Python爬虫实例(五) requests+flask构建自己的电影库
目标任务:使用requests抓取电影网站信息和下载链接保存到数据库中,然后使用flask做数据展示。
爬取的网站在这里
最终效果如下:
主页:

可以进行搜索:输入水形物语
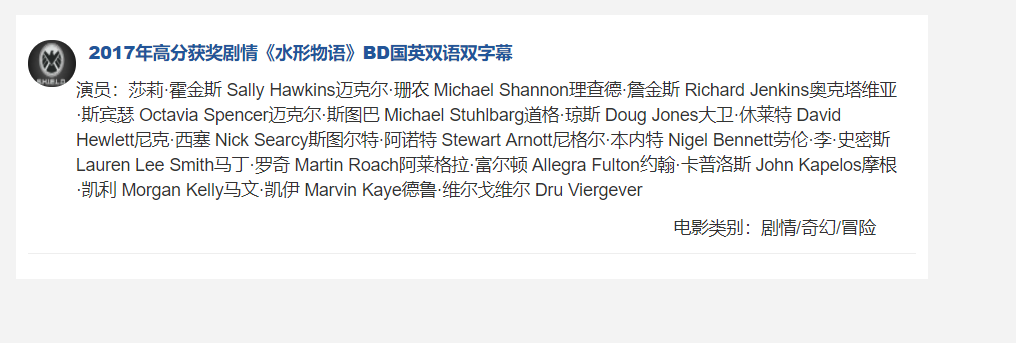
点击标题进入详情页:


爬虫程序
# -*- coding: utf-8 -*- import requests
from urllib import parse
import pymysql
from lxml import etree headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Referer': 'http://www.dytt8.net/'} BASE_URL = 'http://www.dytt8.net'
movie = {} def crawl_page_list(url):
"""
获取列表页标题和详情链接
""" resp = requests.get(url, headers=headers)
# replace,用?取代非法字符
html = resp.content.decode('gbk', 'replace')
tree = etree.HTML(html)
all_a = tree.xpath("//table[@class='tbspan']//a")
for a in all_a:
title = a.xpath("text()")[0]
href = a.xpath("@href")[0]
detail_url = parse.urljoin(BASE_URL, href)
crawl_detail(detail_url, title) def crawl_detail(url, title):
"""
下载并解析详情页
""" response = requests.get(url=url, headers=headers)
tree = etree.HTML(response.content.decode('gbk', 'replace'))
imgs = tree.xpath("//div[@id='Zoom']//img")
# 海报图
cover_img = imgs[0]
# 内容截图
screenshot_img = imgs[1]
cover_url = cover_img.xpath('@src')[0]
screenshot_url = screenshot_img.xpath('@src')[0]
download_url = tree.xpath('//div[@id="Zoom"]//td/a/@href')
# 迅雷下载链接
thunder_url = download_url[0]
# 磁力链接
magnet_url = download_url[1]
# 提取文本信息
infos = tree.xpath("//div[@id='Zoom']//text()")
for index,info in enumerate(infos):
if info.startswith("◎译 名"):
translate_name = info.replace("◎译 名", "").strip()
movie['translate_name'] = translate_name
if info.startswith("◎片 名"):
name = info.replace("◎片 名", "").strip()
movie['name'] = name
if info.startswith("◎年 代"):
year = info.replace("◎年 代", "").strip()
movie['year'] = year
if info.startswith("◎产 地"):
product_site = info.replace("◎产 地", "").strip()
movie['product_site'] = product_site
if info.startswith("◎类 别"):
classify = info.replace("◎类 别", "").strip()
movie['classify'] = classify
if info.startswith("◎主 演"):
temp = info.replace("◎主 演", "").strip()
actors = [temp]
for x in range(index+1, len(infos)):
value = infos[x].strip()
if value.startswith("◎"):
break
actors.append(value)
movie['actors'] = "".join(actors)
if info.startswith("◎简 介"):
contents = info.replace("◎简 介 ", "").strip()
content = [contents]
for x in range(index+1, len(infos)):
value = infos[x].strip()
if value.startswith("【下载地址】"):
break
content.append(value)
movie['content'] = str(content[1]) movie['title'] = title
movie['cover_url'] = cover_url
movie['screenshot_url'] = screenshot_url
movie['thunder_url'] = thunder_url
movie['magnet_url'] = magnet_url
save_data(movie) def save_data(data):
"""
存储到MySQL
""" name = movie['name']
translate_name = movie['translate_name']
year = movie['year']
product_site = movie['product_site']
classify = movie['classify']
actors = movie['actors']
content = movie['content']
title = movie['title']
cover_url = movie['cover_url']
screenshot_url = movie['screenshot_url']
thunder_url = movie['thunder_url']
magnet_url = movie['magnet_url'] connection = pymysql.connect(
host='ip',
user = 'MySQL用户名',
passwd='Mysql密码',
db = 'movie',
charset = 'utf8mb4',
) cursor1 = connection.cursor()
sql ='insert into dytt(name,translate_name,year, product_site,classify,actors, title,content,cover_url,screenshot_url,thunder_url,magnet_url) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cursor1.execute(sql,(name,translate_name,year, product_site,classify,actors, title,content,cover_url,screenshot_url,thunder_url,magnet_url))
connection.commit()
cursor1.close()
connection.close() def main():
base_url = "http://www.dytt8.net/html/gndy/dyzz/list_23_{}.html"
for i in range(1, 20):
base_url = base_url.format(str(i))
crawl_page_list(base_url) if __name__ == '__main__':
main()
Flask项目目录如下:
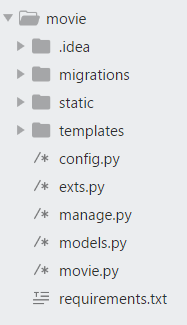
在项目目录下运行如下命令,完成数据库迁移:
python manage.py db init
python manage.py db migrate
python manage.py db upgrade
接着运行爬虫程序将数据写入MySQL,然后启动项目即可。
Python爬虫实例(五) requests+flask构建自己的电影库的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫进阶五之多线程的用法
前言 我们之前写的爬虫都是单个线程的?这怎么够?一旦一个地方卡到不动了,那不就永远等待下去了?为此我们可以使用多线程或者多进程来处理. 首先声明一点! 多线程和多进程是不一样的!一个是 thread ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 转 Python爬虫入门五之URLError异常处理
静觅 » Python爬虫入门五之URLError异常处理 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的服务器 服务器不存在 在代码中, ...
- Python爬虫学习1: Requests模块的使用
Requests函数库是学习Python爬虫必备之一, 能够帮助我们方便地爬取. Requests: 让HTTP服务人类. 本文主要参考了其官方文档. Requests具有完备的中英文文档, 能完全满 ...
- python爬虫实例大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
随机推荐
- hdu2147 kiki's game(博弈)
这个是纳什博弈?不知道怎么看的 依据PN图,从左下角開始推 左下角P 最后一行都是PNPNPN 第一列都是 P N P N P 完了填完即可了 #include<cstdio> int m ...
- CentOS下添加sudo用户
一 .sodo的使用 1.1 关于sudo Sudo是linux系统中,非root权限的用户提升自己权限来执行某些特性命令的方式,它使普通用户在不知道超级用户的密码的情况下,也可以暂时的获得root权 ...
- 【Java面试题】24 sleep() 和 wait() 有什么区别? 详细解析!!!!
第一种解释: 功能差不多,都用来进行线程控制,他们最大本质的区别是:sleep()不释放同步锁,wait()释放同步缩. 还有用法的上的不同是:sleep(milliseconds)可 ...
- Spring-Condition设置
为了满足不同条件下生成更为合适的bean,可以使用condition配置其条件.假如有一个bean,id为magicBean,只有当其具有magic属性时才生成,方法如下: javaConfig模式: ...
- jQuery-替换和删除元素
1.replaceWith方法 用提供的内容替换集合中所有匹配的元素并且返回被替换元素的集合 参数类型说明: 1)普通字符串(可包含各种html标签) 2)jQuery对象 ①使用$函数创建的新元素( ...
- win10系统下cmd输入一下安装的软件命令提示拒绝访问解决办法
问题:win10系统安装了nvm,cmd命令提示不是内部或外部命令 解决:卸载nvm,重新安装,再一次输入nvm,发现正常显示: 问题:win10安装了nvm之后,安装node成功,输入node命令, ...
- ChemDraw教程之怎么连接ChemDraw结构
将两个独立的ChemDraw结构连接到一起是使用者学习操作ChemDraw绘制窗口内容的基本能力之一.为了进一步了解ChemDraw软件,本教程将具体为您介绍怎么连接ChemDraw结构. 一.化学结 ...
- 什么是代码?code?
概念描述: 程序代码?code? 应用程序是由一系列代码构成,那么什么是代码呢? 简单来说:代码也可以理解为命令,通过这个命令告诉计算机该做什么事情. 文档创建时间:2018年3月16日15:10:5 ...
- Java web url 规范
设计URI应该遵循的原则 URI是网站UI的一部分,因此,可用的网站应该满足这些URL要求 简单,好记的域名 简短(short)的URI 容易录入的URI URI能反应站点的结构 URI是可以被用户猜 ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续二)
一.URL分析 通过对“Python机器学习”结果抓包分析,有两个无规律的参数:_ksTS和callback.通过构建如下URL可以获得目标关键词的检索结果,如下所示: https://s.taoba ...