他爬取了B站所有番剧信息,发现了这些……

本文来自「楼+ 之数据分析与挖掘实战 」第 4 期学员 —— Yueyec 的作业。他爬取了B站上所有的番剧信息,发现了很多有趣的数据~

关键信息:最高播放量 / 最强up主 / 用户追番数据 / 云追番?
起源
「数据分析」从「数据挖掘」开始,Yueyec 同学选择了 BeautifulSoup 来爬取B站的番剧信息。部分代码如下:


完整的代码可在文末查看。
数据清洗
数据分析前,我们要对数据进行清洗。
爬取数据后,发现有些视频的播放次数为-1,可能是由于版权、封号等问题下架的视频,大约有1000多个。
data[-1 == data['观看次数']]

清洗掉这些脏数据,清洗完成后,就可以分析拿到手的数据了。
data.drop(data[-1 == data['观看次数']].index, inplace=True)
最勤劳的up主
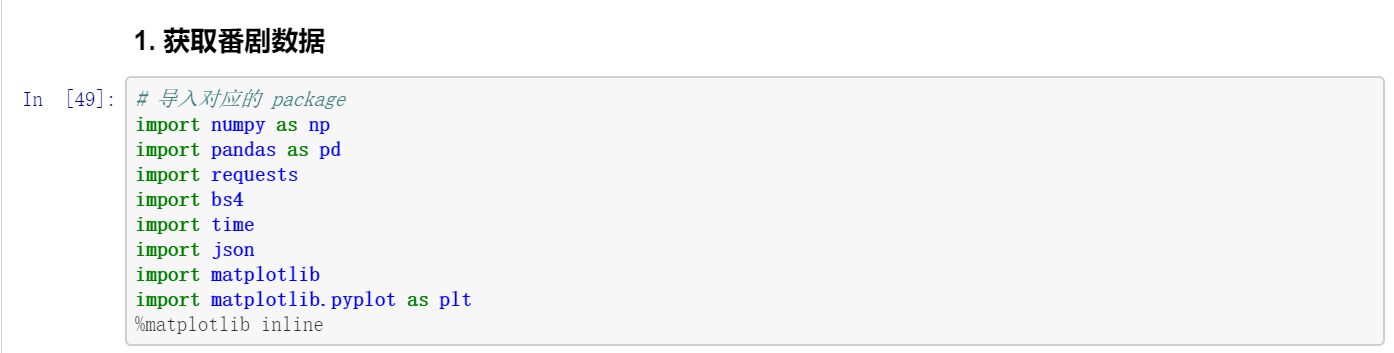
开始数据分析环节,我们先来看看谁是最勤劳的up主,他贡献了全站四分之一的番剧,猜猜他是谁?

统计发现:大致四分之一是 哔哩哔哩官方 发布的,排第二的则为「小清水亜美」,搬运了3218 集的番剧,第三位为 东京电视台。
完整的代码可在文末查看。
收藏量和播放量最高的番剧
收藏量和播放量最高的番剧都是哪部?结果可能会大大出于意料……
data.sort_values("收藏", ascending=False).reset_index(drop=True)
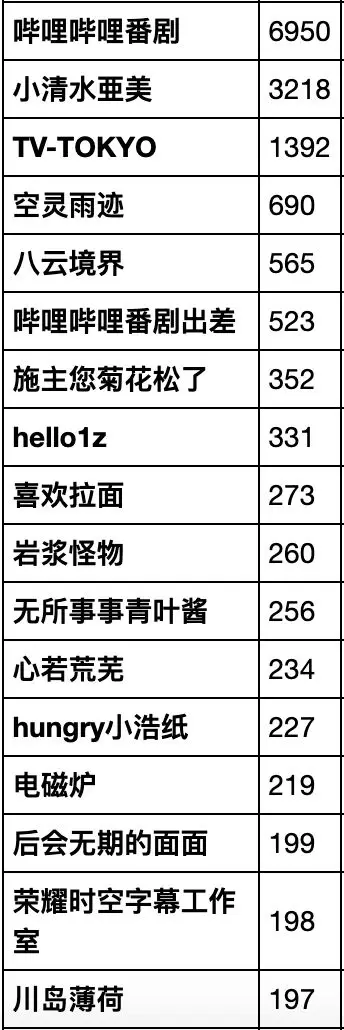
收藏数量排序
统计发现,收藏的番剧中,很多都是剧场版,可能是相对于TV版,剧场版制作更精良的缘故。在具体排序中,排第五的居然是本月10号上传的番剧,这点很意外。
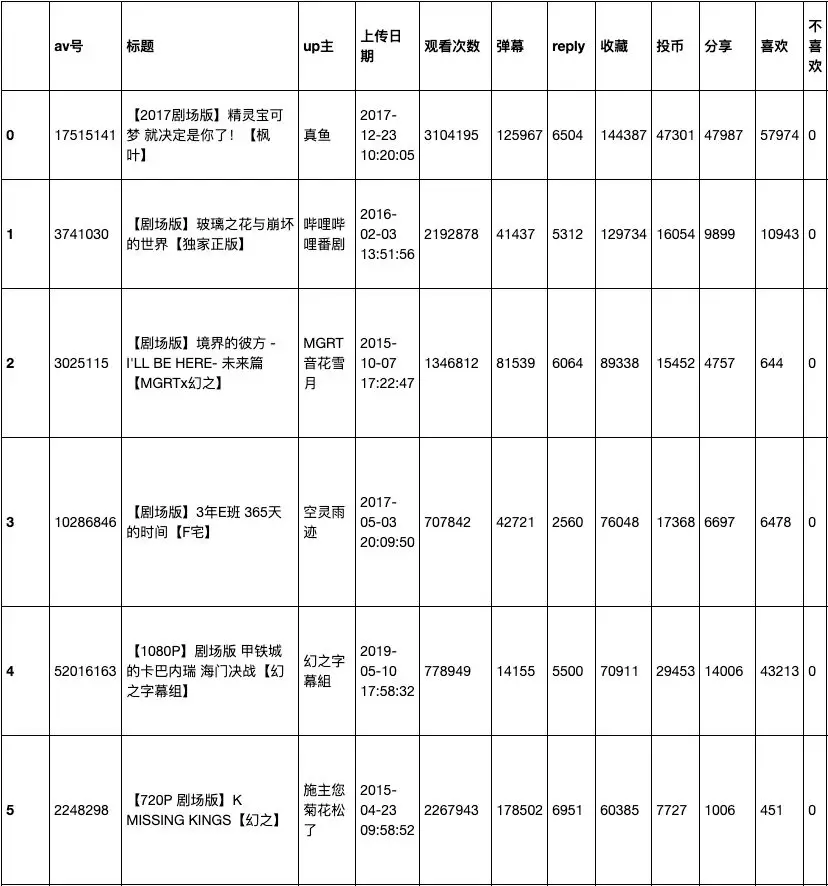
播放量最高的番剧又是哪个呢 :
data.sort_values("观看次数", ascending=False).reset_index(drop=True)
分析结果:
- 排名最高的「工作细胞」的播放量几乎达到了4000千万,远超第二部。

前五名中,「Overlord」出现了三次,果然是公认的B站霸权的番剧。
排名靠前的几部,都是番剧的第一集。
XX云番剧?
根据用户喜好,智能推荐音乐的应用我们都见过很多,但智能推荐番剧的好像挺少,能不能基于用户数据,做一个推荐番剧的系统呢?
Yueyec 同学进行了实验:
“另外爬取了用户的追番信息来做关联分析,可以查看到哪些番剧是关联比较大的。”
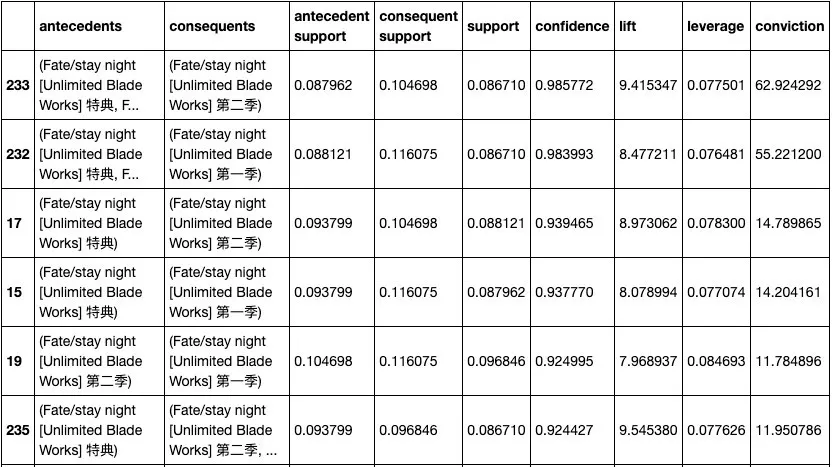
“可以看到,其中很多是同一个番剧,只是季数不同。但不少番剧之间也与很高的置信度,我觉得可以用此得到一个简单的推荐算法。”
中肯的总结和建议
通过这次6周的学习,补充了不少知识,加深了 Pandas 的使用,也了解了时间序列、自然语言等的处理方法。
虽然时间不长,但是对整个过程都有所了解,为将来学习机器学习建立了基石。
部分挑战太简单,建议把挑战换成从头到尾自己实现模型,更能加深印象和具有挑战难度。
第五周的内容展现了不同类型的分析模板,加强了见识也提供了很多扩展的内容。因为并没有完全看完,所以接下来会花部分时间来学习这部分。

除了 Yueyec 同学,还有很多优秀的同学的作品:

这些作品的代码,你可以在浏览器中输入这个链接,或点击阅读原文,再点击「查看更多优秀作品」来查阅。
https://github.com/shiyanlou/louplus-dm/tree/master/Assignments
如果你也想像这位同学一样,系统地学习数据挖掘和数据分析技能,可以了解一下《数据分析与挖掘实战》这门课程,目前已经开到第六期,一线大牛授课,带你在6周内成长为有真实工作能力的数据科学工程师。
现在扫码添加小姐姐微信,还可领取:100元优惠券 + 数据分析与挖掘学习脑图~

我在实验楼等你!
他爬取了B站所有番剧信息,发现了这些……的更多相关文章
- Ajax介绍及爬取哔哩哔哩番剧索引追番人数排行
Ajax,是利用JavaScript在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术.简单的说,Ajax使得网页无需刷新即可更新其内容.举个例子,我们用浏览器打开新浪微博 ...
- 爬虫入门六 总结 资料 与Scrapy实例-bibibili番剧信息
title: 爬虫入门六 总结 资料 与Scrapy实例-bibibili番剧信息 date: 2020-03-16 20:00:00 categories: python tags: crawler ...
- 使用requests+pyquery爬取dd373地下城跨五最新商品信息
废话不多说直接上代码: 可以使用openpyel库对爬取的信息写入Execl表格中代码我就不上传了 import requests from urllib.parse import urlencode ...
- 网络爬虫之scrapy爬取某招聘网手机APP发布信息
1 引言 过段时间要开始找新工作了,爬取一些岗位信息来分析一下吧.目前主流的招聘网站包括前程无忧.智联.BOSS直聘.拉勾等等.有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位 ...
- 利用Python爬虫爬取指定天猫店铺全店商品信息
本编博客是关于爬取天猫店铺中指定店铺的所有商品基础信息的爬虫,爬虫运行只需要输入相应店铺的域名名称即可,信息将以csv表格的形式保存,可以单店爬取也可以增加一个循环进行同时爬取. 源码展示 首先还是完 ...
- Python爬取前程无忧网站上python的招聘信息
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 我姓刘却留不住你的心 PS:如有需要Python学习资料的小伙伴可以 ...
- 爬取前程无忧网站上python的招聘信息。
本文获取的字段有为职位名称,公司名称,公司地点,薪资,发布时间 创建爬虫项目 scrapy startproject qianchengwuyou cd qianchengwuyou scrapy g ...
- Python爬取网址中多个页面的信息
通过上一篇博客了解到爬取数据的操作,但对于存在多个页面的网址来说,使用上一篇博客中的代码爬取下来的资料并不完整.接下来就是讲解该如何爬取之后的页面信息. 一.审查元素 鼠标移至页码处右键,选择检查元素 ...
- 爬取猎聘大数据岗位相关信息--Python
猎聘网站搜索大数据关键字,只能显示100页,爬取这一百页的相关信息,以便做分析. __author__ = 'Fred Zhao' import requests from bs4 import Be ...
随机推荐
- layui select渲染获取选中的option
关键代码如下: form.on('select(groupCode)', function(data){ console.log($(data.elem).find("option:sele ...
- Day1作业2:多层菜单查询
流程图: code: #!/usr/bin/env python # encoding: utf-8 # Auther:ccorz Mail:ccniubi@163.com Blog:http://w ...
- Sql server with as update用法
create table t1 ( id int,[names] varchar(100)) create table t2( id int,[names] varchar(100)) insert ...
- MyBatis-Spring项目
使用Spring IoC可以有效管理各类Java资源,达到即插即拔功能:通过AOP框架,数据库事务可以委托给Spring处理,消除很大一部分的事务代码,配合MyBatis的高灵活.可配置.可优化SQL ...
- IIS7(Windows7)下最简单最强安装多版本PHP支持环境
最近调试程序,要在PHP5.2和5.3之间换来换去,而习惯了windows下的开发,就琢磨怎么在iis下安装多版本支持,赫然发现其实微软都为我们准备了好工具. 微软对PHP的支持越来越强,这点在IIS ...
- 关于css清除元素浮动的方法总结(overflow clear floatfix)
在前两天的一个面试中考官问我web中清除浮动的一些css常用方法,我很轻松的答出了: 1.overflow:hidden 2.clear:both 3.floatfix类 然后问题就来了,考官接着问' ...
- Java基础教程:多线程基础(5)——倒计时器(CountDownLatch)
Java基础教程:多线程基础(5)——倒计时器(CountDownLatch) 引入倒计时器 在多线程协作完成业务功能时,有时候需要等待其他多个线程完成任务之后,主线程才能继续往下执行业务功能,在这种 ...
- AI - H2O - 第一个示例
1 - Iris数据集 Iris数据集是常用的机器学习分类实验数据集,特点是数据量很小,可以快速学习. 数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性. Sepal.Leng ...
- bootstrap-table:操作栏点击编辑按钮弹出模态框修改数据
核心代码: columns: [ { checkbox:true //第一列显示复选框 }, ... { field: 'fail_num', title: '失败数' }, { field: 'op ...
- AWS 数据库(七)
数据库概念 关系型数据库 关系数据库提供了一个通用接口,使用户可以使用使用 编写的命令或查询从数据库读取和写入数据. 关系数据库由一个或多个表格组成,表格由与电子表格相似的列和行组成. 以行列形式存储 ...