安装spark,引入相关JAR包即可: <dependency> <groupId>org.apache.spark</groupId> < ...
随机推荐
- SpringCloud注册中心切换nacos
SpringBoot与nacos版本对应关系 https://github.com/alibaba/spring-cloud-alibaba/wiki/%E7%89%88%E6%9C%AC%E8%AF ...
- oeasy教您玩转 linux 010212 管道 pipe
上一部分我们都讲了什么? 牛说cowsay 牛可以有各种表情 可以自定义眼睛 可以变成各种别的小动物 可以说也可以想cowthink 我们也想让牛说出字符画的感觉 回顾字符画 下载figlet和toi ...
- [oeasy]python0018_ ASCII_字符分布_数字_大小写字母_符号_黑暗森林
打包和解包 回忆上次内容 decode 就是解码 解码和编码可以转化 encode 编码 decode 解码 互为逆过程 大小写字母之间序号全都相差(32)10进制 编辑 这是 ...
- 阅读翻译Mathematics for Machine Learning之2.5 Linear Independence
阅读翻译Mathematics for Machine Learning之2.5 Linear Independence 关于: 首次发表日期:2024-07-18 Mathematics for M ...
- ABC362
A link 判断即可... 点击查看代码 #include<bits/stdc++.h> using namespace std; int r,g,b; string c; signed ...
- OI-Wiki 学习笔记
算法基础 \(\text{Update: 2024 - 07 - 22}\) 复杂度 定义 衡量一个算法的快慢,一定要考虑数据规模的大小. 一般来说,数据规模越大,算法的用时就越长. 而在算法竞赛中, ...
- [rCore学习笔记 017]实现批处理操作系统
写在前面 本随笔是非常菜的菜鸡写的.如有问题请及时提出. 可以联系:1160712160@qq.com GitHhub:https://github.com/WindDevil (目前啥也没有 本章目 ...
- Python获取指定网段正在使用的IP
Python获取指定网段正在使用的IP #!/usr/bin/env python # -*- coding: utf-8 -*- ''''' 使用方法样例 python test20.py 192. ...
- 【Flutter】基础环境搭建
一.下载 安装 配置 Android Studio 官网下载地址: https://developer.android.google.cn/studio?hl=zh-cn SDK下载,代理配置问题: ...
- 普通用户权限运行docker
docker安装后默认权限是管理员,在Ubuntu系统中需要使用sudo命令,但是很多时候docker的拉取操作都是写在脚步里面的,因此执行的时候十分的难搞,如果给脚本sudo权限后那么整个的环境路径 ...