大规模数据爬取 -- Python
Python书写爬虫,目的是爬取所有的个人商家商品信息及详情,并进行数据归类分析
整个工作流程图:
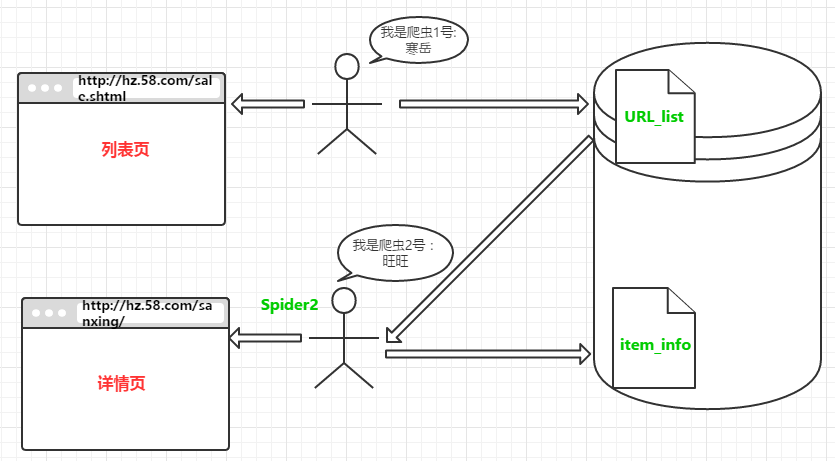
第一步:采用自动化的方式从前台页面获取所有的频道
from bs4 import BeautifulSoup
import requests #1、找到左侧边栏所有频道的链接
start_url = 'http://hz.58.com/sale.shtml'
url_host = 'http://hz.58.com' def get_channel_urls(url):
wb_data = requests.get(start_url)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('ul.ym-mainmnu > li > span > a["href"]')
for link in links:
page_url = url_host + link.get('href')
print(page_url)
#print(links) get_channel_urls(start_url) channel_list = '''
http://hz.58.com/shouji/
http://hz.58.com/tongxunyw/
http://hz.58.com/danche/
http://hz.58.com/diandongche/
http://hz.58.com/diannao/
http://hz.58.com/shuma/
http://hz.58.com/jiadian/
http://hz.58.com/ershoujiaju/
http://hz.58.com/yingyou/
http://hz.58.com/fushi/
http://hz.58.com/meirong/
http://hz.58.com/yishu/
http://hz.58.com/tushu/
http://hz.58.com/wenti/
http://hz.58.com/bangong/
http://hz.58.com/shebei.shtml
http://hz.58.com/chengren/
'''
第二步:通过第一步获取的所有频道去获取所有的列表详情,并存入URL_list表中,同时获取商品详情信息
from bs4 import BeautifulSoup
import requests
import time
import pymongo client = pymongo.MongoClient('localhost',27017)
ceshi = client['ceshi']
url_list = ceshi['url_list']
item_info = ceshi['item_info'] def get_links_from(channel,pages,who_sells=0):
#http://hz.58.com/shouji/0/pn7/
list_view = '{}{}/pn{}/'.format(channel,str(who_sells),str(pages))
wb_data = requests.get(list_view)
time.sleep(1)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('td.t > a[onclick]')
if soup.find('td','t'):
for link in links:
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url':item_link})
print(item_link)
else:
pass
# Nothing def get_item_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
no_longer_exist = '商品已下架' in soup
if no_longer_exist:
pass
else:
title = soup.title.text
price = soup.select('span.price_now > i')[0].text
area = soup.select('div.palce_li > span > i')[0].text
#url_list.insert_one({'title':title,'price':price,'area':area})
print({'title':title,'price':price,'area':area}) #get_links_from('http://hz.58.com/pbdn/',7)
#get_item_info('http://zhuanzhuan.58.com/detail/840577950118920199z.shtml')
第三步:采用多进程的方式的main主函数入口
from multiprocessing import Pool
from channel_extract import channel_list
from page_parsing import get_links_from def get_all_links_from(channel):
for num in range(1,31):
get_links_from(channel,num) if __name__ == '__main__':
pool = Pool()
pool.map(get_all_links_from,channel_list.split())
第四步:实时对获取到的数据进行监控
from time import sleep
from page_parsing import url_list while True:
print(url_list.find().count())
sleep(5)
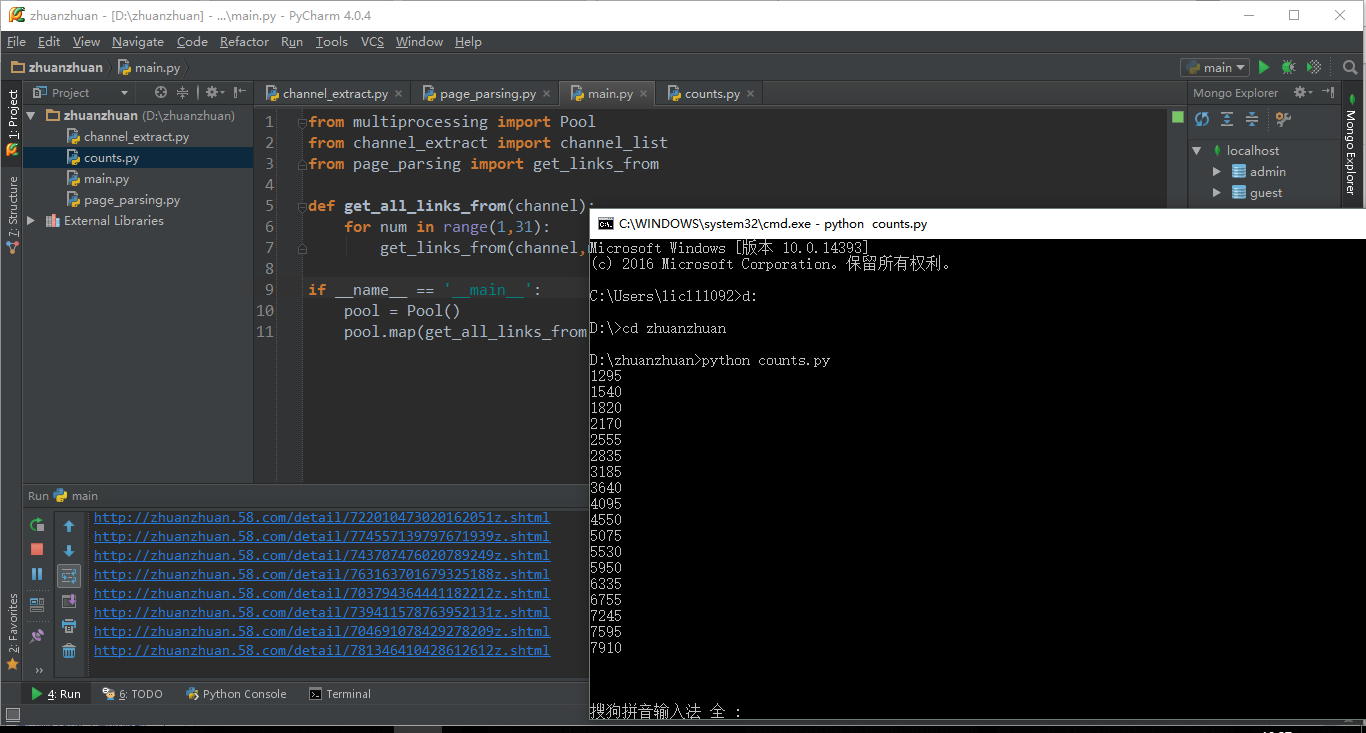
具体运行效果:
大规模数据爬取 -- Python的更多相关文章
- 模拟登陆+数据爬取 (python+selenuim)
以下代码是用来爬取LinkedIn网站一些学者的经历的,仅供参考,注意:不要一次性大量爬取会被封号,不要问我为什么知道 #-*- coding:utf-8 -*- from selenium impo ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- 人人贷网的数据爬取(利用python包selenium)
记得之前应同学之情,帮忙爬取人人贷网的借贷人信息,综合网上各种相关资料,改善一下别人代码,并能实现数据代码爬取,具体请看我之前的博客:http://www.cnblogs.com/Yiutto/p/5 ...
- 用Python介绍了企业资产情况的数据爬取、分析与展示。
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:张耀杰 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自 ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- python3编写网络爬虫13-Ajax数据爬取
一.Ajax数据爬取 1. 简介:Ajax 全称Asynchronous JavaScript and XML 异步的Javascript和XML. 它不是一门编程语言,而是利用JavaScript在 ...
随机推荐
- 纯原生javascript下拉框表单美化实例教程
html的表单有很强大的功能,在web早期的时候,表单是页面向服务器发起通信的主要渠道.但有些表单元素的样式没办法通过添加css样式来达到满意的效果,而且不同的浏览器之间设置的样式还存在兼容问题,比如 ...
- vxfs(Veritas File System)扩充目录大小
1.新增加一个磁盘并初始化 # vxdisk list # vxdisksetup -i 3pardata0_22 2.将新增加的磁盘合并到磁盘组中 # vxdg -g testdg01 adddis ...
- Goby资产扫描工具安装及报错处理
官网: https://cn.gobies.org/index.html 产品介绍: 帮企业梳理资产暴露攻击面,新一代网络安全技术,通过为目标建立完整的资产数据库,实现快速的安全应急. 已有功能: 扫 ...
- tf
第2章 Tensorflow keras实战 2-0 写在课程之前 课程代码的Tensorflow版本 大部分代码是tensorflow2.0的 课程以tf.kerasAPI为主,因而部分代码可以在t ...
- selenium八大元素定位方法
1.ID定位 可以根据元素的id来定位属性,id是当前整个HTML页面中唯一的,所以可以通过id属性来唯一定位一个元素,是首选的元素定位方式.(动态ID不做考虑) # 导入webdriver和By f ...
- Enabling Session Persistence 粘性会话
NGINX Docs | HTTP Load Balancing https://docs.nginx.com/nginx/admin-guide/load-balancer/http-load-ba ...
- Hash Array Mapped Trie
Hash Array Mapped Trie Python\hamt.c
- 基于Koa2框架的项目搭建及实战开发
Koa是基于 Node.js 平台的下一代 web 开发框架,由express原班人马打造,致力于成为一个更小.更富有表现力.更健壮的 Web 框架.使用 koa 编写 web 应用,通过组合不同的 ...
- Spark调优 | Spark Streaming 调优
Spark调优 | Spark Streaming 调优 1.数据序列化 2.广播大变量 3.数据处理和接收时的并行度 4.设置合理的批处理间隔 5.内存优化 5.1 内存管理 5.2优化策略 5.3 ...
- c++面试笔试集锦
1. char *const p 是指针常量,通俗的解释:指针本身是一个常量 也就是不能改变该指针的指向性,可以改变指向的量的值 const char *p 是常量指针,解释:指向常量的指针,指针指向 ...