HashMap并发分析
我们听过并发情况下的HashMap,会出现成环的情况,现在,我就来总结一下它成环的过程。
一言以蔽之,就是他在resize的时候,会改变元素的next指针。
之前在一篇博客里提到,HashMap的resize过程,首先capacity<<1,长度变为了原来的2倍;其次,原来的hash会&老的长度决定是移动到oldCap上还是原来位置。
假设,A线程在putVal一个元素,B线程同时也在putVal一个元素,并且他们都将引起resize(因为resize是put完成之后进行的);
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
e.next = newTable[i]; //标记[1]
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}
就是如上代码,它会将原来老数组中的链表遍历,并且串成新串,并放到新数组上。(生成的新链表是逆序的)
假设T1线程,已经获取到老数组开始遍历,此时让出了时间片,并且T2线程已经完成了相同位置的重新构造。
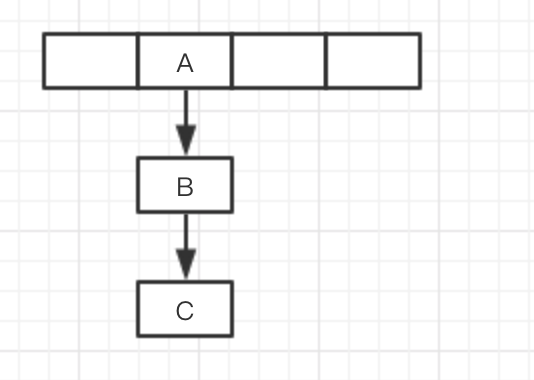
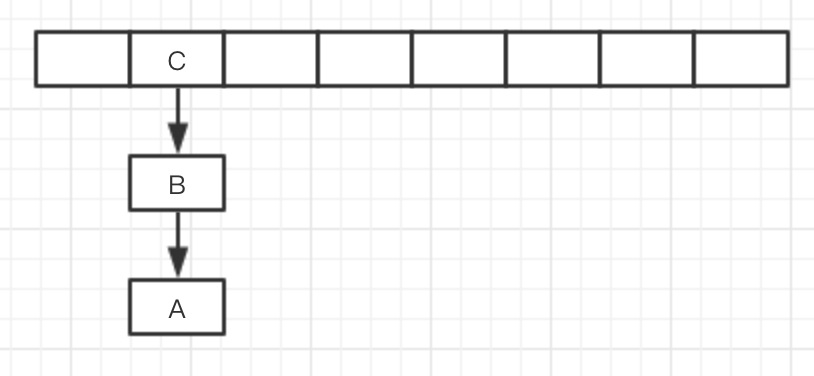
假设T1线程遍历到了T2,然后让出了时间片,T2线程完成了本条链表的resize,此时B的地址指向是A。
此时T1时间片申请到了,然后将实际内存中的B的next->A头插入T1的新链表中,T1就成环了。
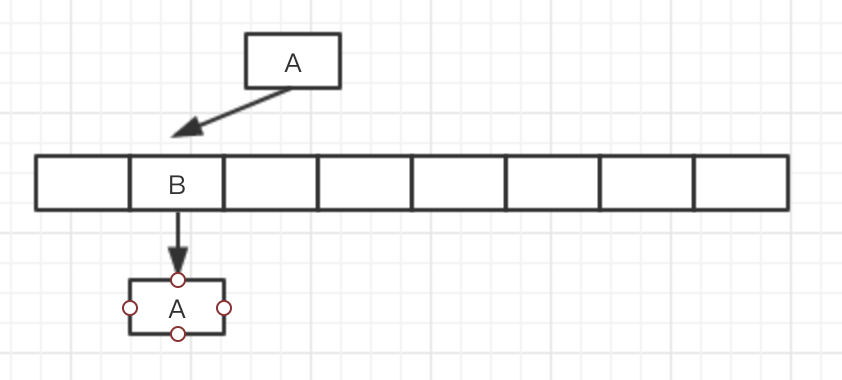
然后T2先替换table的地址,T1后替换,最后是成环的数组替换上去了。

如果,访问这个新数组的时候,访问到了这个位置,就会一直RUNNABLE,永远不会结束。
但是1.8的HashMap不会出现,因为它会丢数据。因为它在生成新链表的时候,会生成与原来一样顺序的子链表(高低位),最后再替换到新数组的位置上。
假设A(低)->B(高)->C(低)这个链表在拆的时候,理应变成(A->C),(B)这两个链表。如果T1线程遍历到A,T2线程完成了构建,实际上A的next已经是C了,T1线程就把B丢掉了,但是不会成环。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap并发分析的更多相关文章
- Java并发分析—ConcurrentHashMap
LZ在 https://www.cnblogs.com/xyzyj/p/6696545.html 中简单介绍了List和Map中的常用集合,唯独没有CurrentHashMap.原因是CurrentH ...
- HashMap底层分析
以下基于 JDK1.7 分析. 如图所示,HashMap 底层是基于数组和链表实现的.其中有两个重要的参数: 容量 负载因子 容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 si ...
- ConcurrentHashMap 并发HashMap原理分析
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁.如图 左边便是Hashtable的实现方式---锁整个hash表:而右边则是Concurrent ...
- HashMap并发导致死循环 CurrentHashMap
为何出现死循环简要说明 HashMap闭环的详细原因 cocurrentHashMap的底层机制 为何出现死循环简要说明 HashMap是非线程安全的,在并发场景中如果不保持足够的同步,就有可能在执行 ...
- 面试必问---HashMap原理分析
一.HashMap的原理 众所周知,HashMap是用来存储Key-Value键值对的一种集合,这个键值对也叫做Entry,而每个Entry都是存储在数组当中,因此这个数组就是HashMap的主干.H ...
- HashMap 底层分析
以下基于 JDK1.7 分析 如图所示,HashMap底层是基于数组和链表实现的,其中有两个重要的参数: ---容量 ---负载因子 容量的默认大小是16,负载因子是0.75,当HashMap的siz ...
- 聊聊经典数据结构HashMap,逐行分析每一个关键点
本文基于JDK-8u261源码分析 本文原创首发于 奇客时间(qiketime) 1 简介 HashMap是一个使用非常频繁的键值对形式的工具类,其使用起来十分方便.但是需要注意的是,HashMap不 ...
- 2021超详细的HashMap原理分析,面试官就喜欢问这个!
一.散列表结构 散列表结构就是数组+链表的结构 二.什么是哈希? Hash也称散列.哈希,对应的英文单词Hash,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出 这个映射的规则就是对 ...
- HashMap的分析(转)
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
随机推荐
- mysql双主架构
注意:最好不要用innodedb来同步数据库,要用databus来同步数据库,数据量大要用上mycat中间件 Mysql主主同步环境部署: centos 7.4 三台云主机: mysql1 :10.1 ...
- springboot子模块 @Autowired无法找到其他模块的接口和类的解决方法
在main的启动类上添加 @SpringBootApplication(scanBasePackages = {"com.shangsheng"})或者@ComponentScan ...
- 把CSV文件中的labels标签提取为json文件
需求: validationImages.csv文件是存储验证集数据名称和类别信息(labels)的文件, 要生成一个label和类别名一一对应且正序排列的json文件,代码如下: labels_di ...
- 【Linux开发】linux设备驱动归纳总结(七):2.内核定时器
linux设备驱动归纳总结(七):2.内核定时器 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx ...
- jmeter—获取当前时间(年、月、日),往前/往后n天
import java.util.Calendar; Calendar cal = Calendar.getInstance(); int day = cal.get(Calendar.DATE); ...
- Java内存模型(二)volatile底层实现(CPU的缓存一致性协议MESI)
CPU的缓存一致性协议MESI 在多核CPU中,内存中的数据会在多个核心中存在数据副本,某一个核心发生修改操作,就产生了数据不一致的问题,而一致性协议正是用于保证多个CPU cache之间缓存共享数据 ...
- Linux基础命令---间歇执行命令---watch
[watch] watch指令可以间歇性的执行程序,将输出结果以全屏的方式显示,默认是2s执行一次. watch指令下发后,将会一直被执行,直到被中断. [语法] watch \ [-d h v t] ...
- [Python3] 037 函数式编程 装饰器
目录 函数式编程 之 装饰器 Decrator 1. 引子 2. 简介 3. 使用 函数式编程 之 装饰器 Decrator 1. 引子 >>> def func(): ... pr ...
- JCC指令
0.JMP1.JE, JZ 结果为零则跳转(相等时跳转) ZF=12.JNE, JNZ 结果不为零则跳转(不相等时跳转) ZF=03.JS 结果为负则跳转 SF=14.JNS 结果为非负则 ...
- Keras模型训练的断点续训、早停、效果可视化
训练:model.fit()函数 fit(x=None, y=None, batch_size=None, epochs=, verbose=, callbacks=None, validation_ ...