python爬虫——《英雄联盟》英雄及皮肤图片
还记得那些年一起网吧开黑通宵的日子吗?《英雄联盟》绝对是大学时期的风靡游戏,即使毕业多年的大学同学相聚,难免不怀念一番当时一起玩《英雄联盟》的日子。
今天就给大家分享一下英雄及皮肤图片的爬虫。
一开始都是先去《英雄联盟》官网找到英雄及皮肤图片的网址:
URL = r'https://lol.qq.com/data/info-heros.shtml'![]()
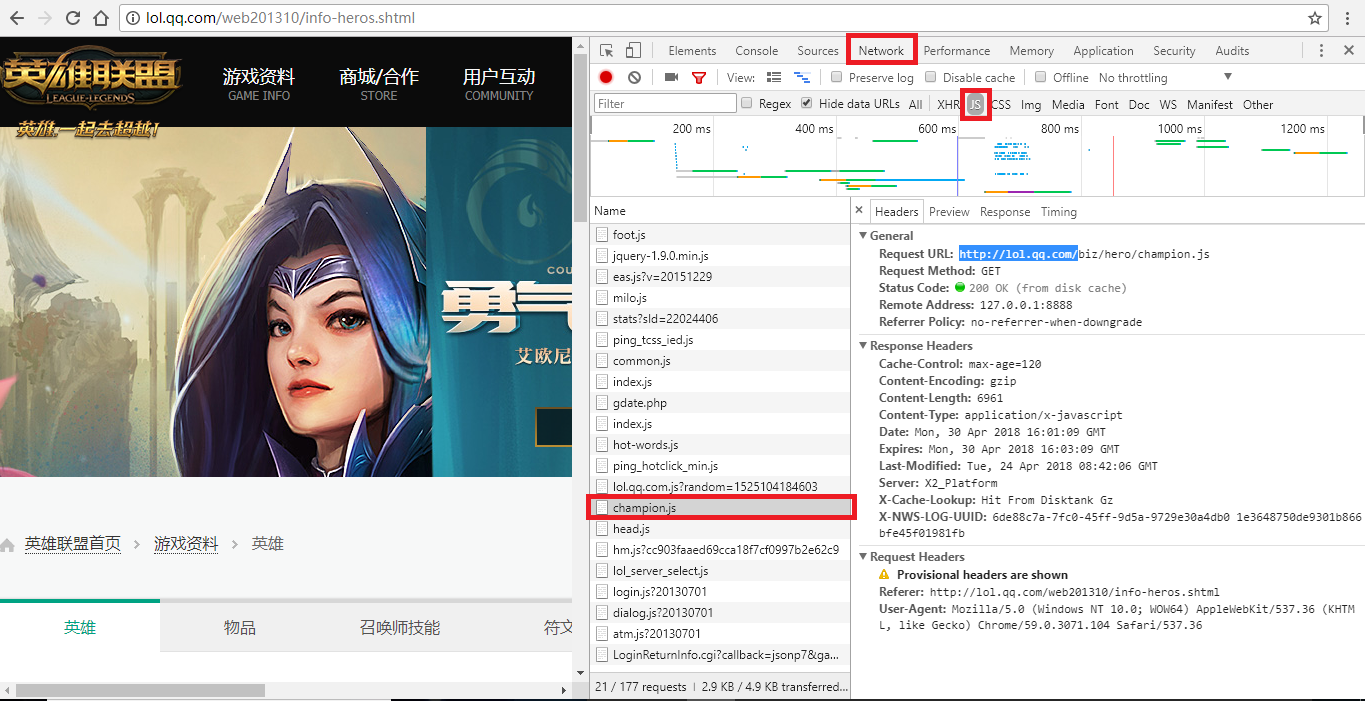
从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中。这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典——里面就包含了所有英雄的名字(英文)以及对应的编号(如下图)。
![]()
但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是回到网页,随便点开一个英雄,跳转页面后发现英雄及皮肤的图片都在,但要下载还需要找到原地址,这是鼠标右击选择“在新标签页中打开”,新的网页才是图片的原地址(如下图)。
![]()
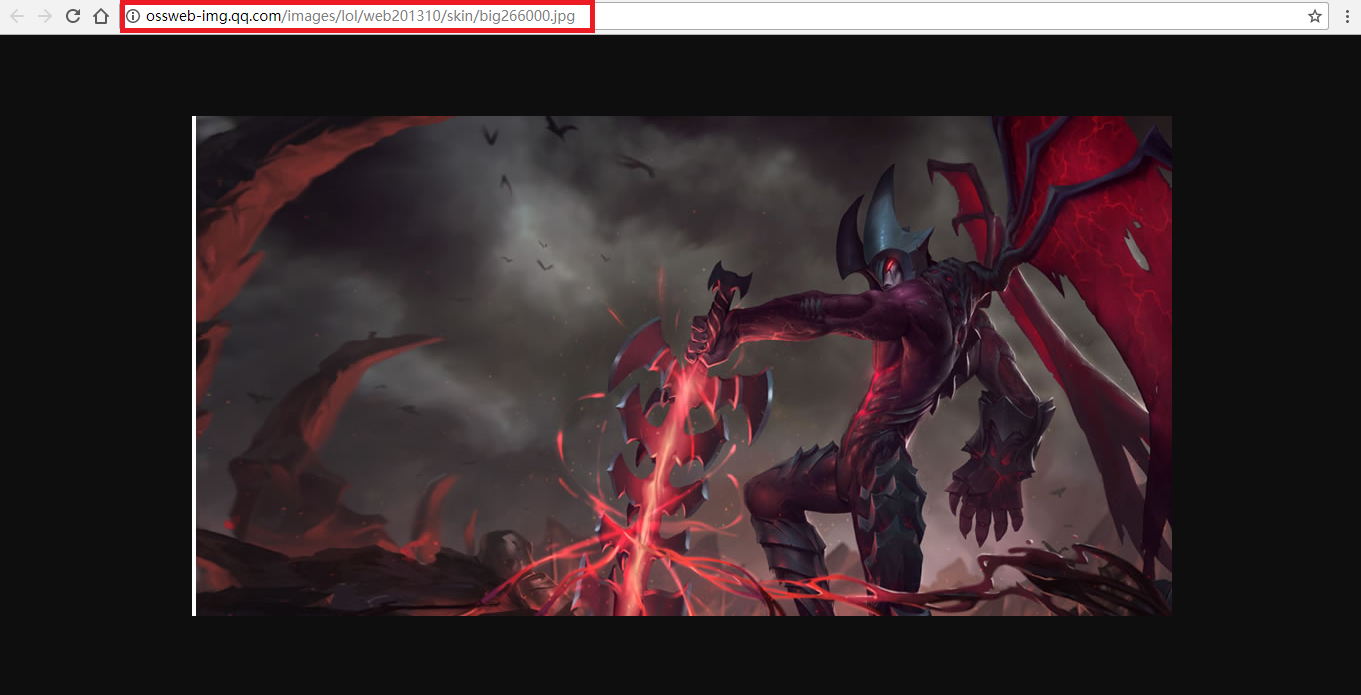
图中红色框就是我们需要的图片地址,经过分析知道:每一个英雄及皮肤的地址只有编号不一样(http://ossweb-img.qq.com/images/lol/web201310/skin/big266000.jpg),而该编号有6位,前3位表示英雄,后三位表示皮肤。刚才找到的js文件中恰好有英雄的编号,而皮肤的编码可以自己定义,反正每个英雄皮肤不超过20个,然后组合起来就可以了。
图片地址搞掂都就可以开始写程序了:
第一步:获取js字典
def path_js(url_js):
res_js = requests.get(url_js, verify = False).content
html_js = res_js.decode("gbk")
pat_js = r'"keys":(.*?),"data"'
enc = re.compile(pat_js)
list_js = enc.findall(html_js)
dict_js = eval(list_js[0])
return dict_js![]()
第二步:从 js字典中提取到key值生成url列表
def path_url(dict_js):
pic_list = []
for key in dict_js:
for i in range(20):
xuhao = str(i)
if len(xuhao) == 1:
num_houxu = "00" + xuhao
elif len(xuhao) == 2:
num_houxu = "0" + xuhao
numStr = key+num_houxu
url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big'+numStr+'.jpg'
pic_list.append(url)
print(pic_list)
return pic_list![]()
第三步:从 js字典中提取到value值生成name列表
def name_pic(dict_js, path):
list_filePath = []
for name in dict_js.values():
for i in range(20):
file_path = path + name + str(i) + '.jpg'
list_filePath.append(file_path)
return list_filePath![]()
第四步:下载并保存数据
def writing(url_list, list_filePath):
try:
for i in range(len(url_list)):
res = requests.get(url_list[i], verify = False).content
with open(list_filePath[i], "wb") as f:
f.write(res)
except Exception as e:
print("下载图片出错,%s" %(e))
return False![]()
执行主程序:
if __name__ == '__main__':
url_js = r'http://lol.qq.com/biz/hero/champion.js'
path = r'./data/' #图片存在的文件夹
dict_js = path_js(url_js)
url_list = path_url(dict_js)
list_filePath = name_pic(dict_js, path)
writing(url_list, list_filePath)![]()
运行后会在控制台打印出每一张图片的网址:
![]()
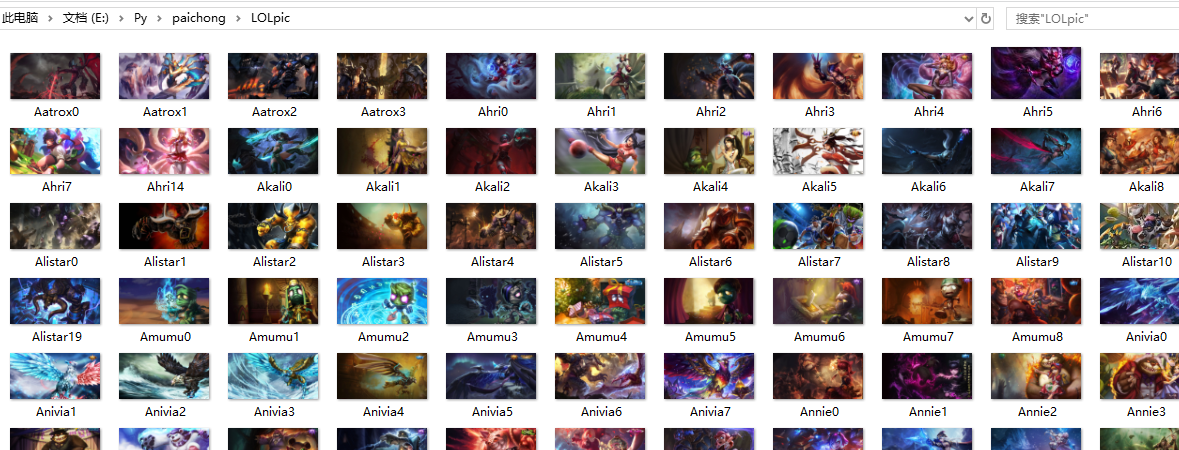
在文件夹中可以看到图片已经下载好:
![]()
以上就是我的分享,如果有什么不足之处请指出,多交流,谢谢!
如果喜欢,请关注我的博客:https://www.cnblogs.com/qiuwuzhidi/
想获取更多数据或定制爬虫的请点击python爬虫专业定制
python爬虫——《英雄联盟》英雄及皮肤图片的更多相关文章
- python爬虫王者荣耀高清皮肤大图背景故事通用爬虫
wzry-spider python通用爬虫-通用爬虫爬取静态网页,面向小白 基本上纯python语法切片索引,少用到第三方爬虫网络库 这是一只小巧方便,强大的爬虫,由python编写 主要实现了: ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python爬虫之足球小将动漫(图片)下载
尽管俄罗斯世界杯的热度已经褪去,但这届世界杯还是给全世界人民留下了无数难忘的回忆,不知你的回忆里有没有日本队的身影?本次世界杯中,日本队的表现让人眼前一亮,很难想象,就是这样一只队伍,二十几年还是 ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- Python爬虫(三)爬淘宝MM图片
直接上代码: # python2 # -*- coding: utf-8 -*- import urllib2 import re import string import os import shu ...
- 利用Python爬取OPGG上英雄联盟英雄胜率及选取率信息
一.分析网站内容 本次爬取网站为opgg,网址为:” http://www.op.gg/champion/statistics” 由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53 ...
- 【Python爬虫案例学习】下载某图片网站的所有图集
前言 其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 基本环境配置 python 版本:2.7 ...
- Python爬虫简单实现之Q乐园图片下载
根据需求写代码实现.然而跟我并没有什么关系,我只是打开电脑望着屏幕想着去干点什么,于是有了这个所谓的“需求”. 终于,我发现了Q乐园——到底是我老了还是我小了,这是什么神奇的网站,没听过啊,就是下面酱 ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- Python爬虫实战:批量下载网站图片
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: GitPython PS:如有需要Python学习资料的小伙伴可以 ...
随机推荐
- 文本相似性计算--MinHash和LSH算法
给定N个集合,从中找到相似的集合对,如何实现呢?直观的方法是比较任意两个集合.那么可以十分精确的找到每一对相似的集合,但是时间复杂度是O(n2).此外,假如,N个集合中只有少数几对集合相似,绝大多数集 ...
- Object类中的常用方法
1.getClass方法 源码: 功能: 返回此Object的运行时类. 什么是运行时类? 如上图所示,类从被加载到虚拟机内存开始,到卸载出内存为止,他的生命周期一共包含7个阶段.其中加载阶段虚拟机需 ...
- 【linux】命令-网络相关
目录 前言 1. ifconfig 1.1 语法 1.2 参数说明 1.3 例程 2. iw 2.1 扫描可用无线网络 2.2 WiFi连接步骤(教程A) 2.2.1 查看可以用无线设备信息 2.2. ...
- 全网最详细的新手入门Mysql命令和基础,小白必看!
MySQL简介 什么是数据库 ? 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,它产生于距今六十多年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不再仅仅是 ...
- 【2020.8.23NOIP模拟赛】失落
[ 2020.8.23 N O I P 模 拟 赛 ] 失 落 [2020.8.23NOIP模拟赛]失落 [2020.8.23NOIP模拟赛]失落 题目描述 出题人心情很失落,于是他直接告诉你让你求出 ...
- angular+ionic -- 启动命令
初始angular+ionic项目,启动需ionic的启动命令: ionic serve
- 02_利用numpy解决线性回归问题
02_利用numpy解决线性回归问题 目录 一.引言 二.线性回归简单介绍 2.1 线性回归三要素 2.2 损失函数 2.3 梯度下降 三.解决线性回归问题的五个步骤 四.利用Numpy实战解决线性回 ...
- starctf_2019_babyshell
starctf_2019_babyshell 有时shellcode受限,最好的方法一般就是勉强的凑出sys read系统调用来注入shellcode主体. 我们拿starctf_2019_babys ...
- C#入门到精通系列课程——第1章软件开发及C#简介
◆本章内容 (1)了解软件 (2)软件开发相关概念 (3)认识.NET Framework (4)C#语言 (5)Visual Studio 2017 ◆本章简述 软件在现代人们的日常生活中随处可见, ...
- 在 Windows 用上 Linux GUI——GitHub 热点速览 v.21.17
本文首发于「HelloGitHub」微信公众号,搜索「HelloGitHub」点击关注解锁更多宝藏! 作者:HelloGitHub-小鱼干 超喜欢本周的 GitHub 热点,如果你是个 Windows ...