python爬虫——《英雄联盟》英雄及皮肤图片
还记得那些年一起网吧开黑通宵的日子吗?《英雄联盟》绝对是大学时期的风靡游戏,即使毕业多年的大学同学相聚,难免不怀念一番当时一起玩《英雄联盟》的日子。
今天就给大家分享一下英雄及皮肤图片的爬虫。
一开始都是先去《英雄联盟》官网找到英雄及皮肤图片的网址:
URL = r'https://lol.qq.com/data/info-heros.shtml'![]()
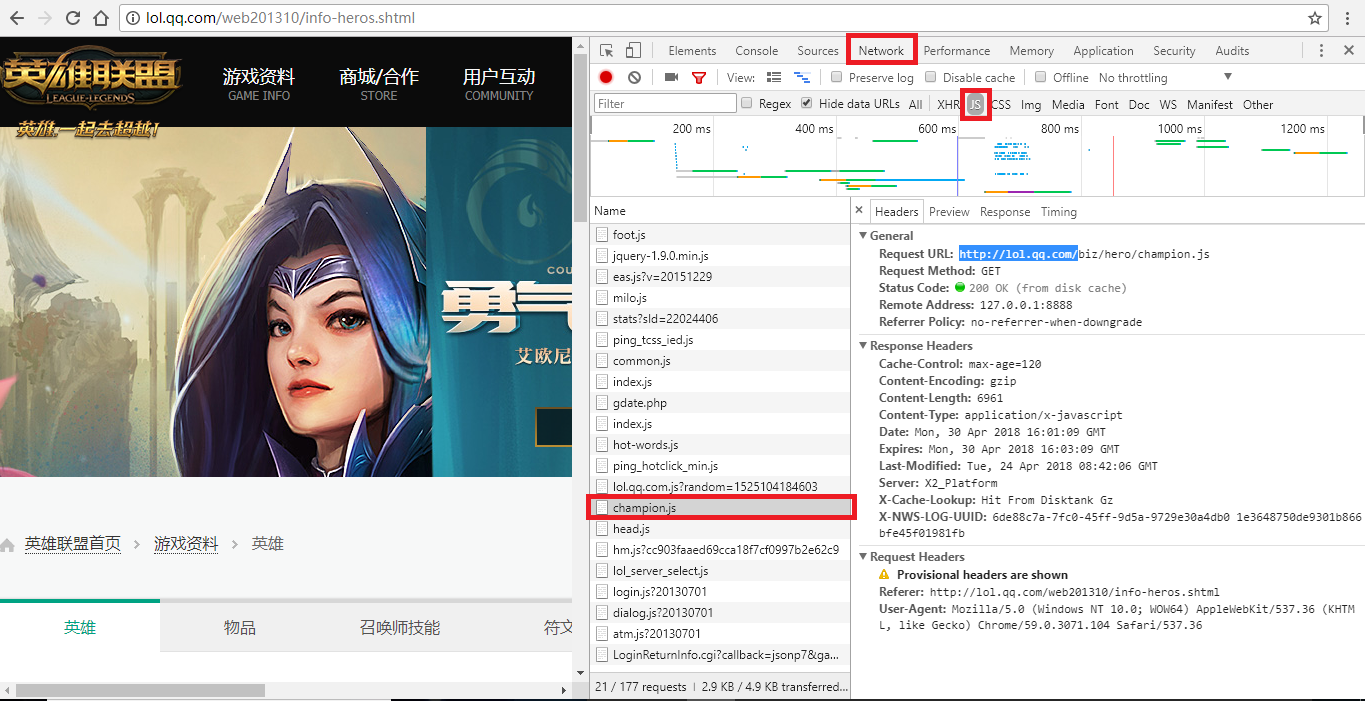
从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中。这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典——里面就包含了所有英雄的名字(英文)以及对应的编号(如下图)。
![]()
但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是回到网页,随便点开一个英雄,跳转页面后发现英雄及皮肤的图片都在,但要下载还需要找到原地址,这是鼠标右击选择“在新标签页中打开”,新的网页才是图片的原地址(如下图)。
![]()
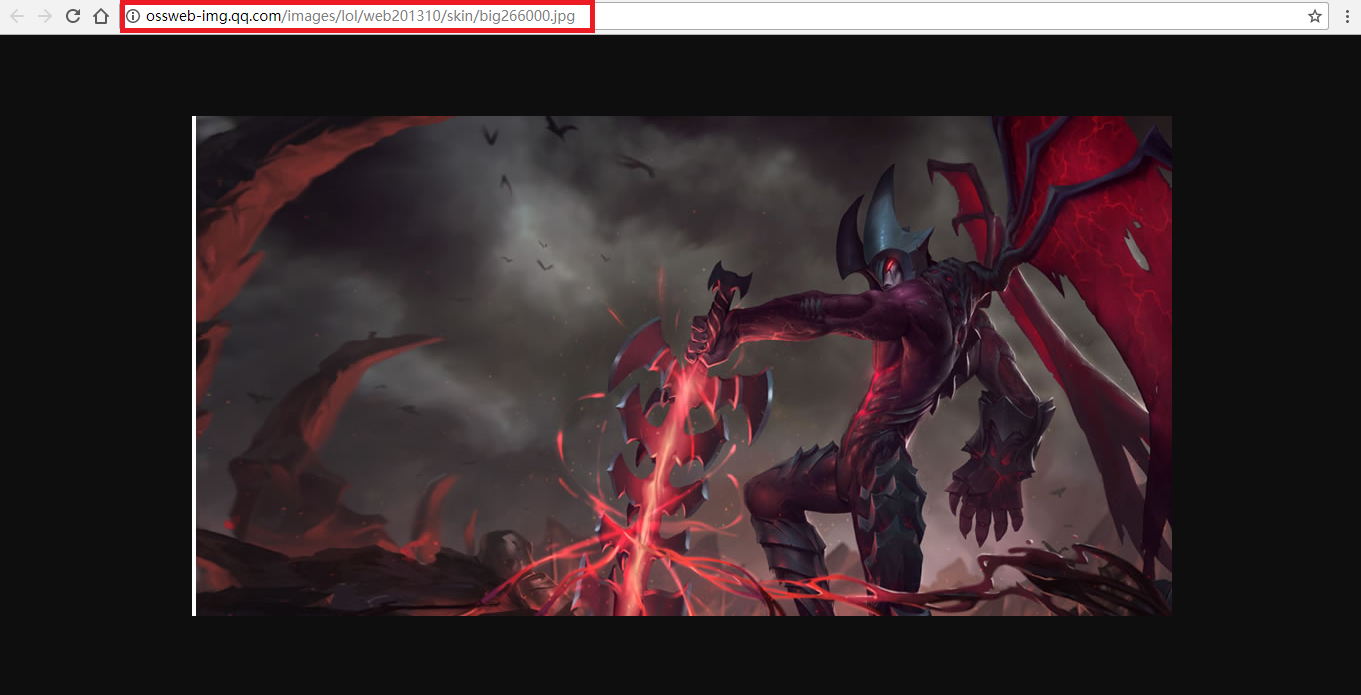
图中红色框就是我们需要的图片地址,经过分析知道:每一个英雄及皮肤的地址只有编号不一样(http://ossweb-img.qq.com/images/lol/web201310/skin/big266000.jpg),而该编号有6位,前3位表示英雄,后三位表示皮肤。刚才找到的js文件中恰好有英雄的编号,而皮肤的编码可以自己定义,反正每个英雄皮肤不超过20个,然后组合起来就可以了。
图片地址搞掂都就可以开始写程序了:
第一步:获取js字典
def path_js(url_js):
res_js = requests.get(url_js, verify = False).content
html_js = res_js.decode("gbk")
pat_js = r'"keys":(.*?),"data"'
enc = re.compile(pat_js)
list_js = enc.findall(html_js)
dict_js = eval(list_js[0])
return dict_js![]()
第二步:从 js字典中提取到key值生成url列表
def path_url(dict_js):
pic_list = []
for key in dict_js:
for i in range(20):
xuhao = str(i)
if len(xuhao) == 1:
num_houxu = "00" + xuhao
elif len(xuhao) == 2:
num_houxu = "0" + xuhao
numStr = key+num_houxu
url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big'+numStr+'.jpg'
pic_list.append(url)
print(pic_list)
return pic_list![]()
第三步:从 js字典中提取到value值生成name列表
def name_pic(dict_js, path):
list_filePath = []
for name in dict_js.values():
for i in range(20):
file_path = path + name + str(i) + '.jpg'
list_filePath.append(file_path)
return list_filePath![]()
第四步:下载并保存数据
def writing(url_list, list_filePath):
try:
for i in range(len(url_list)):
res = requests.get(url_list[i], verify = False).content
with open(list_filePath[i], "wb") as f:
f.write(res)
except Exception as e:
print("下载图片出错,%s" %(e))
return False![]()
执行主程序:
if __name__ == '__main__':
url_js = r'http://lol.qq.com/biz/hero/champion.js'
path = r'./data/' #图片存在的文件夹
dict_js = path_js(url_js)
url_list = path_url(dict_js)
list_filePath = name_pic(dict_js, path)
writing(url_list, list_filePath)![]()
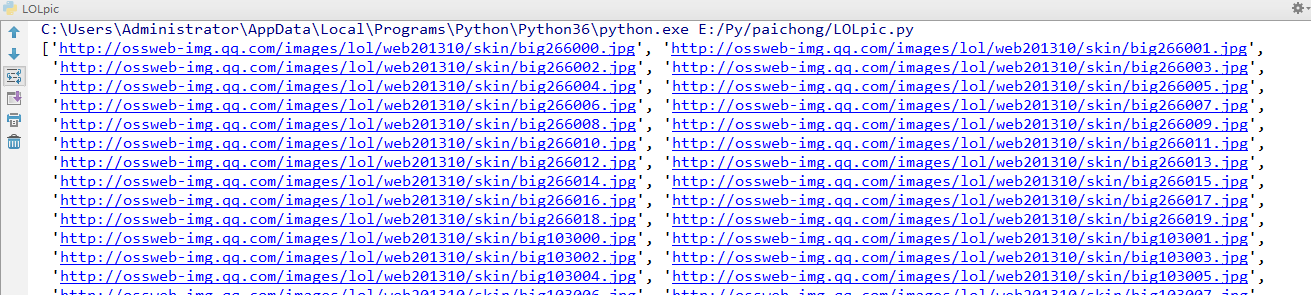
运行后会在控制台打印出每一张图片的网址:
![]()
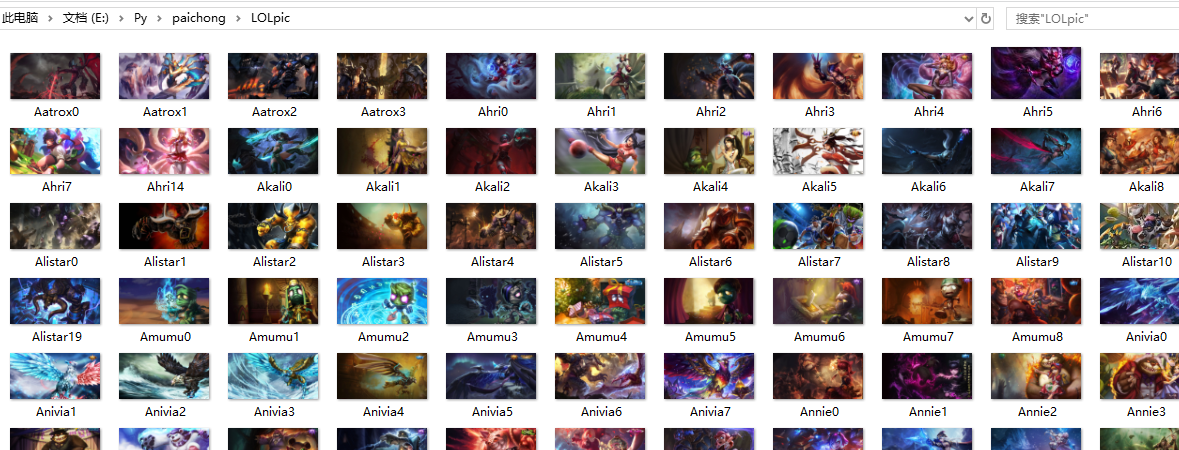
在文件夹中可以看到图片已经下载好:
![]()
以上就是我的分享,如果有什么不足之处请指出,多交流,谢谢!
如果喜欢,请关注我的博客:https://www.cnblogs.com/qiuwuzhidi/
想获取更多数据或定制爬虫的请点击python爬虫专业定制
python爬虫——《英雄联盟》英雄及皮肤图片的更多相关文章
- python爬虫王者荣耀高清皮肤大图背景故事通用爬虫
wzry-spider python通用爬虫-通用爬虫爬取静态网页,面向小白 基本上纯python语法切片索引,少用到第三方爬虫网络库 这是一只小巧方便,强大的爬虫,由python编写 主要实现了: ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python爬虫之足球小将动漫(图片)下载
尽管俄罗斯世界杯的热度已经褪去,但这届世界杯还是给全世界人民留下了无数难忘的回忆,不知你的回忆里有没有日本队的身影?本次世界杯中,日本队的表现让人眼前一亮,很难想象,就是这样一只队伍,二十几年还是 ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- Python爬虫(三)爬淘宝MM图片
直接上代码: # python2 # -*- coding: utf-8 -*- import urllib2 import re import string import os import shu ...
- 利用Python爬取OPGG上英雄联盟英雄胜率及选取率信息
一.分析网站内容 本次爬取网站为opgg,网址为:” http://www.op.gg/champion/statistics” 由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53 ...
- 【Python爬虫案例学习】下载某图片网站的所有图集
前言 其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 基本环境配置 python 版本:2.7 ...
- Python爬虫简单实现之Q乐园图片下载
根据需求写代码实现.然而跟我并没有什么关系,我只是打开电脑望着屏幕想着去干点什么,于是有了这个所谓的“需求”. 终于,我发现了Q乐园——到底是我老了还是我小了,这是什么神奇的网站,没听过啊,就是下面酱 ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- Python爬虫实战:批量下载网站图片
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: GitPython PS:如有需要Python学习资料的小伙伴可以 ...
随机推荐
- PTA 求链式表的表长
6-1 求链式表的表长 (10 分) 本题要求实现一个函数,求链式表的表长. 函数接口定义: int Length( List L ); 其中List结构定义如下: typedef struct ...
- 攻防世界 reverse 进阶5-7
5.re-for-50-plz-50 tu-ctf-2016 流程很简单,异或比较 1 x=list('cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ') 2 y=0x37 3 z= ...
- kthread_worker和kthread_work机制
1.概述 在阅读内核源码时,可以看到kthread_worker.kthread_work两个数据结构配合内核线程创建函数一起使用的场景.刚开始看到这块时,比较困惑,紧接着仔细分析源码后,终于弄清楚了 ...
- istio服务条目(ServiceEntry)介绍
使用服务条目资源(ServiceEntry)可以将条目添加到 Istio 内部维护的服务注册表中.添加服务条目后,Envoy 代理可以将流量发送到该服务,就好像该服务条目是网格中的服务一样.通过配置服 ...
- for what? while 与 until 差在哪?-- Shell十三问<第十三问>
for what? while 与 until 差在哪?-- Shell十三问<第十三问> 最后要介绍的是 shell script 设计中常见的"循环"(loop). ...
- CyclicBarrier:人齐了,老司机就可以发车了!
上一篇咱讲了 CountDownLatch 可以解决多个线程同步的问题,相比于 join 来说它的应用范围更广,不仅可以应用在线程上,还可以应用在线程池上.然而 CountDownLatch 却是一次 ...
- [Fundamental of Power Electronics]-PART I-6.变换器电路-6.3 变压器隔离
6.3 变压器隔离 在许多应用场合中,期望将变压器结合到开关变换器中,从而在变换器的输入输出之间形成直流隔离.例如,在离线(off-line)应用中(变换器输入连接到交流公用系统),根据监管部门要求, ...
- java面试-线程池使用过吗,谈谈对ThreadPoolExector的理解
一.架构说明: 二.为什么使用线程池,优势是什么? 线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,那么超出数量的线程排队 ...
- Recoil Input 光标位置被重置到末尾的问题
考察如下代码,页面中有个输入框,通过 Recoil Atom 来存储输入的值. App.tsx function NameInput() { const [name, setName] = useRe ...
- Java(246-264)【List、Set】
1.数据结构_栈 Stack先进后出 2.数据结构_队列 Queue先进先出 3.数据结构_数组 Array查询快.增删慢 需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根 据索引 ...