Hadoop(20)-MapReduce框架原理-OutputFormat
1.outputFormat接口实现类

2.自定义outputFormat
步骤:
1). 定义一个类继承FileOutputFormat
2). 定义一个类继承RecordWrite,重写write方法
3. 案例
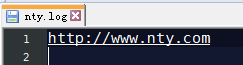
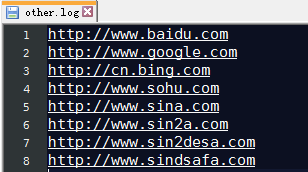
有一个log文件,将包含nty的输出到nty.log文件,其他的输出到other.log
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.nty.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
自定义类继承FileOutputFormat
package com.nty.outputFormat; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* author nty
* date time 2018-12-12 19:28
*/
public class FilterOutputFormat extends FileOutputFormat<LongWritable, Text> { @Override
public RecordWriter<LongWritable, Text> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
FilterRecordWrite frw = new FilterRecordWrite();
frw.init(job);
return frw;
}
}
自定义RecordWriter,重写write
package com.nty.outputFormat; import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* author nty
* date time 2018-12-12 19:29
*/
public class FilterRecordWrite extends RecordWriter<LongWritable, Text> { private FSDataOutputStream nty; private FSDataOutputStream other; //将job通过参数传递过来
public void init(TaskAttemptContext job) throws IOException { String outDir = job.getConfiguration().get(FileOutputFormat.OUTDIR); FileSystem fileSystem = FileSystem.get(job.getConfiguration()); nty = fileSystem.create(new Path(outDir + "/nty.log"));
other = fileSystem.create(new Path(outDir + "/other.log")); } @Override
public void write(LongWritable key, Text value) throws IOException, InterruptedException {
String address = value.toString() + "\r\n"; if(address.contains("nty")) {
nty.write(address.getBytes());
} else {
other.write(address.getBytes());
} } @Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
//关流
IOUtils.closeStream(nty);
IOUtils.closeStream(other);
}
}
Driver类设置
package com.nty.outputFormat; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* author nty
* date time 2018-12-12 19:29
*/
public class FilterDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration); job.setJarByClass(FilterDriver.class); job.setOutputFormatClass(FilterOutputFormat.class); FileInputFormat.setInputPaths(job, new Path("d:\\Hadoop_test"));
FileOutputFormat.setOutputPath(job, new Path("d:\\Hadoop_test_out")); boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
输出结果

Hadoop(20)-MapReduce框架原理-OutputFormat的更多相关文章
- [Hadoop] - 自定义Mapreduce InputFormat&OutputFormat
在MR程序的开发过程中,经常会遇到输入数据不是HDFS或者数据输出目的地不是HDFS的,MapReduce的设计已经考虑到这种情况,它为我们提供了两个组建,只需要我们自定义适合的InputFormat ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析
1.MapReduce的数据流 1) Input -> Mapper阶段 这一阶段的主要分工就是将文件切片和把文件转成K,V对 输入源是一个文件,经过InputFormat之后,到了Mapper ...
- MapReduce框架原理-OutputFormat工作原理
OutputFormat概述 OutputFormat主要是用来指定MR程序的最终的输出数据格式 . 默认使用的是TextOutputFormat,默认是将数据一行写一条数据,并且把数据放到指定的输出 ...
- Hadoop(19)-MapReduce框架原理-Combiner合并
1. Combiner概述 2. 自定义Combiner实现步骤 1). 定义一个Combiner继承Reducer,重写reduce方法 public class WordcountCombiner ...
- Hadoop(15)-MapReduce框架原理-FileInputFormat的实现类
1. TextInputFormat 2.KeyValueTextInputFormat 3. NLineInputFormat
随机推荐
- 安装adobe,路径My Pictures或卷无效。请重新输入。
问题:安装adobe reader时,路径My Pictures或卷无效.请重新输入.我的光驱是D盘.因为是在虚拟机下安装的xp系统. 解决办法: GHOST WINXP2 My Pictures一般 ...
- 使用 yield生成迭代对象函数
https://www.cnblogs.com/python-life/articles/4549996.html https://www.liaoxuefeng.com/wiki/001431608 ...
- Angular项目新建
Angular新建项目步骤记录 标签(空格分隔): Angular 1. ng new my-app 2. 启动dev环境 cd my-app ng serve --open 3. 修改styles. ...
- 元素float以后,div高度无法自适应解决方案
首先要明白 >> 浮动的子元素会脱离文档流,不再占据父元素的空间,父元素也就没有了高度. 解决方案:1 给父元素加上overflow:hidden;属性就行了. 第一种:(给父级加over ...
- May 18th 2017 Week 20th Thursday
The greater the struggle, the more glorious the triumph. 挑战愈艰巨,胜利愈辉煌. Sometimes it would be better t ...
- OAuth 2.0协议在SAP产品中的应用
阮一峰老师曾经在他的博文理解OAuth 2.0里对这个概念有了深入浅出的阐述. http://www.ruanyifeng.com/blog/2014/05/oauth_2_0.html 本文会结合我 ...
- python:递归函数
1,初识递归函数 1)什么是递归函数? 在函数中自己调用自己叫做递归函数 递归函数超过一定程度会报错.---RecursionError: maximum recursion dep th excee ...
- [APIO/CTSC 2007]数据备份
嘟嘟嘟 这竟然是一道贪心题,然而我在不看题解之前一直以为是dp. 首先最优的配对一定是相邻两个建筑物配对,所以我们求出差分数组,就变成了在n - 1个数中选出不相邻的k个数,使这k个数的和最小. 贪心 ...
- (第六场)Singing Contest 【模拟】
题目链接:https://www.nowcoder.com/acm/contest/144/A 标题:A.Singing Contest | 时间限制:1 秒 | 内存限制:256M Jigglypu ...
- 【luogu P1726 上白泽慧音】 题解
题目链接:https://www.luogu.org/problemnew/show/P1726 菜 #include <stack> #include <cstdio> #i ...