Conditional Generative Adversarial Nets
Mirza M, Osindero S. Conditional Generative Adversarial Nets.[J]. arXiv: Learning, 2014.
@article{mirza2014conditional,
title={Conditional Generative Adversarial Nets.},
author={Mirza, Mehdi and Osindero, Simon},
journal={arXiv: Learning},
year={2014}}
引
GAN (Generative Adversarial Nets) 能够通过隐变量\(z\)来生成一些数据, 但是我们没有办法去控制, 因为隐变量\(z\)是完全随机的. 这篇文章便很自然地提出了条件GAN,增加一个输入\(y\)(比如类别标签)去控制输出. 比如在MNIST数据集上, 我们随机采样一个\(z\), 并给定
\]
结果应当是数字2.
主要内容
文章的优化函数如下:
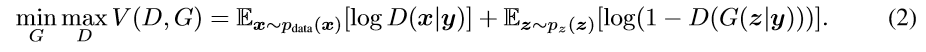
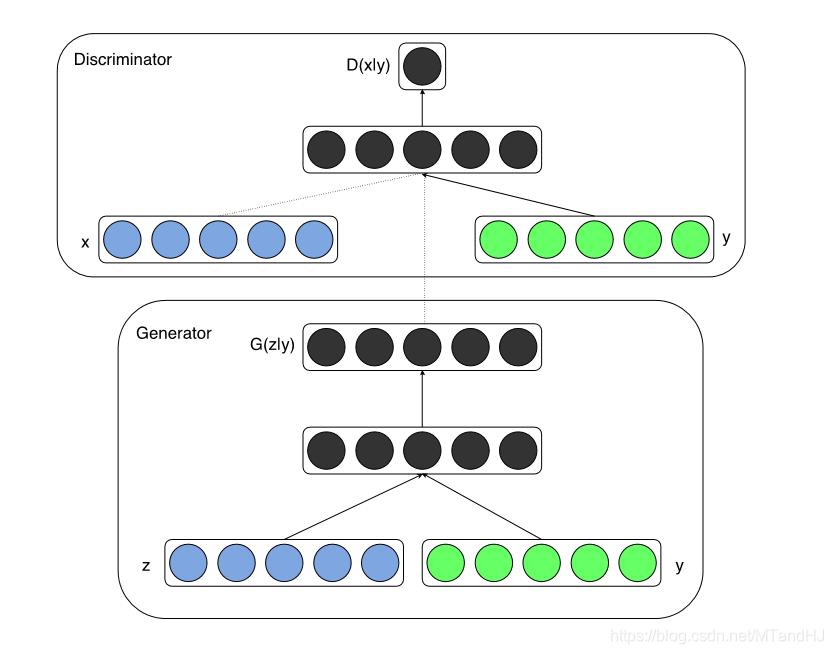
网络"结构"如下:


代码
"""
这个几乎就是照搬别人的代码
lr=0.0001,
epochs=50
但是10轮就差不多收敛了
"""
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import os
import matplotlib.pyplot as plt
class Generator(nn.Module):
"""
生成器
"""
def __init__(self, input_size=(100, 10), output_size=784):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 256),
nn.BatchNorm1d(256),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 256),
nn.BatchNorm1d(256),
nn.ReLU()
)
self.dense = nn.Sequential(
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, output_size),
nn.Tanh()
)
def forward(self, z, y):
"""
:param z: 随机隐变量
:param y: 条件隐变量
:return:
"""
z = self.fc1(z)
y = self.fc2(y)
out = self.dense(
torch.cat((z, y), 1)
)
return out
class Discriminator(nn.Module):
def __init__(self, input_size=(784, 10)):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 1024),
nn.LeakyReLU(0.2)
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 1024),
nn.LeakyReLU(0.2)
)
self.dense = nn.Sequential(
nn.Linear(2048, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x, y):
x = self.fc1(x)
y = self.fc2(y)
out = self.dense(
torch.cat((x, y), 1)
)
return out
class Train:
def __init__(self, z_size=100, y_size=10, x_size=784,
criterion=nn.BCELoss(), lr=1e-4):
self.generator = Generator(input_size=(z_size, y_size), output_size=x_size)
self.discriminator = Discriminator(input_size=(x_size, y_size))
self.criterion = criterion
self.opti1 = torch.optim.Adam(self.generator.parameters(), lr=lr, betas=(0.5, 0.999))
self.opti2 = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
self.z_size = z_size
self.y_size = y_size
self.x_size = x_size
self.lr = lr
cpath = os.path.abspath('.')
self.gen_path = os.path.join(cpath, 'generator3.pt')
self.dis_path = os.path.join(cpath, 'discriminator3.pt')
self.imgspath = lambda i: os.path.join(cpath, 'image3', 'fig{0}'.format(i))
#self.loading()
def transform_y(self, labels):
return torch.eye(self.y_size)[labels]
def sampling_z(self, size):
return torch.randn(size)
def showimgs(self, imgs, order):
n = imgs.size(0)
imgs = imgs.data.view(n, 28, 28)
fig, axs = plt.subplots(10, 10)
for i in range(10):
for j in range(10):
axs[i, j].get_xaxis().set_visible(False)
axs[i, j].get_yaxis().set_visible(False)
for i in range(10):
for j in range(10):
t = i * 10 + j
img = imgs[t]
axs[i, j].cla()
axs[i, j].imshow(img.data.view(28, 28).numpy(), cmap='gray')
fig.savefig(self.imgspath(order))
for i in range(10):
for j in range(10):
t = i * 10 + j
img = imgs[t]
axs[i, j].cla()
axs[i, j].imshow(img.data.view(28, 28).numpy() / 2 + 0.5, cmap='gray')
fig.savefig(self.imgspath(order+1))
#plt.show()
#plt.cla()
def train(self, trainloader, epochs=50, classes=10):
order = 2
for epoch in range(epochs):
running_loss_d = 0.
running_loss_g = 0.
if (epoch + 1) % 5 is 0.:
self.opti1.param_groups[0]['lr'] /= 10
self.opti2.param_groups[0]['lr'] /= 10
print("learning rate change!")
if (epoch + 1) % order is 0.:
self.showimgs(fake_imgs, order=order)
self.showimgs(real_imgs, order=order+2)
order += 4
for i, data in enumerate(trainloader):
real_imgs, labels = data
real_imgs = real_imgs.view(real_imgs.size(0), -1)
y = self.transform_y(labels)
d_out = self.discriminator(real_imgs, y).squeeze()
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs, fake_y).squeeze()
# 训练判别器
loss1 = self.criterion(d_out, torch.ones_like(d_out))
loss2 = self.criterion(g_out, torch.zeros_like(g_out))
d_loss = loss1 + loss2
self.opti2.zero_grad()
d_loss.backward()
self.opti2.step()
# 训练生成器
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs, fake_y).squeeze()
g_loss = self.criterion(g_out, torch.ones_like(g_out))
self.opti1.zero_grad()
g_loss.backward()
self.opti1.step()
running_loss_d += d_loss
running_loss_g += g_loss
if i % 10 is 0 and i != 0:
print("[epoch {0:<d}: d_loss: {1:<5f} g_loss: {2:<5f}]".format(
epoch, running_loss_d / 10, running_loss_g / 10
))
running_loss_d = 0.
running_loss_g = 0.
torch.save(self.generator.state_dict(), self.gen_path)
torch.save(self.discriminator.state_dict(), self.dis_path)
def loading(self):
self.generator.load_state_dict(torch.load(self.gen_path))
self.generator.eval()
self.discriminator.load_state_dict(torch.load(self.dis_path))
self.discriminator.eval()
结果

此时判别器对这些图片进行判别, 但部分都是0.5以下, 也就是说这些基本上都被认为是伪造的图片.
"""
lr=0.001,
SGD,
网络结构简化了
"""
class Generator(nn.Module):
"""
生成器
"""
def __init__(self, input_size=(100, 10), output_size=784):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 128),
nn.BatchNorm1d(128),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 128),
nn.BatchNorm1d(128),
nn.ReLU()
)
self.dense = nn.Sequential(
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, output_size),
nn.BatchNorm1d(output_size),
nn.Tanh()
)
def forward(self, z, y):
"""
:param z: 随机隐变量
:param y: 条件隐变量
:return:
"""
z = self.fc1(z)
y = self.fc2(y)
out = self.dense(
torch.cat((z, y), 1)
)
return out
class Discriminator(nn.Module):
def __init__(self, input_size=(784, 10)):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2)
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2)
)
self.dense = nn.Sequential(
nn.Linear(2048, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1),
nn.Sigmoid()
)
def forward(self, x, y):
x = self.fc1(x)
y = self.fc2(y)
out = self.dense(
torch.cat((x, y), 1)
)
return out
class Train:
def __init__(self, z_size=100, y_size=10, x_size=784,
criterion=nn.BCELoss(), lr=1e-3, momentum=0.9):
self.generator = Generator(input_size=(z_size, y_size), output_size=x_size)
self.discriminator = Discriminator(input_size=(x_size, y_size))
self.criterion = criterion
self.opti1 = torch.optim.SGD(self.generator.parameters(), lr=lr, momentum=momentum)
self.opti2 = torch.optim.SGD(self.discriminator.parameters(), lr=lr, momentum=momentum)
self.z_size = z_size
self.y_size = y_size
self.x_size = x_size
self.lr = lr
cpath = os.path.abspath('.')
self.gen_path = os.path.join(cpath, 'generator2.pt')
self.dis_path = os.path.join(cpath, 'discriminator2.pt')
self.imgspath = lambda i: os.path.join(cpath, 'image', 'fig{0}'.format(i))
#self.loading()
def transform_y(self, labels):
return torch.eye(self.y_size)[labels]
def sampling_z(self, size):
return torch.randn(size)
def showimgs(self, imgs, order):
n = imgs.size(0)
imgs = imgs.data.view(n, 28, 28)
fig, axs = plt.subplots(10, 10)
for i in range(10):
for j in range(10):
axs[i, j].get_xaxis().set_visible(False)
axs[i, j].get_yaxis().set_visible(False)
for i in range(10):
for j in range(10):
t = i * 10 + j
img = imgs[t]
axs[i, j].cla()
axs[i, j].imshow(img.data.view(28, 28).numpy(), cmap='gray')
fig.savefig(self.imgspath(order))
def train(self, trainloader, epochs=5, classes=10):
order = 0
for epoch in range(epochs):
running_loss_d = 0.
running_loss_g = 0.
if (epoch + 1) % 5 is 0.:
self.opti1.param_groups[0]['lr'] /= 10
self.opti2.param_groups[0]['lr'] /= 10
print("learning rate change!")
for i, data in enumerate(trainloader):
real_imgs, labels = data
real_imgs = real_imgs.view(real_imgs.size(0), -1)
y = self.transform_y(labels)
d_out = self.discriminator(real_imgs, y).squeeze()
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs.detach(), fake_y).squeeze()
# 训练判别器
loss1 = self.criterion(d_out, torch.ones_like(d_out))
loss2 = self.criterion(g_out, torch.zeros_like(g_out))
d_loss = loss1 + loss2
self.opti2.zero_grad()
d_loss.backward()
self.opti2.step()
# 训练生成器
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs, fake_y).squeeze()
g_loss = self.criterion(g_out, torch.ones_like(g_out))
self.opti1.zero_grad()
g_loss.backward()
self.opti1.step()
running_loss_d += d_loss
running_loss_g += g_loss
if i % 10 is 0 and i != 0:
print("[epoch {0:<d}: d_loss: {1:<5f} g_loss: {2:<5f}]".format(
epoch, running_loss_d / 10, running_loss_g / 10
))
running_loss_d = 0.
running_loss_g = 0.
if (epoch + 1) % 2 is 0:
self.showimgs(fake_imgs, order=order)
order += 1
torch.save(self.generator.state_dict(), self.gen_path)
torch.save(self.discriminator.state_dict(), self.dis_path)
def loading(self):
self.generator.load_state_dict(torch.load(self.gen_path))
self.generator.eval()
self.discriminator.load_state_dict(torch.load(self.dis_path))
self.discriminator.eval()
结果, 不是特别好

SGD改成Adam之后的结果(50个epochs都训练完了, 结果居然有点好).

Conditional Generative Adversarial Nets的更多相关文章
- 论文笔记之:Conditional Generative Adversarial Nets
Conditional Generative Adversarial Nets arXiv 2014 本文是 GANs 的拓展,在产生 和 判别时,考虑到额外的条件 y,以进行更加"激烈 ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- Generative Adversarial Nets[CAAE]
本文来自<Age Progression/Regression by Conditional Adversarial Autoencoder>,时间线为2017年2月. 该文很有意思,是如 ...
- Generative Adversarial Nets[pix2pix]
本文来自<Image-to-Image Translation with Conditional Adversarial Networks>,是Phillip Isola与朱俊彦等人的作品 ...
- GAN(Generative Adversarial Nets)的发展
GAN(Generative Adversarial Nets),产生式对抗网络 存在问题: 1.无法表示数据分布 2.速度慢 3.resolution太小,大了无语义信息 4.无reference ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- 论文笔记之:Generative Adversarial Nets
Generative Adversarial Nets NIPS 2014 摘要:本文通过对抗过程,提出了一种新的框架来预测产生式模型,我们同时训练两个模型:一个产生式模型 G,该模型可以抓住数据分 ...
- Generative Adversarial Nets[BEGAN]
本文来自<BEGAN: Boundary Equilibrium Generative Adversarial Networks>,时间线为2017年3月.是google的工作. 作者提出 ...
- Generative Adversarial Nets[CycleGAN]
本文来自<Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks>,时间线为2017 ...
随机推荐
- nuxt使用图片懒加载vue-lazyload
对于nuxt使用第三方插件的方式大体都是都是一致的,就是在plugins文件夹中新增插件对应的js文件进行配置与操作,然后在nuxt.config.js文件的plugins配置项中引入新建的js文件就 ...
- day05 django框架之路由层
day05 django框架之路由层 今日内容概要 简易版django请求声明周期流程图(重要) 路由匹配 无名有名分组 反向解析 无名有名解析 路由分发 名称空间 伪静态 虚拟环境 简易版djang ...
- SSH服务及通过SSH方式登录linux
SSH服务及通过SSH方式登录linux 1.检查SSH服务转自:[1]Linux之sshd服务https://www.cnblogs.com/uthnb/p/9367875.html[2]Linux ...
- java_IO总结(一)
所谓IO,也就是Input与Output的缩写.在java中,IO涉及的范围比较大,这里主要讨论针对文件内容的读写 其他知识点将放置后续章节(我想,文章太长了,谁都没耐心翻到最后) 对于文件内容的操作 ...
- 小程序中使用less(最优方式)
写惯了less/sass,但是现在开发小程序缺还是css,很不习惯. 在网上搜的教程,要么是gulp,要么就是vscode的Easy-less的插件. 传统方式 我们来对比,这两种方式的优劣. Gul ...
- 最小化安装centos ubuntu基础命令
# yum install vim iotop bc gcc gcc-c++ glibc glibc-devel pcre \ pcre-devel openssl openssl-devel zip ...
- awk统计命令(求和、求平均、求最大值、求最小值)
本节内容:awk统计命令 1.求和 cat data|awk '{sum+=$1} END {print "Sum = ", sum}' 2.求平均 cat data|awk '{ ...
- 2.7 Rust Structs
A struct, or structure, is a custom data type that lets you name and package together multiple relat ...
- spring中JDBCTemplate的简单应用
package cn.itcast.datasource.jdbctemplate;import cn.itcast.utils.JDBCUtils;import org.springframewor ...
- python初探——pandas使用
一.简介 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.pandas提供了大量 ...