Python 爬虫入门实例(爬取小米应用商店的top应用apk)
一,爬虫是什么?
爬虫就是获取网络上各种资源,数据的一种工具。具体的可以自行百度。
二,如何写简单爬虫
1,获取网页内容
可以通过 Python(3.x) 自带的 urllib,来实现网页内容的下载。实现起来很简单
import urllib.request url="http://www.baidu.com"
response=urllib.request.urlopen(url)
html_content=response.read()
还可以使用三方库 requests ,实现起来也非常方便,在使用之前当然你需要先安装这个库:pip install requests 即可(Python 3以后的pip非常好使)
import requests html_content=requests.get(url).text
2, 解析网页内容
获取的网页内容html_content,其实就是html代码,我们需要对其进行解析,获取我们所需要的内容。
解析网页的方法有很多,这里我介绍的是BeautifullSoup,由于这是一个三方库,在使用前 还是要先安装 :pip install bs4
form bs4 imort BeautifullSoup soup= BeautifullSoup(html_content, "html.parser")
更多使用方法请参考官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
三,实例分析
弄懂爬虫原理的最好办法,就是多分析一些实例,爬虫千变万化,万变不离其宗。废话少说上干货。
===================================我是分割线===================================================
需求:爬取小米应用商店的TOP n 应用
通过浏览器打开小米应用商店排行棒页面,F12审查元素
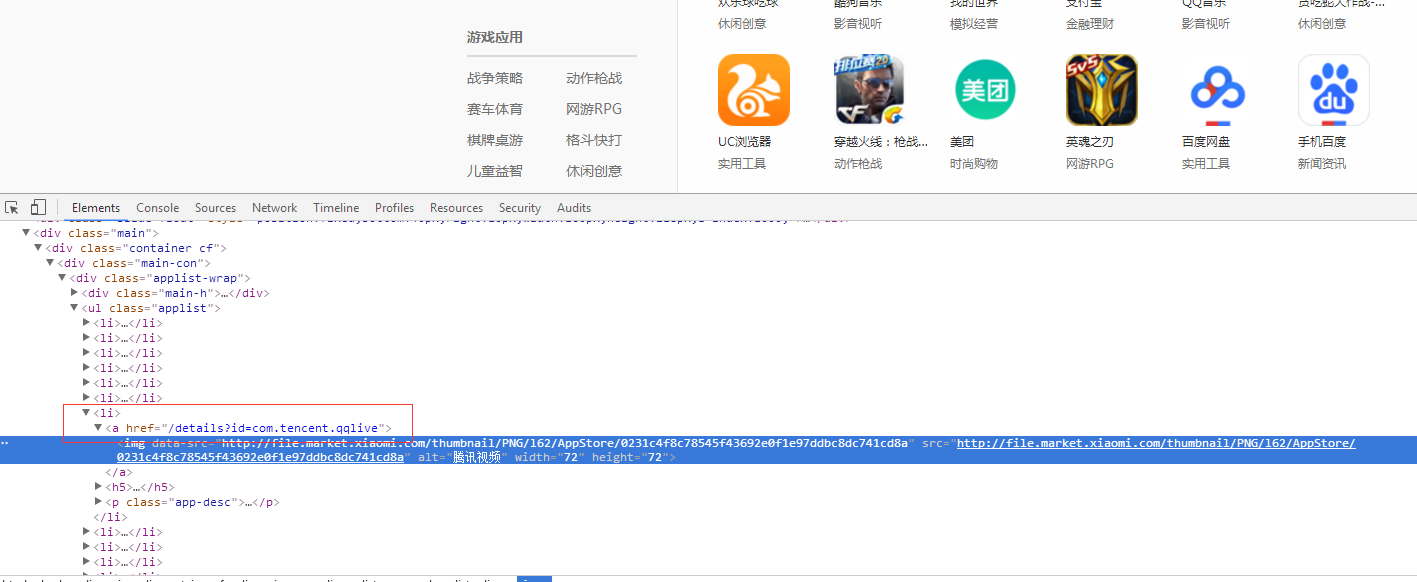
#coding=utf-8
import requests
import re
from bs4 import BeautifullSoup def parser_apks(self, count=0):
'''小米应用市场'''
_root_url="http://app.mi.com" #应用市场主页网址
res_parser={}
page_num=1 #设置爬取的页面,从第一页开始爬取,第一页爬完爬取第二页,以此类推
while count:
#获取排行榜页面的网页内容
wbdata = requests.get("http://app.mi.com/topList?page="+str(page_num)).text
print("开始爬取第"+str(page_num)+"页")
#解析页面内容获取 应用下载的 界面连接
soup=BeautifulSoup(wbdata,"html.parser")
links=soup.body.contents[3].find_all("a",href=re.compile("/details?"), class_ ="", alt="") #BeautifullSoup的具体用法请百度一下吧。。。
for link in links:
detail_link=urllib.parse.urljoin(_root_url, str(link["href"]))
package_name=detail_link.split("=")[1]
#在下载页面中获取 apk下载的地址
download_page=requests.get(detail_link).text
soup1=BeautifulSoup(download_page,"html.parser")
download_link=soup1.find(class_="download")["href"]
download_url=urllib.parse.urljoin(_root_url, str(download_link))
#解析后会有重复的结果,下面通过判断去重
if download_url not in res_parser.values():
res_parser[package_name]=download_url
count=count-1
if count==0:
break
if count >0:
page_num=page_num+1
print("爬取apk数量为: "+str(len(res_parser)))
return res_parser
def craw_apks(self, count=1, save_path="d:\\apk\\"):
res_dic=parser_apks(count) for apk in res_dic.keys():
print("正在下载应用: "+apk)
urllib.request.urlretrieve(res_dic[apk],save_path+apk+".apk")
print("下载完成")
if __name__=="__main__":
craw_apks(10)
运行结果:
开始爬取第1页
爬取apk数量为: 10
正在下载应用: com.tencent.tmgp.sgame
下载完成
.
.
.
以上就是简单爬虫的内容,其实爬虫的实现还是很复杂的,不同的网页有不同的解析方式,还需要深入学习。。。
Python 爬虫入门实例(爬取小米应用商店的top应用apk)的更多相关文章
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门(一)——爬取糗百
爬取糗百内容 GitHub 代码地址https://github.com/injetlee/Python/blob/master/qiubai_crawer.py 微信公众号:[智能制造专栏],欢迎关 ...
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
- python 爬虫入门案例----爬取某站上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSou ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- python爬虫+正则表达式实例爬取豆瓣Top250的图片
直接上全部代码 新手上路代码风格可能不太好 import requests import re from fake_useragent import UserAgent #### 用来伪造爬头部信息 ...
- Python爬虫入门:爬取pixiv
终于想开始爬自己想爬的网站了.于是就试着爬P站试试手. 我爬的图的目标网址是: http://www.pixiv.net/search.php?word=%E5%9B%9B%E6%9C%88%E3%8 ...
- python 爬虫入门1 爬取代理服务器网址
刚学,只会一点正则,还只能爬1页..以后还会加入测试 #coding:utf-8 import urllib import urllib2 import re #抓取代理服务器地址 Key = 1 u ...
随机推荐
- 蓝桥杯历届试题-垒色子(DP+矩阵快速幂)
一.题目 垒骰子 赌圣atm晚年迷恋上了垒骰子,就是把骰子一个垒在另一个上边,不能歪歪扭扭,要垒成方柱体.经过长期观察,atm 发现了稳定骰子的奥秘:有些数字的面贴着会互相排斥!我们先来规范一下骰子: ...
- oracle忘记sys及system密码
一.忘记除SYS.SYSTEM用户之外的用户的登录密码. 用SYS (或SYSTEM)用户登录. CONN SYS/PASS_WORD AS SYSDBA; 使用如下语句修改用户的密码. ALTER ...
- -bash: /usr/bin/yum: /usr/bin/python: bad interpreter: No such file or directory
-bash: /usr/bin/yum: /usr/bin/python: bad interpreter: No such file or directory python多版本造成额问题 找不到p ...
- 利用 Babel 玩转你的代码
我在团队帮助开发 Node 工具时,遇到了需要对多份相似的代码进行一定的处理,但又不能改变原本仓库的代码,这个非常像我们的编译工具做的事情.在一开始的时候,参考了类似 FIS 的功能,简单参照使用代码 ...
- Excel数据转化为sql脚本
在实际项目开发中,有时会遇到客户让我们把大量Excel数据导入数据库的情况.这时我们就可以通过将Excel数据转化为sql脚本来批量导入数据库. 1 在数据前插入一列单元格,用来拼写sql语句. 具体 ...
- Unknown type name 'NSString'
今天看到个问题,编辑工程提示Unknown type name 'NSString',如下图 导致出现异常的原因是是因为工程中添加了ZipArchive(第三方开源解压缩库) 一般情况下出现“Unkn ...
- animate.css动画种类
animate.css 一个非常好用的css动画库 Github地址 包括了一下多种动画 1. bounce 弹跳 2. flash 闪烁 3. pulse 放大,缩小 4. rubberBand 放 ...
- 解决clion2016.3不能支持搜狗输入法的问题
参考链接http://www.cnblogs.com/chentq/p/4975794.html 打开clion.sh在文件头部添加 export GTK_IM_MODULE=fcitx export ...
- C和C++中的不定参数
在初学C的时候,我们都会用到printf函数来写Hello World的程序.在我们看printf函数的声明时,会看到类似于下面代码 int printf(const char * __restric ...
- 查看binlog的简单方法!
今天学到一个牛逼的东西,不用打开binlog文件就可以查看binlog里的event事件. 命令为:show binlog events in 'mysql-bin.000001' from 4 li ...