sklearn.preprocessing.StandardScaler数据标准化
原文链接:https://blog.csdn.net/weixin_39175124/article/details/79463993
数据在前处理的时候,经常会涉及到数据标准化。将现有的数据通过某种关系,映射到某一空间内。常用的标准化方式是,减去平均值,然后通过标准差映射到均至为0的空间内。系统会记录每个输入参数的平均数和标准差,以便数据可以还原。
很多ML的算法要求训练的输入参数的平均值是0并且有相同阶数的方差例如:RBF核的SVM,L1和L2正则的线性回归
sklearn.preprocessing.StandardScaler能够轻松的实现上述功能。
调用方式为:
首先定义一个对象:
ss = sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
在这里
copy; with_mean;with_std
默认的值都是True.
copy 如果为false,就会用归一化的值替代原来的值;如果被标准化的数据不是np.array或scipy.sparse CSR matrix, 原来的数据还是被copy而不是被替代
with_mean 在处理sparse CSR或者 CSC matrices 一定要设置False不然会超内存
能够查询的属性:
scale_: 缩放比例,同时也是标准差
mean_: 每个特征的平均值
var_:每个特征的方差
n_sample_seen_:样本数量,可以通过patial_fit 增加
举个例子:
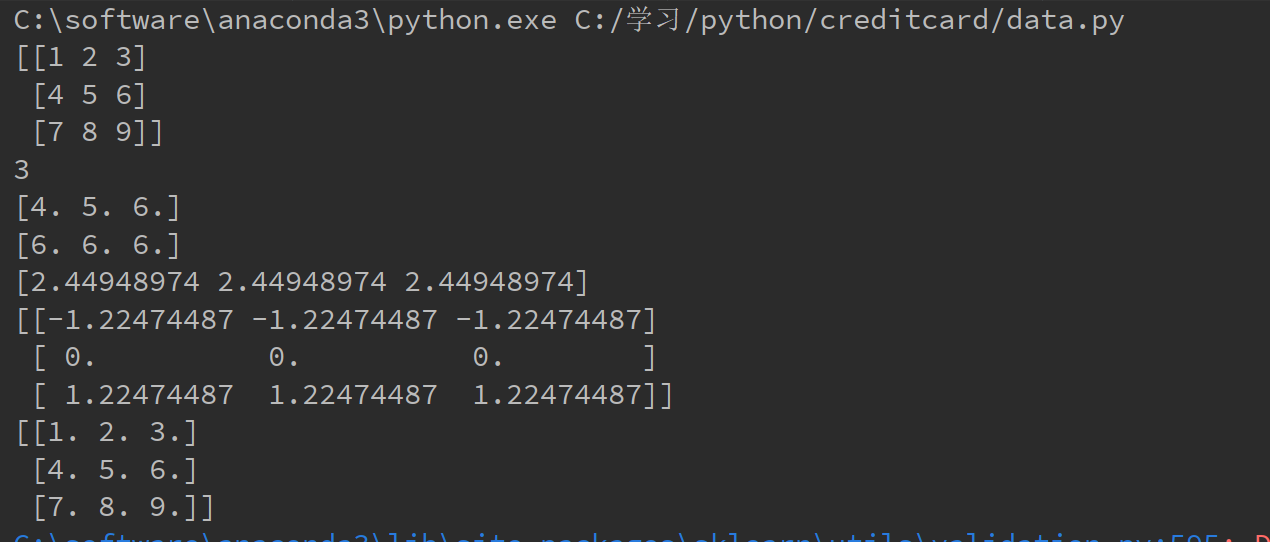
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler
#data = pd.read_csv("C:/学习/python/creditcard/creditcard.csv")
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]).reshape((3, 3))
ss = StandardScaler()
print(x)
ss.fit(X=x)
print(ss.n_samples_seen_)
print(ss.mean_)
print(ss.var_)
print(ss.scale_)
y = ss.fit_transform(x)
print(y)
z = ss.inverse_transform(y)
print(z)
运行结果为:
能够被调用的Methods:
fit(X,y=None):计算输入数据各特征的平均值,标准差以及之后的缩放系数 ,以后就可以按照这个数据调用transofrm()
X:训练集
y: 传入为了使得和Pipeline兼容
fit_transform(X,y=None,**fit_params): 通过fit_params调整数据X,y得到一个调整后的X ,使得每个特征的数据分布平均值为0,方差为1
X 为array:训练集
y 为标签
返回一个改变后的X
get_params(deep=True): 返回StandardScaler对象的设置参数,
inverse_transform(X,copy=None):顾名思义,就是按照缩放规律反向还原当前数据
transform(X, y=’deprecated’, copy=None):基于现有的对象规则,标准化新的参数
可以认为fit_transform()是fit()和transform()的合体。
sklearn.preprocessing.StandardScaler数据标准化的更多相关文章
- sklearn.preprocessing.StandardScaler 离线使用 不使用pickle如何做
Having said that, you can query sklearn.preprocessing.StandardScaler for the fit parameters: scale_ ...
- sklearn preprocessing data(数据预处理)
参考: http://scikit-learn.org/stable/modules/preprocessing.html
- Python数据预处理(sklearn.preprocessing)—归一化(MinMaxScaler),标准化(StandardScaler),正则化(Normalizer, normalize)
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常 ...
- 数据规范化——sklearn.preprocessing
sklearn实现---归类为5大类 sklearn.preprocessing.scale()(最常用,易受异常值影响) sklearn.preprocessing.StandardScaler() ...
- sklearn中的数据预处理----good!! 标准化 归一化 在何时使用
RESCALING attribute data to values to scale the range in [0, 1] or [−1, 1] is useful for the optimiz ...
- sklearn preprocessing (预处理)
预处理的几种方法:标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 知识回顾: p-范数:先算绝对值的p次方,再求和,再开p次方. 数据标准化:尽量将数据转化为均值为0,方差为1的数 ...
- sklearn中常用数据预处理方法
1. 标准化(Standardization or Mean Removal and Variance Scaling) 变换后各维特征有0均值,单位方差.也叫z-score规范化(零均值规范化).计 ...
- 11.sklearn.preprocessing.LabelEncoder的作用
In [5]: from sklearn import preprocessing ...: le =preprocessing.LabelEncoder() ...: le.fit(["p ...
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
随机推荐
- Kattis - itsamodmodmodmodworld It's a Mod, Mod, Mod, Mod World (类欧几里得)
题意:计算$\sum\limits_{i=1}^n[(p{\cdot }i)\bmod{q}]$ 类欧模板题,首先作转化$\sum\limits_{i=1}^n[(p{\cdot}i)\bmod{q} ...
- tp5中的return
return 可以输出对象,但是不可以输出数组 class Index { public function index(Student $student) { $data = $student-> ...
- 将TextEdit设置为密码框
属性--Properties--UseSystemPasswordChar设置为true
- 关于system.timer的使用
private System.Timers.Timer _timer = null; if (_timer == null) { _timer = new System.Timers.Timer(); ...
- C#创建泛型类T的实例的三种方法
原文链接:https://www.cnblogs.com/lxhbky/p/6020612.html 方法一,通过外部方法传入的实例来实例化: //泛型类: public class MySQLHel ...
- 交叉熵和softmax
深度学习分类问题结尾就是softmax,损失函数是交叉熵,本质就是极大似然...
- VS2015安装QT插件
下载安装完后直接重新启动vs
- C# 5.0
序言 异步成员 但是 async 和 await 才是此版本真正的主角. C# 在 2012 年推出这些功能时,将异步引入语言作为最重要的组成部分,另现状大为改观. 如果你以前处理过冗长的运行操作以及 ...
- QT5 Even 事件
事件的引入: 实现功能: 1.点击button 文本框两字改变成button被按下;很简单的在button上转到槽对lineEdit->setTest()设置即可; void myWidget: ...
- javascript中的原型和原型链(三)
1. 图解原型链 1.1 “铁三角关系”(重点) function Person() {}; var p = new Person(); 这个图描述了构造函数,实例对象和原型三者之间的关系,是原型链的 ...