wordcloud使用
学了下怎么用wordcloud。
以imet的数据集为例
https://www.kaggle.com/c/imet-2019-fgvc6
读取“train.csv”,”label.csv”文件,得到id2name[] (label的id和label名称对应) 和 attribute_count(label出现次数统计)两个dict。
import matplotlib.pyplot as plt
import numpy as np import osimport csv lines=csv.reader(open("train.csv"))
train_content = []
head_row =next(lines)
for line in lines:
train_content.append(line) attribute_ids = []
for line in train_content:
attributes = line[1].split()
for a in attributes:
attribute_ids.append(a) lines=csv.reader(open("labels.csv"))
attribute_content = []
head_row =next(lines)
for line in lines:
attribute_content.append(line)
id2name = {}
for line in attribute_content:
if line[0] not in id2name:
id2name.update({line[0]:line[1]})
def count_list(lt):
d={}
for i in lt:
if (i in d.keys()):
continue
count = lt.count(i)
d[i] = count
return d
attribute_count = count_list(attribute_ids)
对attribute_count进行排序,输出出现次数较多的标签(前十个)
sorted_attribute= sorted(attribute_count.items(),key = lambda item :item[1],reverse = True)
for i in range(10):
print (sorted_attribute[i][0],': ',id2name[sorted_attribute[i][0]])
print (sorted_attribute[i][1])
结果为

然而这样还不够直观,使用wordcloud可以更直观展示词频。
需要的python库
seaborn、wordcloud
准备好dict
culture_count_dict = {}
tag_count_dict = {}
for i in range(1103):
idx = str(i)
if (id2name[idx][0:5] == 'tag::'):
tag_count_dict.update({id2name[idx][5:]:attribute_count[idx]})
else:
culture_count_dict.update({id2name[idx][9:]:attribute_count[idx]})
wordcloud 生成图像
import seaborn as sns
from wordcloud import WordCloud culture_cloud = WordCloud(background_color='Black', colormap='Paired', width=1600, height=800, random_state=123).generate_from_frequencies(culture_count_dict)
tag_cloud = WordCloud(background_color='Black', colormap='Paired', width=1600, height=800, random_state=123).generate_from_frequencies(tag_count_dict) plt.figure(figsize=(24,24))
plt.subplot(211)
plt.imshow(culture_cloud,interpolation='bilinear')
plt.axis('off') plt.subplot(212)
plt.imshow(tag_cloud, interpolation='bilinear')
plt.axis('off') plt.tight_layout()
plt.show()

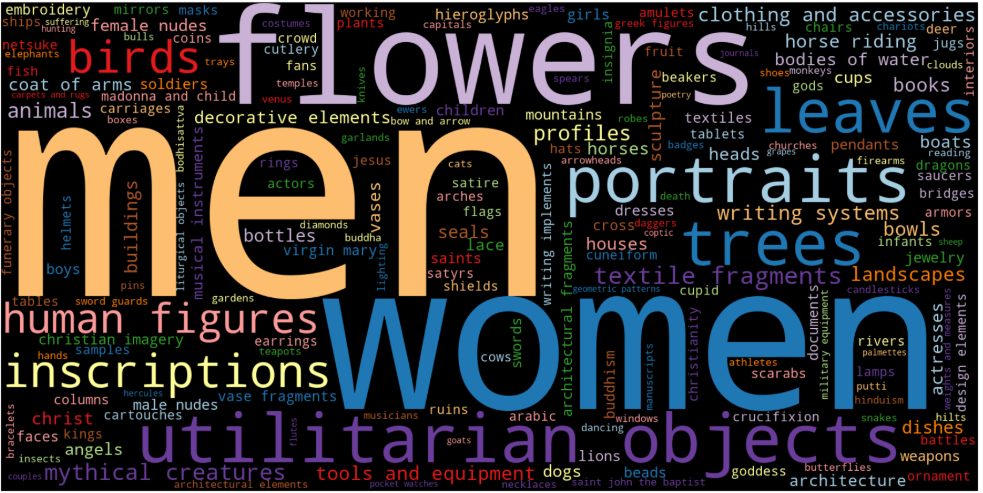
wordcloud使用的更多相关文章
- python wordcloud 对电影《我不是潘金莲》制作词云
上个星期五(16/11/18)去看了冯小刚的最新电影<我不是潘金莲>,电影很长,有点黑色幽默.看完之后我就去知乎,豆瓣电影等看看大家对于这部电影的评价.果然这是一部很有争议的电影,无论是在 ...
- R语言之词云:wordcloud&wordcloud2安装及参数说明
一.wordcloud安装说明 install.packages("wordcloud"); 二.wordcloud2安装说明 install.packages("dev ...
- python wordcloud
python wordcloud 对电影<我不是潘金莲>制作词云 上个星期五(16/11/18)去看了冯小刚的最新电影<我不是潘金莲>,电影很长,有点黑色幽默.看完之后我就去知 ...
- [R] Draw a wordcloud
# 加载rJava.Rwordseg库 library(rJava); library(Rwordseg); library(RColorBrewer); # == 读入数据 lecture=read ...
- Rweibo , wordcloud
利用Rweibo ,wordcloud做词云 #导入需要的包,不存在则下载 require(Rweibo) #必须先调用rJava不然Rwordseg 无法使用 library(rJava) requ ...
- 使用 wordcloud 构建词云图
from wordcloud import WordCloudfrom matplotlib import pyplot as pltfrom PIL import Imageimport numpy ...
- 爬取豆瓣电影影评,生成wordcloud词云,并利用监督学习根据评论自动打星
本文的完整源码在git位置:https://github.com/OceanBBBBbb/douban-ml 爬取豆瓣影评 爬豆瓣的影评比较简单,豆瓣没有做限制,甚至你都不用登陆就可以看全部,我这里用 ...
- 使用jieba库与wordcloud库第三方库进行词频统计
一.jieba库与wordcloud库的使用 1.jieba库与wordcloud库的介绍 jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最 ...
- win 10 的wordcloud的安装
这两天为了安装wordcloud库可谓是“一把辛酸”,各种出错 jieba什么就不说了,安装和使用都很简单只需要一句代码就可以实现了,而wordcloud在安装之前,本以为也像jieba那样的简单,但 ...
- 词云wordcloud入门示例
整体简介: 词云图,也叫文字云,是对文本中出现频率较高的“关键词”予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨. 基于Python的词云生成类库 ...
随机推荐
- Vue.js 2.0源码解析之前端渲染篇
一.前言 Vue.js框架是目前比较火的MVVM框架之一,简单易上手的学习曲线,友好的官方文档,配套的构建工具,让Vue.js在2016大放异彩,大有赶超React之势.前不久Vue.js 2.0正式 ...
- Android简单的利用SoundPool进行播放铃声的实例代码
MainActivity.java package com.example.pengdonglin.soundpool_demo; import android.annotation.Suppress ...
- IO流知识点
如何判断是输入还是输出?答:以程序为中心.如何判断是解码还是编码?答:以程序为中心.程序只懂二进制,所以,以二进制转换成字符是解码,字符转换成二进制是编码.1. 首先,File 它是给程序跟文件或文件 ...
- Camera图像处理原理及实例分析
Camera图像处理原理及实例分析 作者:刘旭晖 colorant@163.com 转载请注明出处 BLOG:http://blog.csdn.net/colorant/ 主页:http://rg ...
- Hibernate分页功能数据重复问题
今天遇到一个很憋屈的问题那就是hibernate分页查询中出现重复数据,本来一直没有在意,以为是数据问题,但是一查程序和数据都没有问题,继续深入查看,找到问题了就是order By 时出的问题,唉.. ...
- jqGrid怎么设置初始化页面时不加载数据(不向服务器请求数据)
最近做一些表格一直用到jqGrid,今天遇到一个问题: 1.就是页面加载的时候数据不显示,点击搜索才根据请求从服务器返回并显示内容. 2.默认不从服务器请求数据(不然在开发者工具下会显示请求不到数据的 ...
- 以lstm+ctc对汉字识别为例对tensorflow 中的lstm,ctc loss的调试
#-*-coding:utf8-*- __author = "buyizhiyou" __date = "2017-11-21" ''' 单步调试,结合汉字的识 ...
- 2017.9.15 postgres使用postgres_fdw实现跨库查询
postgres_fdw的使用参考来自:https://my.oschina.net/Kenyon/blog/214953 postgres跨库查询可以通过dblink或者postgres_fdw来完 ...
- hdu 1030 Delta-wave(数学题+找规律)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1030 Delta-wave Time Limit: 2000/1000 MS (Java/Others ...
- jquery给多个span赋值
因为我想在页面载入完毕后,有几个地方显示当前时间,所以我须要给多个span赋值. span代码的写法例如以下: <span name="currentDate">< ...